












































43
62
自建Superset数据可视化平台并创建疫情地图网站(下)
2020-03-09 21:40:55
14点赞
111收藏
20评论
上半部分的文章,主要介绍了Superset在macOS docker下的安装以及Superset的一些功能介绍,我写这篇文章的目的,无非是记录了如何去实现图形化的学习过程,期间对superset的摸索,希望给大家介绍。
文章中有所不足,因为并没有连接实时数据库等,当然Superset本身是支持的,我也还在摸索当中,看看是否能够对接一些数据接口,现在只是先把自己所了解基本操作分享出来。
根据之前的目录,我们剩下的是关于此次疫情作为案例的一个分析。如果需要了解上半部分的,请跳转至mac 篇三:自建Superset数据可视化平台并创建疫情地图网站(上)
macOS docker
Superset安装
创建admin账号
基本使用(功能介绍)
基本使用-csv上传
基本使用-数据库连接
案例-新冠肺炎可视化分析设置
基本使用-数据清理及格式
基本使用-可视化
基本使用-Dashboard
传了一晚上视频,终于在b站审核通过了。大家先看一下视频吧。
案例-新冠肺炎可视化分析设置
(以下部分图片因为markdown转化失败所以从张大妈上传,预览看起来压缩比较厉害,不过都有文字说明了)
本来我其实是想把数据清理,可视化,以及生成Dashboard分开来讲,最终再拿疫情数据来分析的。但写着写着,觉得还是,边拿数据做分析,边讲过程会更加让人易懂。
数据清理
当我们拿到一份数据的时候,往往我们并不知道自己到底要展现什么东西。特别是当我们拿到的是原始数据,其中可能包含了各种各样的字段。这些字段是否有用,需要看我们到底想要在可视化中看到哪些内容。
数据分析的最大方向是需求的驱动,举个简单的例子,如果说,给你一份公司报销清单的原始数据
