












































































312
127
包子教你机器学习 篇二:大数据处理的基本思路
2018-03-11 18:45:34
13点赞
180收藏
18评论

注意!本系列文章只是写了玩玩,想要学东西的快去看书,想要看代码的去GitHub,而不是盯着我这些所谓的教程,本系列文章只是为了写一写碎片化的介绍!上来就说不如哪个大神的评论就不要写了,我都说了我只是萌新。你们也不想想,真正的大神都去花时间赚钱了,哪有时间过来写这样的文章。
接着上一篇,我写了一些关于机器学习的基本概念,其中有一些东西也没有展开讲,只是讲故事一样说了两句。这篇我将开始讲一下有关数据处理的基本套路,而有些套路是你曾学过的,当然我这里只是给你简单介绍一下。
在开始之前,我还是先扯一下前几天的新闻,大数据杀熟那个新闻,说的是一个小伙子出差订房间的时候刷了一下页面发现便宜了几十块,然后退了再订的时候发现没房间了!!当他拿起来别人的手机查的时候发现这个房间还有并且价格更低!!另外一个新闻就是一个经常订外卖的人跟同事一起订外卖的时候发现别人的配送费比他还便宜好多,然而他们订的都是同一家店以及送到同一家公司。这些事情简单来说就是应用你在互联网上暴露的各种信息来分析你的消费趋势然后做出价格歧视,你订的多别人就给你把价格提高一些,你用得少别人就把你的价格降低一些。所以,给大家的建议是定时更换服务商,岔开使用,尽可能减少信息暴露吧。大数据时代大家都是棋子。

扯完以上废话,我就要开始说一下机器学习基本思路了,而正如第一篇提到的,大数据实际上就是统计学的应用,只不过以前是人类分析数据,现在是程序分析数据。既然是统计学的应用,那么现在要讲的肯定就是有关统计学的东西,但又与统计学有一点不一样。
在统计学中有以下几个关键词:容量、过拟合、欠拟合、估计、偏差和方差、最大似然估计等等。这些关键词我会在后面一一介绍一下。
------------------------------------------正文-------------------------------------------------------------------
机器学习的主要挑战就是训练出来的程序能够在未知的数据上的预测足够准确。在训练过程中机器学习的目标是降低训练误差,而在我们测试这个程序的时候目标是降低测试误差,所以判断一个机器学习算法效果优劣的标准就是:降低训练误差和缩小训练误差和测试误差的差距。所以这里就涉及到欠拟合和过拟合,欠拟合是指在训练数据中不能得到我们想要的低误差,比如你只给了三瓶饮料给程序,可乐雪碧芬达各一瓶,然后程序训练时候按照的分类标准是颜色分类,那么在这里程序能够完全分类,同时测试数据里面因为也只有三种颜色并且三种颜色恰好对应的是相应的饮料,等你拿出来放在小店里面使用时候就会出现很多差错,比如雪碧是透明的,水也是透明的,程序训练时候分类出来的是只要是透明的就是雪碧,但是别人客人拿的是水。这就是在未知环境里预测能力不足的表现。而过拟合则是指的训练误差和测试误差之间的差距太大,比如还是饮料例子,训练时候根据已有的三种饮料分类很成功,但是测试数据里增加了可口可乐和百事可乐两种分类,也增加了维C和矿泉水两种,这时候程序分类一定会出错,但是你设计的算法决定了这个程序到底是把两种可乐细分还是分到一起去,或者把维c分到芬达里面去把矿泉水分到雪碧里面去还是把它们俩做成单独的未知列列出来等待新的分类。

因此,在训练拟合的基础上,我们关注的是容量。从字面意思就可以看出,容量指的是训练数据的质量和数量。意思是,你训练程序分类饮料的时候,你知道有一二十种饮料,但是提供的数据全部都是可乐的数据,这样的数据一万个和一个都没有什么区别。而你提供了一万瓶饮料但是每一瓶都不一样,这意味着每个数据都只有一个点,根本无法找出来合适的数据来分析相同点与不同点,这也没什么用处。所以,容量要匹配任务的复杂度,你想要详细分类每一个饮料的数据,根据它的颜色、饮料升数、瓶子长短之类的方面分类时,你需要做的就是把所有的饮料的详细数据全部标出来给程序学习,但是当你只需要分一下饮料和矿泉水的差异的时候,你所需要的也只是降低数据量,给程序知道水和饮料的差异。当然,对于训练来说,不存在数据量越多越好,这里有一个最佳容量的平衡点,在这个点上,程序训练的效率最高。

