



























































7
17
设计机器学习模型的通用过程总结
2020-10-01 10:41:07
1点赞
13收藏
4评论
人工智能依然这么火,我还是老老实实写下一篇吧。本篇要讲的东西实际上很简单,就是教你设计机器学习模型的通用步骤,在这里你可以用matlab去实现,可以用python去实现,甚至你可以用C去实现。举个反向传播的设计例子。
看懂这一篇,你要具备的基础知识是:线性代数增广矩阵部分,数值计算函数拟合部分,概率与统计的检验假设部分。
在看这些之前,建议先补一补前置课程。




在开始之前,我先说一下整个反向传播(BP)的思路,如果说你有数值计算的背景,你应该会很容易就理解反向传播说的是什么,它实际上就是假定我们能用函数去模拟一个过程,放在数值计算中,就是我们做拟合的过程。
比如如果我们要判断电子显微镜下拍出来的细胞照片是否有癌变的可能性,经验丰富的医生会告诉你,你要看细胞的各个参数,比如细胞外形,细胞颜色变化等等。放到我们数学上说,这就是参数,在本篇文章中,我们用到的细胞参数数量一共有10个。
先给出所有的步骤:多层感知机(MLP)为例子:
1.数据导入与清洗。
2.数据划分。
3.线性缩放。
4.矩阵增广。
5.重置分类标签。
6.初始化权重矩阵。
7.训练网络。
8.预测与分类。
1.数据导入与清洗。
在我们学习接触机器学习的时候,寻找特定的数据集是非常重要的事情,因为机器学习的理论很容易掌握,但是数据很难获得。所幸,网络上会有很多提供给初学者的数据集。比如这次我们会用到的是乳腺癌判断数据集,breast-cancer-Wisconsin.data。这些数据集在网络上可以自己下载下来,或者直接用python命令行导入程序中。
https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)
在导入数据之后,我们会看到一共12列数据,从左往右看,第一列是0到697的数字,很明显是编号,第二列是数据数字编号,这个可以忽略,第三到第11列就是我们需要的参数数据,第12列是2或者4的数字,代表每个样本是属于病变还是不属于病变。。整个来看,这是一个13X697的矩阵,每一行都是一条数据。
我们可以看到,这个数据源是非常规整的,但是里面也有缺失部分,用NaN代替。当然我们在处理缺失数据条的时候,有两种处理办法,一种是删掉这条数据,一种是用0代替它。
因为机器学习对于数据量的要求很高,所以当我们的数据量只有不到700条的时候,删除缺失数据就非常不好。所以我觉得用0代替是一个更加好的处理方式。
其实现在数据清洗也逐渐成为了一个职业,在有监督学习中,如何标注数据,以及标注足够数量的数据,依然还是用人来完成的。
2.数据划分。
当然,基于我们现在数据集很小的情况,我们需要采用特殊的统计学方法来充分利用起来数据集。这时候划分数据集就成了非常重要的事情。
为什么我们需要用小数据集进行划分呢?因为我们想要充分利用有限的数据集,找到合适的参数模型,但是又要防止过拟合。这时候,k折交叉验证(k-fold cross validation)与留出法(holdout cross validation)成了最通用的数据集划分方法。
交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现性能,也可在一定程度上减小过拟合。也能尽量从有限的数据中获得尽可能多的信息。
叉验证的目的:在实际训练中,模型通常对训练数据好,但是对训练数据之外的数据拟合程度差。用于评价模型的泛化能力,从而进行模型选择。
交叉验证的基本思想:把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set),首先用训练集对模型进行训练,再利用验证集来测试模型的泛化误差。另外,现实中数据总是有限的,为了对数据形成重用,从而提出k-折叠交叉验证。
对于个分类或回归问题,假设可选的模型为。k-折叠交叉验证就是将训练集的1/k作为测试集,每个模型训练k次,测试k次,错误率为k次的平均,最终选择平均率最小的模型Mi。
1、 将全部训练集S分成k个不相交的子集,假设S中的训练样例个数为m,那么每一个子集有m/k个训练样例,相应的子集称作{}。
2、 每次从模型集合M中拿出来一个,然后在训练子集中选择出k-1个
{}(也就是每次只留下一个),使用这k-1个子集训练后,得到假设函数。最后使用剩下的一份作测试,得到经验错误。
3、 由于我们每次留下一个(j从1到k),因此会得到k个经验错误,那么对于一个,它的经验错误是这k个经验错误的平均。
4、 选出平均经验错误率最小的,然后使用全部的S再做一次训练,得到最后的。
最后我们划分得到的数据集分为:训练集,测试集。当然,有的会多划分一点,多一个验证集。
3.线性缩放。
在我们辛辛苦苦搜集完数据,完成了最基础的数据整理分类,数据集的划分之后。下一步需要做的就是数据预处理。
数据预处理最常用的还是线性缩放。
数据的线性缩放实际上属于特征工程的部分。
举个例子,面对多维特征问题的时候,有时候数据的极值相差特别大,导致不同维度的数据的尺度相差很大,我们把多维数据在多维空间中画出来的时候,会发现它是扁的,因而我们训练的分类器很难把不同的数据分出来。
 线性缩放
线性缩放
就像上面图左边的,我们用原始数据做训练的时候,很难保证梯度下降能更快收敛。右边是缩放之后的数据,我们可以看到,不同的圆圈之间的区分度更大了。这就是线性缩放的意义。
当然,在我们设计模型上,线性缩放的意义在于:提高模型的收敛速率,提高模型的精度。
线性缩放的方法同样有几种:归一化特征缩放(0-1缩放),标准化特征缩放。
4.矩阵增广。
这部分实际上是线性代数的知识。
在我们处理完数据矩阵,做完线性缩放之后,我们还需要做一个矩阵增广,英文就是Augmented。
回到我们刚刚的数据矩阵中,当我们把数据矩阵进行线性缩放结束之后,我们可以把这个矩阵看成一个方程组,只不过这个方程组有10组参数,697个方程表达式。既然我们能把它看成方程组,那么我们就可以套用成熟的线性代数理论去优化和验证这个矩阵。非齐次线性方程组,就是方程组的等式右边不为0的方程组,系数加上方程等式右边的矩阵,叫做增广矩阵。
方程组唯一确定增广矩阵,通过增广矩阵的初等行变换可用于判断对应线性方程组是否有解,以及化简求原方程组的解。在我们这个例子中,处理增广很简单,就是在矩阵最后一列增加一列1。这就保证了我们这个矩阵就是整个方程组的系数矩阵。
增广矩阵用于判断矩阵解的情况,