希望你能通过分析这些数据找出异常的报销,你需要做的是什么?通过类目总计,单项总计等方式,你需要手动整理一份相对正常的报销平均水平,以此为阀值,找出高于某些阀值的数据,最终展现的是对此类数据进行更加深入的分析。
换一个角度,如果希望通过这份数据,需要找出cost saving方向呢?最终展现的内容就又会发生改变。 你可能只需要分类展现各种报销类型按不同时间维度的百分图,之后的工作侧重点则是根据实际的业务情况来分析这些数据,事实上已经完全脱离了这份数据。
我们在获得一份数据,进行整理是需要考虑清楚一下内容:
你最终想看到什么?暨,你的需求是什么?
现有的数据是否缺少你想要的字段?你是否需要补充内容?
数据样本中,无效数据占据了多少?
接下来,我们就去获取一下信息样本的数据。 我用来做疫情地图的数据源于github一个爬虫项目,他会定去去抓去丁香医生的疫情数据信息。链接在此
现有可以下载到的数据已经非常好了。可以看到数据分成了3个纬度,国家,省,城市,并且提供了相应的城市及国家代码。以及每天的合计疑似,死亡,治愈人数。 相比我之前拿到手的抓取数据,每天不定时抓取,一天抓取太多,导致我只能手动删除,只保留每天各省份只留一条数据。

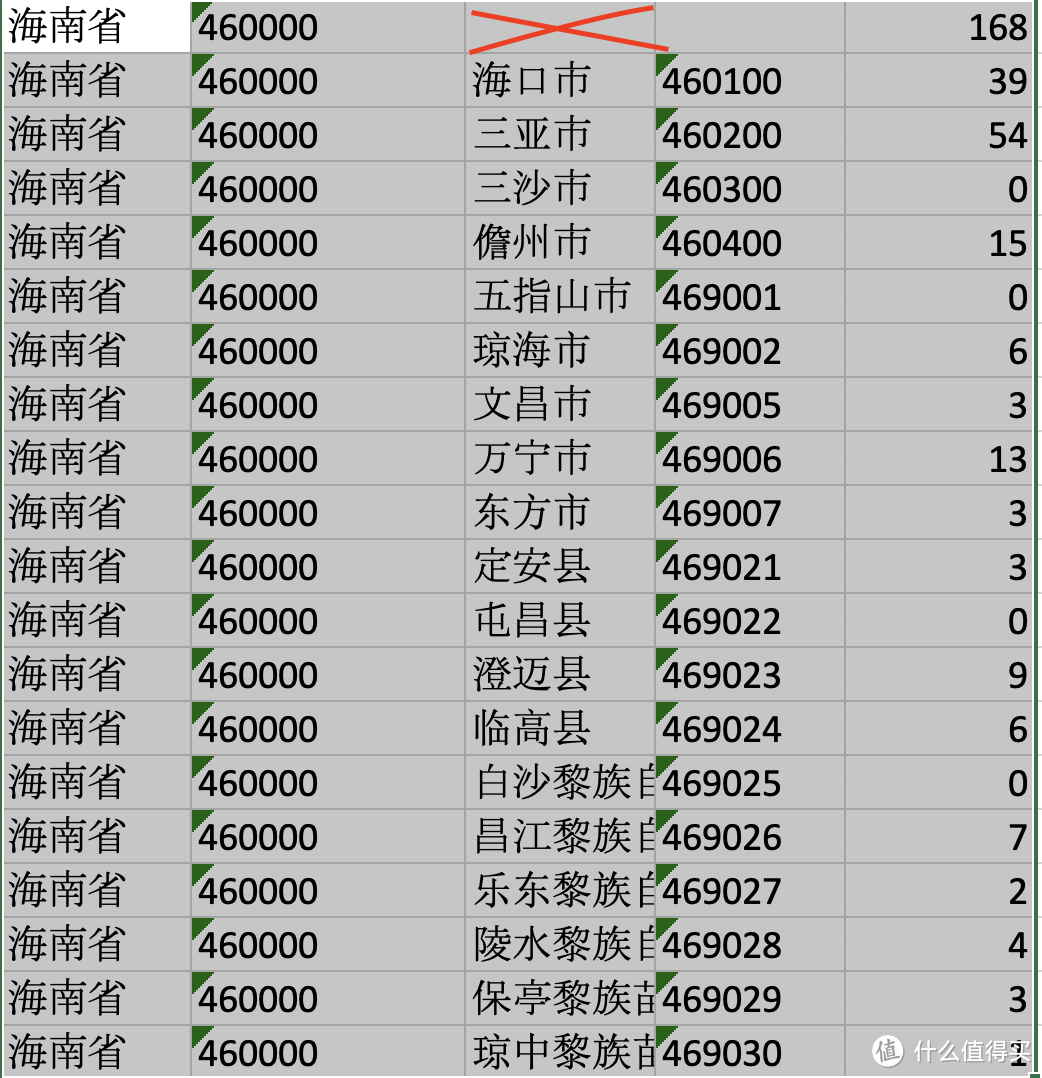
这份数据是否能够直接在superset的地图中直接使用呢?回答是不能,因为superset的地图并没有使用中国国家统计局代码, 所以我们需要添加一个字段。这个字段是ISO3316标准下的中国省份代码。
 3316
3316
通过vlookup,我们可以将这部分信息插入现有的疫情数据当中。 修改完成后的数据字段就是这样的。
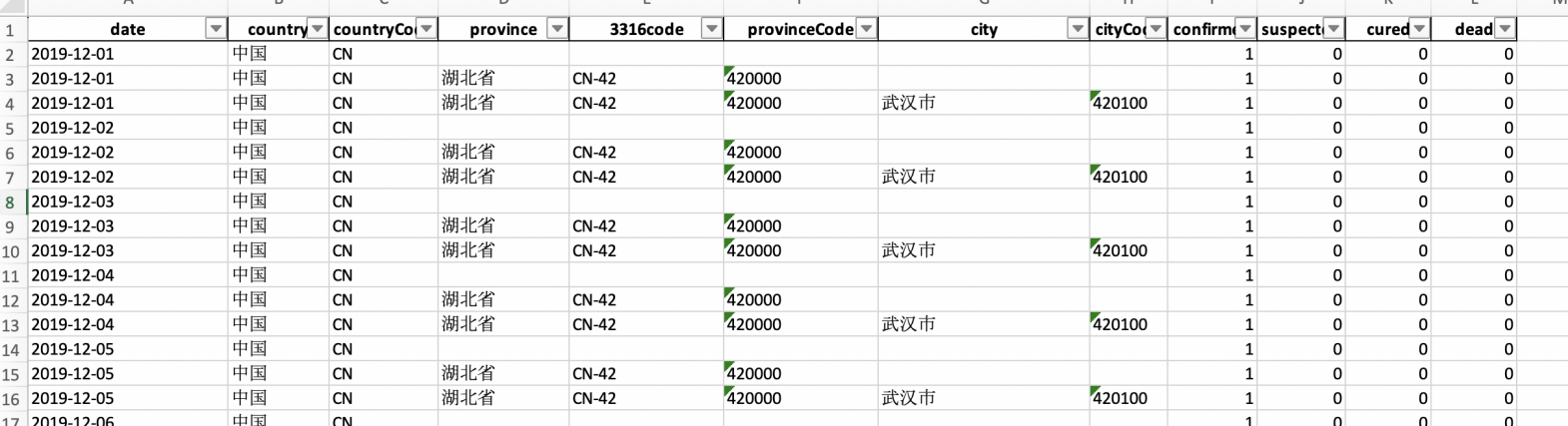 data
data
接下来将表格导出为utf-csv,就可以准备导入superset了。
Sources-Upload a CSV
 upload