但是,以上的训练,总不是完全可靠的。在新的数据分析上,没有算法能够保证自己训练出来的规则能够完美描述新的预测点。也就是说,从逻辑上讲,一组有限的数据分析出来的规律,在新的未知的数据上的推测是有误差的,并且这个误差一定会存在。这一点,在函数拟合上面表现尤为突出,就是你有一长串数据,你根据这个数据做了一个二次或者三次函数的拟合,然后推测下一步数据会在哪里,然而你不可能说我根据这个函数推测出来的就是完全准确的,你只能说我推测出来的数据是在哪个范围内。


更重要的是,在所有能用的算法上,训练结束之后它们在一个未知数据点上的推测都有着相同的错误率。这一点可能很难理解,因为有些推测肯定是符合趋势的,有些推测肯定是不符合的。但是你要知道,这里的错误率,指的是所有推测出来的数据上的平均分布。举个例子,你写了一个程序给你推荐撩妹诗句,这个程序一共有ABCD四种算法推荐,然后你在正式撩妹过程中,ABCD都会给你推荐不同的诗句,有的是符合场景的,有的不是。然后在你未来十亿年的撩妹过程中,ABCD四个程序分别给你推荐了十亿诗句(假设一年撩妹一个吧),然后有的诗句能够表现出你文青的浪漫,有的则是213的傻。在整个十亿数量级上,你会发现不同的算法之间的浪漫诗句推荐和213推荐之间的比例是趋于相同的。这就是说在所有可能的数据生成分布平均之后,每一个算法在未观测点上都会有相同的错误率,所以基于这个点来说,没有一个算法是天然的比别的算法都要优秀的,因为在未来可能的任务上,他们的平均出错率都是相同的。
看到这里是不是觉得非常无聊?既然这样我们还去想怎样优化干啥?直接暴力破解啊!可是那只是理想情况,现实情况是我们计算能力有限,储存空间也有限。考虑到概率分布问题,我们可以设计在这些分布上效果更好的算法。
所以以上解释说明了什么?说明了机器学习的目标并不是选一能够解决无数问题的通用算法(就是又能让你学开车又能让你学撩妹的算法并不是机器学习的目标),也不是寻求一个绝对最好的算法(意味着你这个算法是最优解)。限于计算力和储存空间的限制,以及时间的限制,我们只能在已知的算法中找到一个相对高效的算法来训练程序。最优解的寻求成本已经大于它的效益的时候,我们会选择退而求其次。
基于以上的原则,我们必须要在指定的任务上设计一组学习算法,这些学习算法与任务方向相同时候,效率会爆表。比如说你要学撩妹,这时候你设计的算法是怎样分类饮料数量,那么久非常尴尬。但是换成自动搜索PUA相关关键词,自动整理文件的算法的话,就会好很多,当然最合适的还是你带个耳机让程序现场指导你反应。
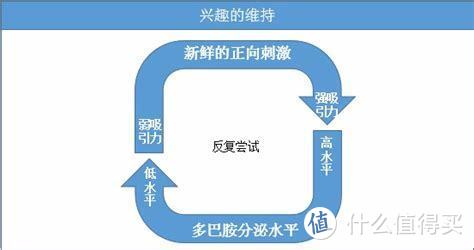
设计完算法之后,我们需要进行奖惩设计。这里用的术语叫做正则化,指的是通过修改学习算法来降低训练之后程序在未知数据上的误差而非降低训练时候的误差。这是机器学习的中心问题之一。比如在撩妹过程中,你在模拟撩妹时候非常好,比如遇到节假日时候程序可以自主给你做一个推荐,但是真的遇到撩妹场景的时候,程序就开始瞎推荐了。比如喝个奶茶,程序给你推荐一个“谁家玉笛暗飞声,散入春风满洛城”,你怕不是要回家就直接删掉程序。但是我们要做的是,让程序根据你的反馈,知道哪些推荐是可行的,哪些是不可行的。就是告诉程序你的偏好是什么,再把这个偏好做成正向奖励。其实也就跟多巴胺分泌差不多,你去繁衍后代了,大脑就开始分泌多巴胺,你去准备自杀,大脑就开始制止你。
我们怎样控制算法的行为呢?这里有一个词叫做超参数,就是机器学习模型里面的框架参数,比如聚类方法里面类的个数,或者话题模型里面话题的个数等等,都称为超参数。它们跟训练过程中学习的参数(权重)是不一样的,超参数通常是手工设定,不断试错调整,或者对一系列穷举出来的参数组合一通枚举(叫做网格搜索)。所以说,当一个参数设置为超参数时候,也就意味着它不需要程序学习过程中对于这个参数进行自我优化。比如说,你要撩妹,把中华上下五千年的历史诗词全部做成数据库来训练程序,你设置的按照朝代分类的参数就是超参数,你可以根据高中历史书的分类分为大朝代,也可以根据新华字典后面的朝代分类细分到年代。但是这一切都是你自己控制的,因为这些分类是程序在学习数据库的时候不可能接触到的,不会自主分类的。只有你才知道根据哪种方式分类比较适合你的现状。
如果在训练集上学习,那么超参数总是趋于最大容量而导致过拟合。所以为了平衡控制超参数,我们会设定一个算法不可能观测到的样本,称之为验证集。用于挑选超参数的集合称之为验证集。所以在整个训练样本中,八成是训练数据,两成用于验证集。通常来说,验证集的误差会小于训练集的误差。也就是说,你去撩妹的时候,你的诗句数据库被分为两部分,一部分是给程序学习的,一部分是用于进行朝代分类的,于是当你碰到喜欢宋词的妹子的时候程序需要及时给你推送合适的宋词,遇到喜欢唐诗的妹子时候需要及时推送唐诗。而你用朝代分类的词来做标签的时候,程序需要根据这些标签来自主把数据库里的诗词都分类出来打上不同朝代的标签,当然这个工作人工也能做,但是交给程序做会节约大量的时间精力。