5.重置分类标签。
其实这部分很简单,就是把原有的分类标签替换成我们自定义的分类标签就行。
原有的数据中,2代表一个分类,4代表另一个分类。这就是一个简单的二分类问题。在机器学习中,分类是很重要的一个环节,与二分类对应的是多分类问题。二类分类是假设每个样本都被设置了一个且仅有一个标签 0 或者 1。多标签分类(Multilabel classification): 给每个样本一系列的目标标签. 可以想象成一个数据点的各属性不是相互排斥的。

6.初始化权重矩阵。
在我们终于处理好数据,划分完数据集,做完线性缩放,搞定分类标签重置的任务之后。我们就开始设计完整的网络,比如一个最简单的三层多层感知机的设计:
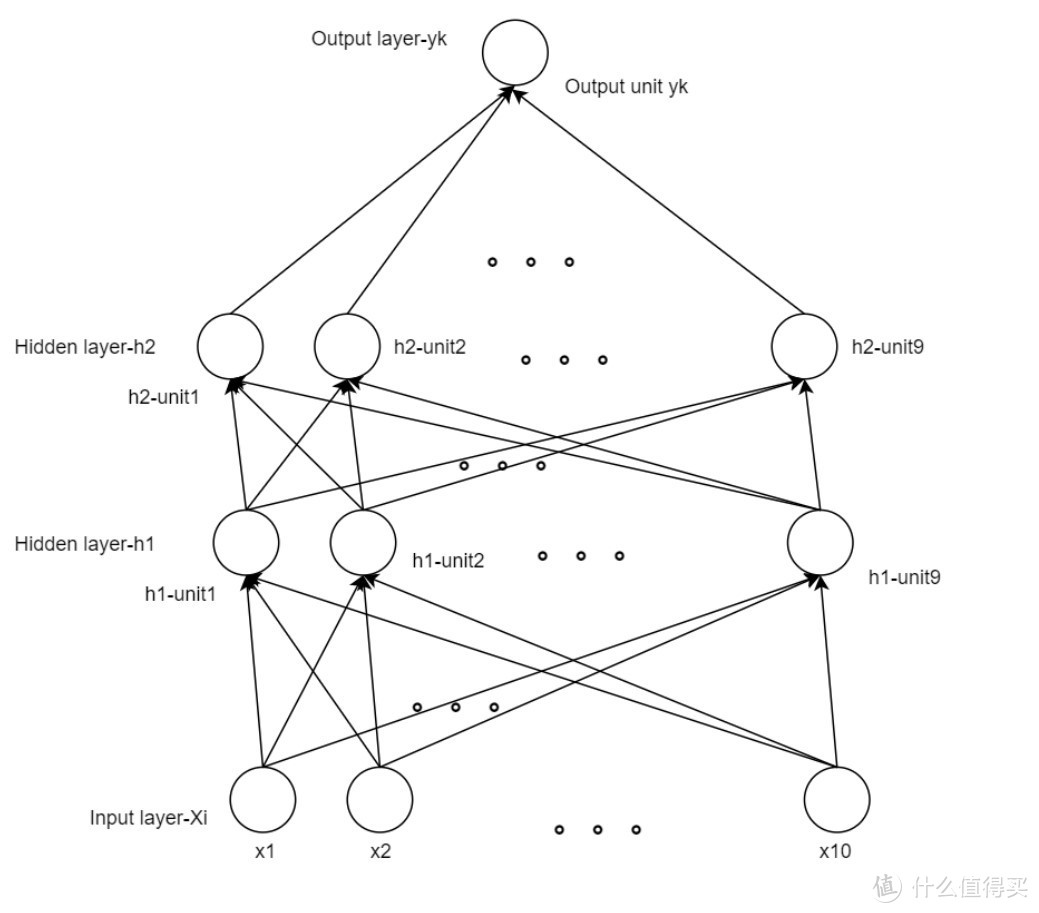
其中,[x1,x2...x10]是输入序列,我们在每一个数据行中,取出10个维度的数据分配给x1到x10。中间的隐藏层有两层,每一层隐藏层都有9个节点,我们称之为unit。当然,每一层之间的链接除了我图上标注出来的之外,还有一个非线性变换,例如用sigmoid函数进行变换。
此处多嘴说几个问题,一个是隐藏层是怎么设置的,一个是为什么要用非线性函数进行变换。
隐藏层之所以叫隐藏层,是因为我们整个模型设计结束之后,它是在模型内部的,并不会表现出来,我们能接触到的部分是模型的输入层与输出层,中间这些我们不会接触到的层,被称为隐含层。
之所以说机器学习是炼丹,是因为隐藏层这个设定是纯自主化的,你可以设定一千层,每一层有一千个节点,你也可以设定两层,每一层有三个节点。当前并没有一个完整而通用的数学模型来指导我们该如何设定隐藏层的数量与节点数,只有几个经验公式告诉我们该如何设置:

设置完隐藏层的数量之后,我们还需要初始化权重向量。但是很明显,我们不能把权重向量设置成全0,这样的话无论输入什么数据我们都没有办法去训练网络。