upload
当上传完成后,准备工作还没有结束,因为csv的上传,导致了大部分的字段(数据)并没有被定义为准确的类型,superset不知道哪个是数据,哪个是时间,又有哪条数据可以被分类。所以我们需要整理这些数据的类型。
看到红框中的红框了么,点击这支小笔。 修改这张表的各项属性。
每张表分为3个tab
Details,一般这里我就改一个offset,设置为8,代表0+8东八区时间点。
List mertics,你可以提前预设一些数据过滤,如果没有必要,就不用设置,一般我不做设置
List Columns,这个非常重要,我需要进去修改数据的属性, groupable,是否可以分组,filterable,是否可以分类,is temporal,是否是时间参数。
我们首先要把时间的type修改为timestamp(或者date)
把所有的字段的groupable,filterable都勾上,至于is temporal,我们只需要勾选date这个字段。如下图
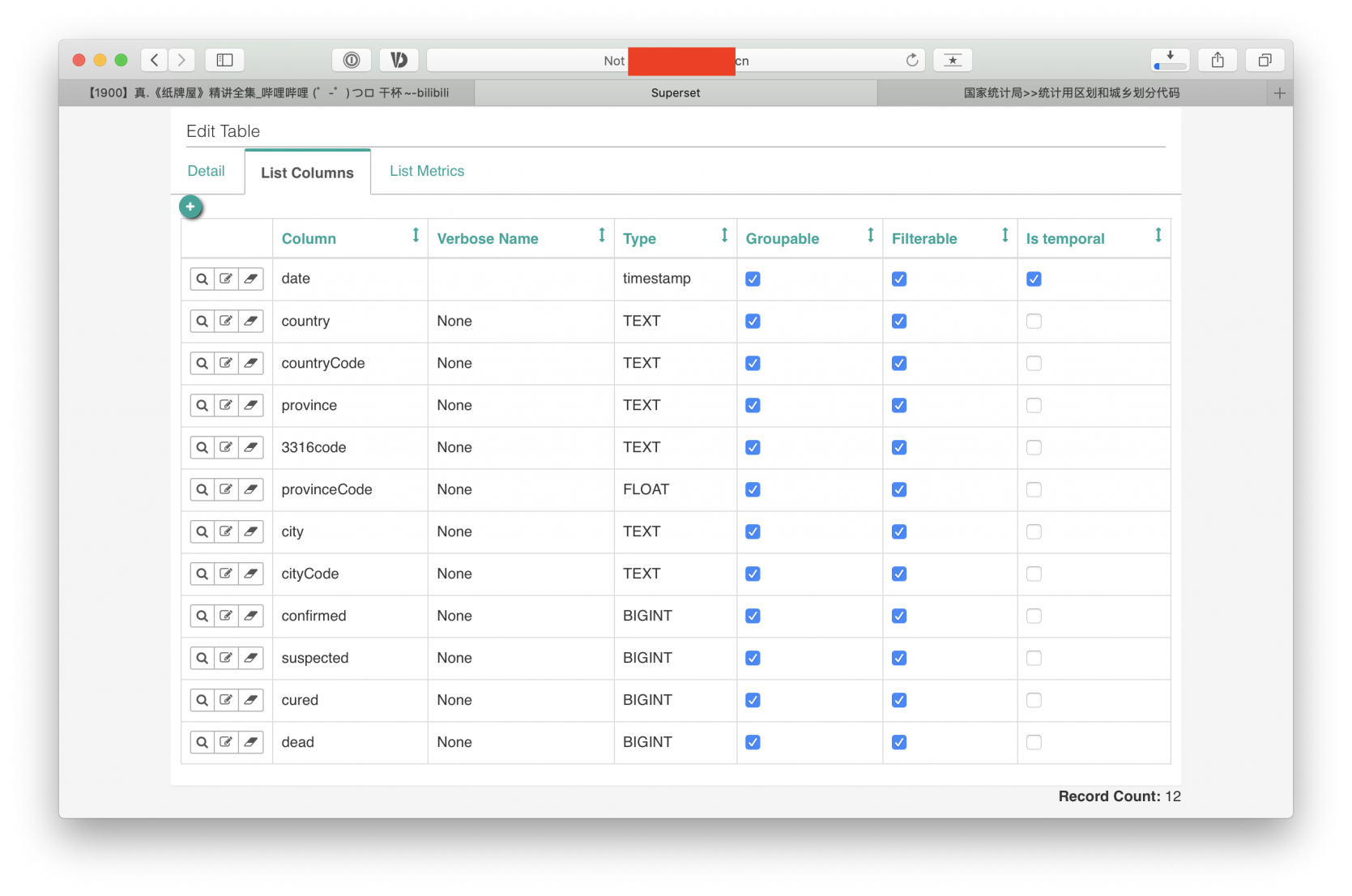 data type
data type
至此,数据清晰,和相关整理工作已经好了。接下来我们就可以进入到数据分析环节了。
基本使用-可视化
可视化,其实就是通过现有的数据,去创造一个Chart。
Sources-Tables,选择我们刚刚上传的ConV,我们就进入了可以创建图表的界面了。 当我们进入表的时候,是一个默认未经过数据筛选的空白界面,实际上是一个count计算,直接计算了总计的字段。 先通过下图解释一下相关的选择。
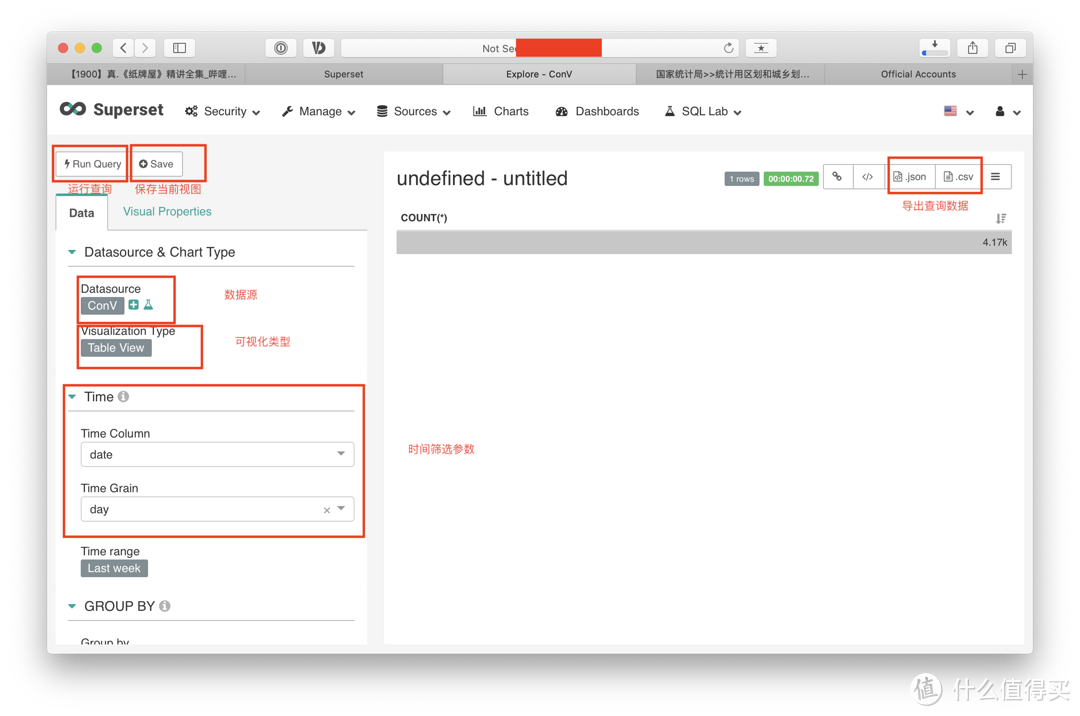
接下来,我们就考虑一下,我们需要用哪一种方式来展示数据了,第一考虑的点。我觉得可能是疫情地图时图模式。 那么我们就开始建立第一个视图模式
地图视图
选择visualization type,选择视图类型为map,map有很多中,这里我们先选择country map。