当数据被分为训练集和固定的测试集之后,测试集的误差过小也是一个问题。因为这意味着在大尺度上的平均测试误差有更高的统计不确定性,继而很难判断不同算法之间在特定任务上的优劣性。所以我们会做一个事情叫做交叉验证。从字面意思上理解,这个验证是通过基于原始数据上随机采样得出的不同数据集来进行重复训练与测试。当然你可能觉得这样有什么效果吗?当然是有效果的,想想自己,当自己在高中时期老师让读完数学课本,然后拿着数学课本上的题来考的时候都会有人不会做,特别是高三总复习那段时期,随机组合的不同板块的测试都能让你紧张。有的人怎么考都可以,这就是优秀的算法A,有的人单独学习时候可以,综合起来考试就有点懵,这就是一般算法B,有的人说是看了书,但是一到考试就懵,这就是不好的算法C。这里最常见的就是k-折交叉验证过程,就是说把整个数据分为k个不重合的子集,测试误差就可以预估为k次计算之后的平均误差。那么第i次测试的时候,数据的第i个子集就用于测试集,其余数据用于训练集。这样的操作带来的好处就是每次都会采用不同的训练集和测试集,保证数据的充分利用。
在以上的基础上,剩下的就是统计学内容,估计、偏差和方差了。此处就不说了。
介绍了一下基本的数据训练思路,下一篇将会说一下,监督学习算法、无监督学习算法以及怎样构建机器学习算法。
PS:开始学习机器学习的时候才发现,数学基础决定了自己的上限,而数学天赋决定了自己的学习进度。想起来以前经常有人说学数学有什么用,买菜又用不到函数,开个车也不用会三角函数啊。现在的问题是,不要求自己有多么高深的数学基础,不会数学,也不愿意学英语,就只能用别人剩下的轮子,还得看别人脸色。学点程序,能够更好的帮助自己节约时间,有些事情真的写个脚本就能解决的。
注意!本系列文章只是写了玩玩,想要学东西的快去看书,想要看代码的去GitHub,而不是盯着我这些所谓的教程,本系列文章只是为了写一写碎片化的介绍!上来就说不如哪个大神的评论就不要写了,我都说了我只是萌新。你们也不想想,真正的大神都去花时间赚钱了,哪有时间过来写这样的文章。(为了防止有人看不到,我在尾部再复制粘贴一次)
















张大妈的干儿子
校验提示文案
kxbs
校验提示文案
大阪友
校验提示文案
sjzsnow
校验提示文案
三点省略号
校验提示文案
dinolegic
校验提示文案
hobit
校验提示文案
椰子汁儿
校验提示文案
土豆x
校验提示文案
呆萌的呆呆
校验提示文案
呆萌的呆呆
校验提示文案
土豆x
校验提示文案
椰子汁儿
校验提示文案
hobit
校验提示文案
张大妈的干儿子
校验提示文案
dinolegic
校验提示文案
三点省略号
校验提示文案
sjzsnow
校验提示文案
大阪友
校验提示文案
kxbs
校验提示文案