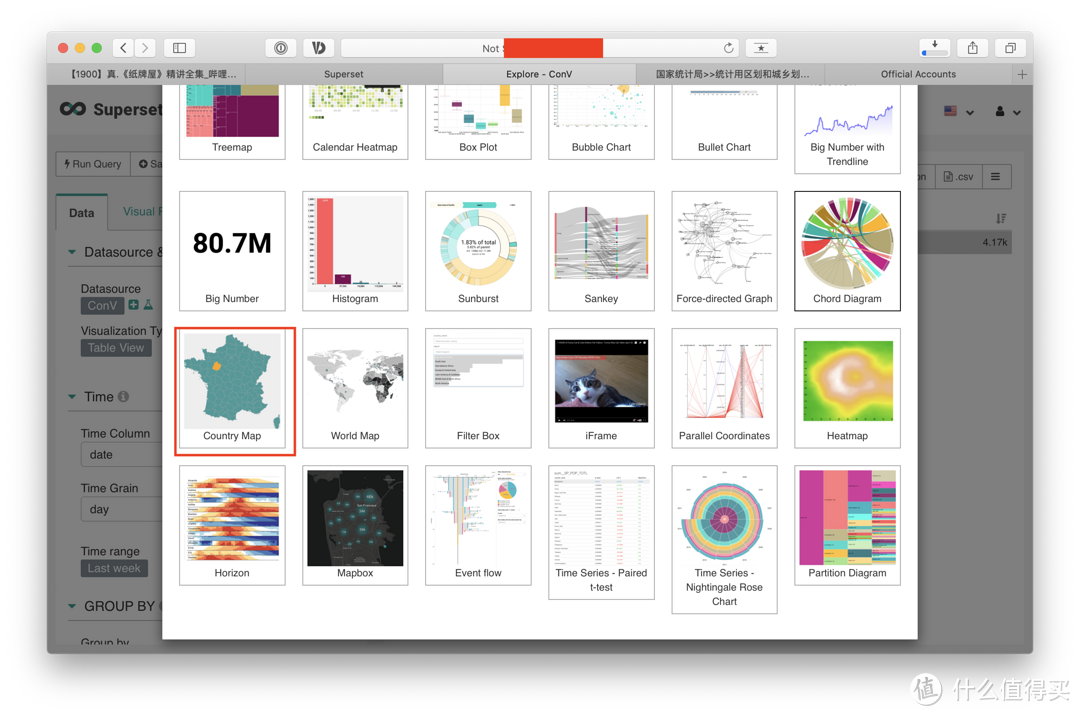
我们来讲一下country map视图中需要进行设置的参数,先看一下图:
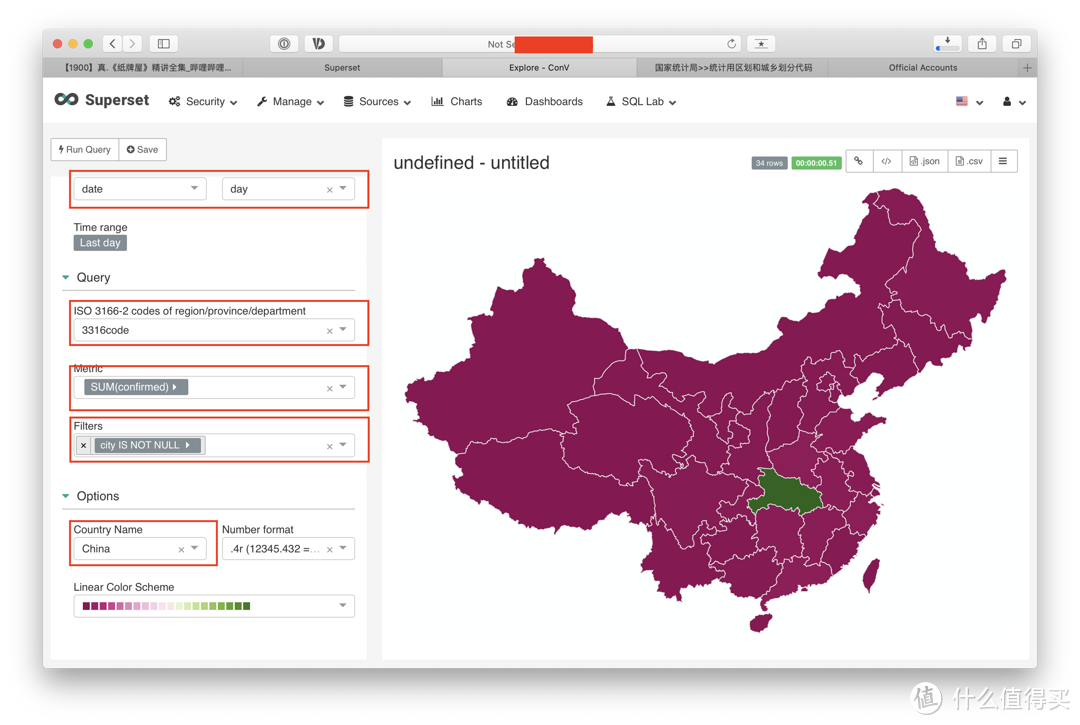
这张图看起来是不是没啥意思,那是因为我们的数据中并没有每日增长的人数(当然你可以手动添加数据,通过当日数据减去昨日数据,得出每日增长数据)。所有的数据全是合计数据,所以这张图上的湖北是整个疫情期间确诊的合集数值67,710人。
我们先讲一下得出这张地图的设置:
日期设置,请记住,在地图视图上是不存在时间点的分布的,所以我们选择time range为last day,只看最近一天的统计数据
3316-2数据,country视图,抱歉,我之前打错了,ISO3316为标准国家及城市代码,其中ISO3316-2-cn为中国省份代码, 所以这个选项,我们选择了我们之前在清理数据时手动增加的字段,也就是3316code这个字段(我打错了的)
metric,关键衡量指标,在这张地图中,我们的关键衡量指标时确诊人数,我们使用的是合计,当然,如果光使用合计也就是sum(confiremd),我们会发现,它会重复计算。因为在我们的数据当中,有统计的国家数据,统计的省份数据。所以我们必须要加入另一个功能。
filter,通过使用filter,我们可以避免重复计算。 因为我们需要的数据是每个省份的数据,所以我们可以sum(每个城市的数据)。 通过观察原始数据,我们找到了,最简单的方式去识别哪些是我们需要它去计算的。合计所有城市名称为空的值即可,所以filter(city is not null)
实际上的动态效果如何呢?我录了一个gif给大家看一下。
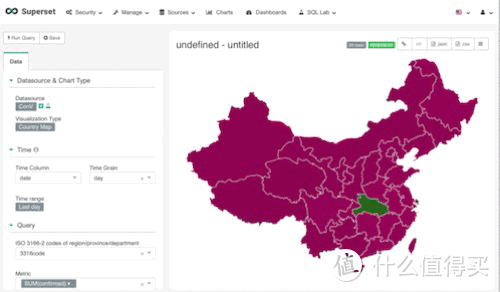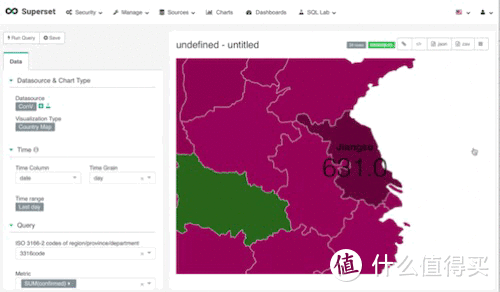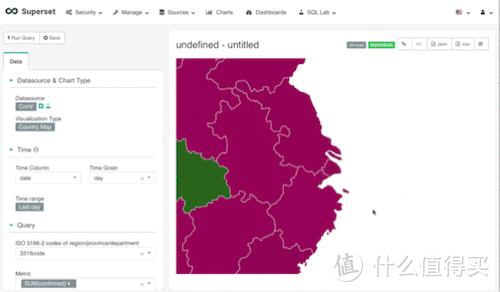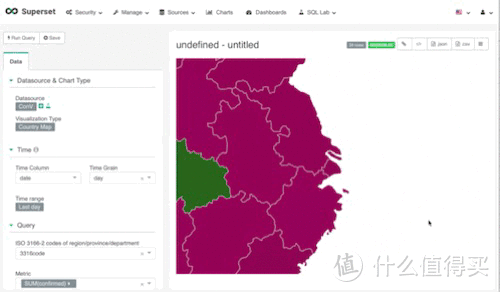
接下来,线保存这个视图。保存方式很简单,点击save即可,记得命名。我们可以先不将它添加到dashboard,之后操作。
 save
save
然后我们依然按照这个模式建设全球疫情地图。
world map的关键设置指标
country code设置为我们现有表中country code
参考的标准,选择cca2
metrics依然是confirmed(当然你也可以做出死亡的人数统计,或是治愈的人数统计)
filter 还是一个非常重要的功能,为了避免重复计算,通过观察原始数据我们发现,我们需要的country数据,在省份这里是空值,所以filter(province is null)即可
world map因为屏幕问题,显示上有点挫,未能全部显示,但是还是看的到,虽然美国地图出现了问题,但还是可以看到数据的,445名感染者。(cca的地图在国际标号上好像有一个很大的问题,如果作为公开展示来使用的,我建议大家注意地图中存在缺失情况,所以这里不放图了。)
疫情地图视图基本上内容就到这,你可以通过对原始数据的加减计算,分组组合等方式,做出每日增长地图等等的地图。 但疫情地图虽然看起来清晰,并不能反映太多的信息。 接下来,我们来讲一下多维度时间线地图。
多维度时间线地图
如果说,要看趋势情况,最适合的其实是时间折线,其实这个东西用excel也能做,不过相对来说,superset实现的视图效果更好。
先看一下效果图:
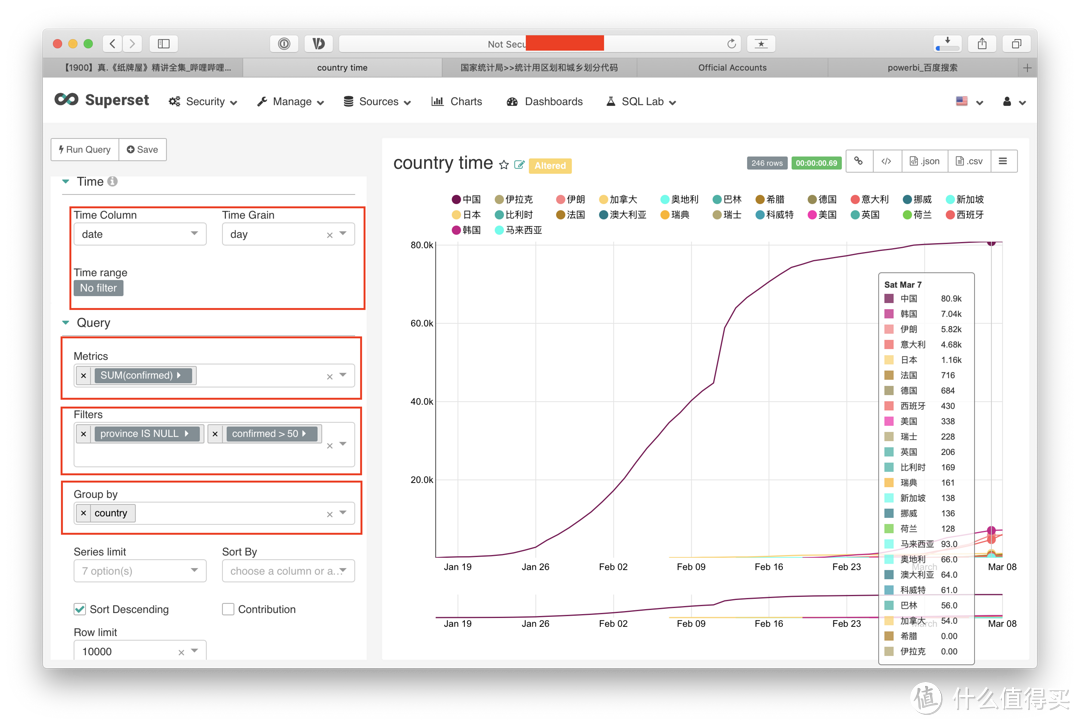
时间折线的具体参数如下来,我们先来描述一下我们需要的图查看从12月1日到3月7日之间,全球范围内各个国家大于50的确证人数,为什么要设置大于50,因为如果不做限制,那这张根本没法看,动态数据条根本看不全。根据这句话,我们对时间参数做了以下设置:
时间设置,颗粒度为day,时间区间为我们所有的数据量
metrics 关键指标合计数为确诊人数,当然,你也可以加上疑似,死亡,治愈。但那样的数据会显得非常多。 需要根据所查看的不同维度选择,比如,仅查看一个国家的数据,你可以讲所有信息都展现出来
filter, 同样,以国家为单位,我们只需要那些没有省份信息的合计数据, 另外一个,则是>50数值限制
group,就是分类,按照我们的话,需要各个国家的,数据,所以匪类就是country字段。
现在,你可以根据这个情况,画出国内的时间折线图了,注意计算省份的时候,filter掉重复计算的值。
Sunbrust
这个可能是我最喜欢的可视化形势了,因为他可以帮助你从大的层面上发现问题,然后逐层深入。
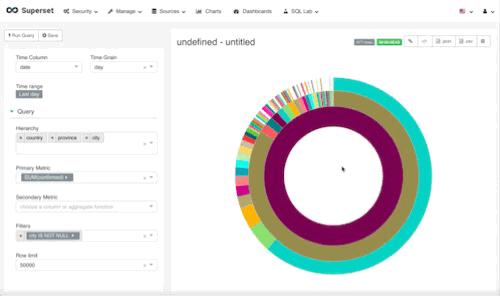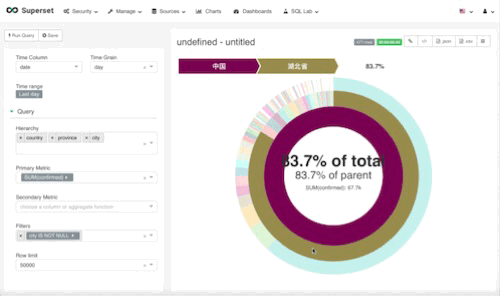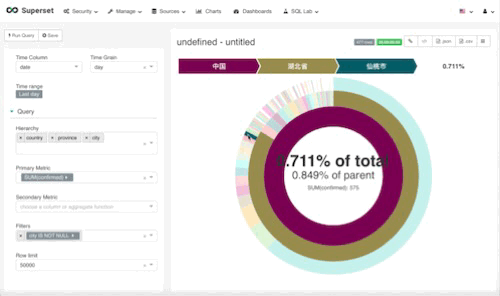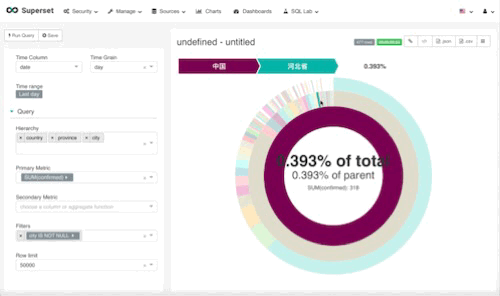
我们暂且叫它日环吧。还是一样,先用一句话总结我们想到什么东西我想从一张图里面看到现在国内所有的患者总数,各省份的患者总数和占比,以及各个城市的情况
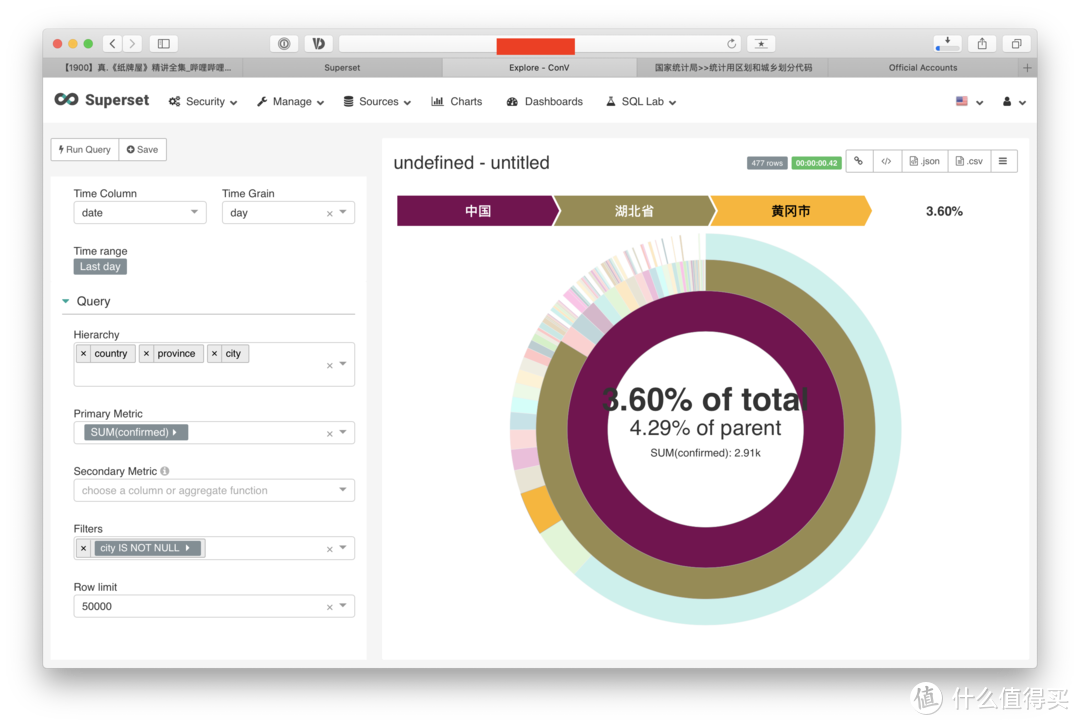
就是这样, 我们解释一下配置参数吧。
time,和地图视图一样,这种视图没有时间概念,所以time range一定得选择昨天,否则就会重复计算
hierarchy,层次,我们希望看到国家层面,各省层面,城市层面。所以依次把数据输入进去
primary metric,主要参数,我们依然设定为确诊人数合计
second metric,取决你想看到多少数据,你可以加入cured这个字段或是别的。我留空了。
filters,排除无效的重复数据,也就是国家单独合计,省份单独合计,只要city这个字段不是空,那就行了。
实际效果如下:
 Image
Image
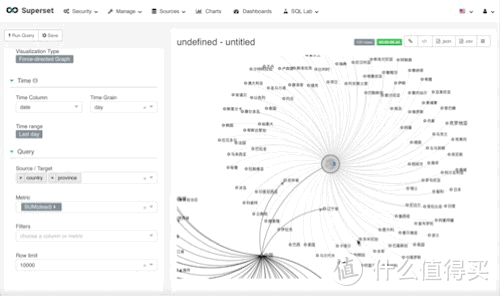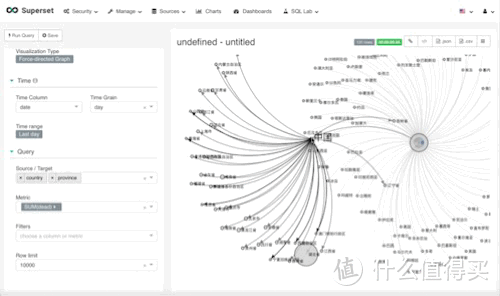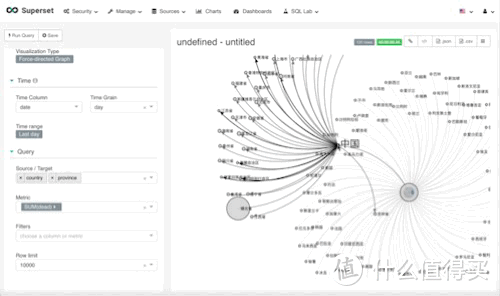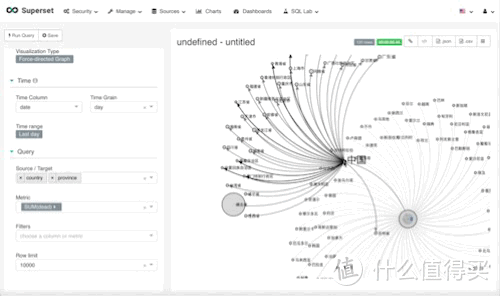
Force-directed展示
这个图的作用其实是互相关联数据,效果如下,我本来考虑的是,全球数据-分支各国数据-再分支各国各省份数据-各省份下的城市数据。 但是我发现数据量太大,看起来就是密密麻麻的线,不太适合我这台小thinkpad 430黑苹果。所以,就两层,国家-省份。
参数设置
source-target, 和上面的图其实一样,是一个层级,选择,country,province
metric,这次我用的是dead
superset预制了大量的视图模式,在这里就不会一个个讲完,其他的视图模式,可以自己尝试。接下来就改进入到最后的内容了,dashboard。
DASHBOARD
正如我之前说的,BI的精髓就是dashboard了,我们之前做了很多charts层级的东西,那么接下来,我们需要将刚刚创建的chart组合起来。
进入charts选项,任意打开一个刚刚创建的charts,选择保存到一个新的dashboard。
通过将所有的内容合并到dashboard中,我们就可以得到以下的一个总览视图。
Dashboard可以做的事(可以说dashboard就是用最简单的办法创建一个网站)
添加markdown文本框(通过markdown插入图片,链接说明等)
添加网页标题
模块化组合charts
添加筛选工具,讲一下filter的功能,filter相当于在dashboard中简历一个筛选工具。它需要先建立一个单独的chart,还是选择我们的原始数据表,创建名为filter的视图,选择你想要在dashboard里面设置的filter类型(千万注意时间点,因为filter容易自带时间点)随后将filter添加到dashboard当中就可以了。
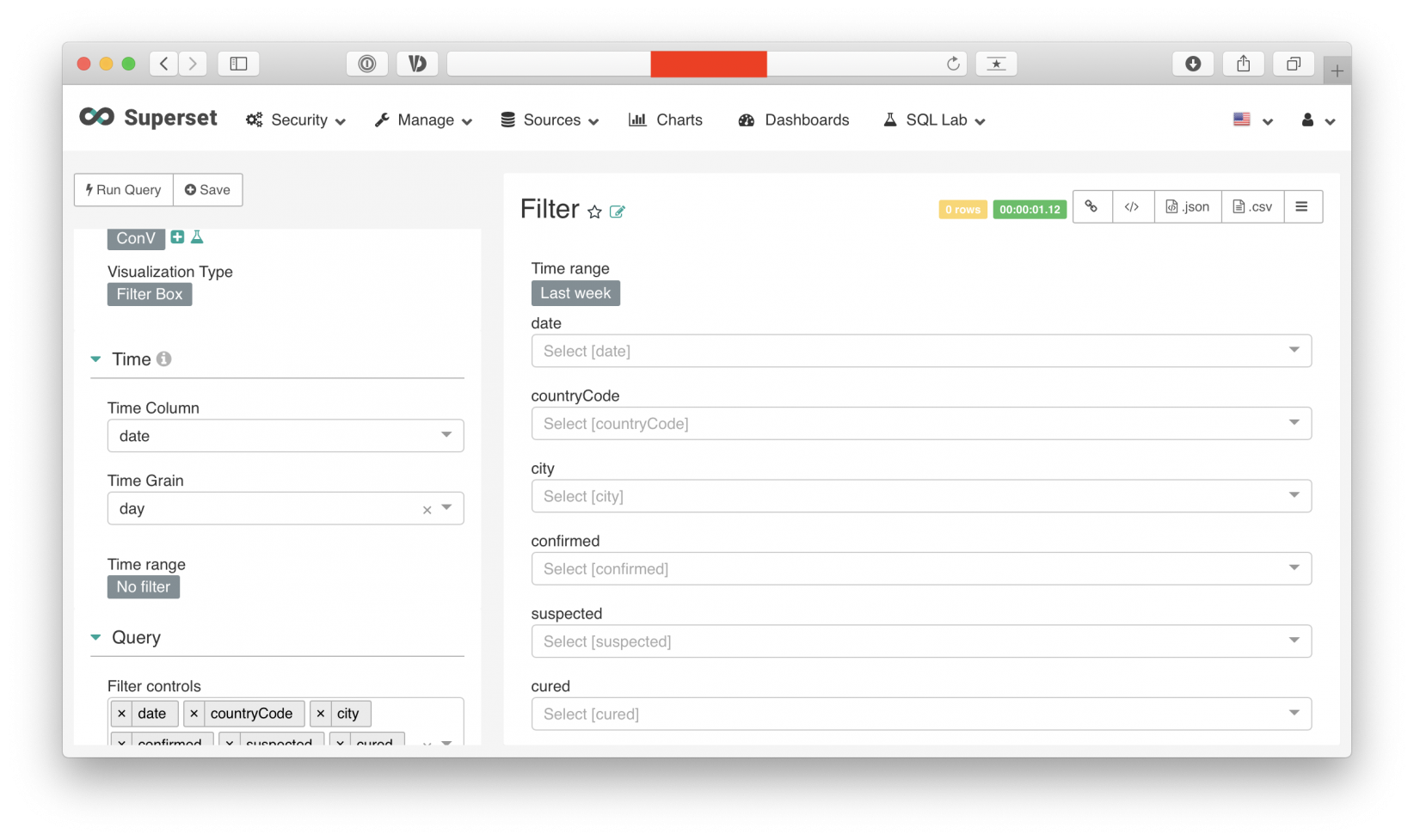 filter
filter
最终成型的样子大概如下:
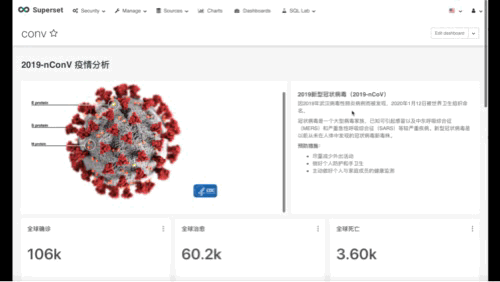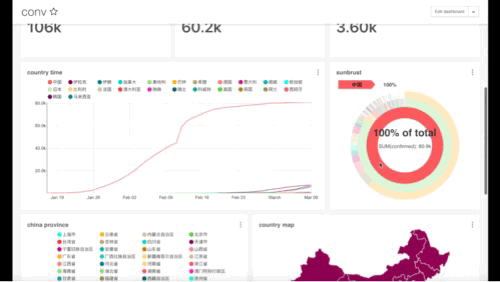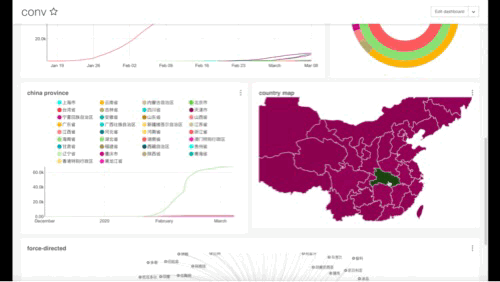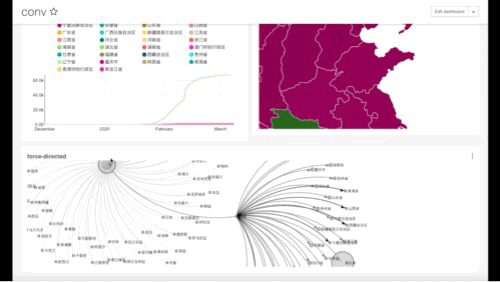 Image 4
Image 4

















小宝鸡
校验提示文案
tomy227
校验提示文案
帝国之星
校验提示文案
eyeopen
校验提示文案
seeyee
校验提示文案
我的名字叫恶徒
校验提示文案
值友1969748474
校验提示文案
shepherd_ryok
校验提示文案
吃饭不洗碗Felixzfb
校验提示文案
cocovslina
校验提示文案
licrosse
校验提示文案
值友6356562992
校验提示文案
值友6356562992
校验提示文案
值友6356562992
校验提示文案
值友6356562992
校验提示文案
licrosse
校验提示文案
cocovslina
校验提示文案
eyeopen
校验提示文案
seeyee
校验提示文案
吃饭不洗碗Felixzfb
校验提示文案
shepherd_ryok
校验提示文案
帝国之星
校验提示文案
tomy227
校验提示文案
值友1969748474
校验提示文案
我的名字叫恶徒
校验提示文案
小宝鸡
校验提示文案