为什么要在隐藏层之间进行非线性变换呢?

我们一般把这个非线性变换称之为激活函数。如果激活函数为线性的话,我们可以很容易从数学角度推导出来一层与多层隐藏层之间没有任何区别,我们也就失去了设置多层隐藏层的意义。
7.训练网络。
好了,在我们搞定数据集,搞定基本的网络结构之后,我们还要进行训练。这时候我们会引出一个新的问题,超参数怎么设置?
我个人理解的超参数,主要指的是学习速率,迭代次数,层数,每层神经元的个数等等手动设置的参数,而模型可以自动确定定义的参数,比如权重矩阵这些,都被称为是参数。
在设置学习率(learning rate)的时候,初学者总是设定固定的学习率,比如设定为0.00001。我之前第一次设计网络的时候,网络输出一直有问题,后来发现是自己学习率设置太大,设成了0.1,导致网络学习完数据之后就把所有的预测分类全都归到一类去了。当然,现在学术界和工业界也有更多的想法,比如有的研究给出了可变学习率的模型,在开始训练网络的时候学习率会很大,帮助快速逼近最优解,当快逼近最优解的时候将学习率替换成更小的以细化训练过程,防止训练过于粗糙。
至于迭代次数,其实这也是一个非常玄学的问题。一般来说,我们有多少个数据就迭代多少次。但是网络这个东西,你需要防止它过拟合。可能它训练了100个数据就完全拟合了,但是你给了600个数据,那么后面的训练就是过拟合。最后得到的结果也是过拟合的。关于解决过拟合的方法论有很多,比如L1/L2正则化。但是跟迭代联系在一起之后,我们可以设定一个预测输出与实际输出的差值阈值,当预测输出与实际输出的插值小于我们设定的阈值时候我们就可以停止网络训练了。其实这个思路也就是我们数值计算中进行数值拟合的思路。
8.预测与分类。
其实预测与分类这部分应该放在网络训练之前讲的,因为选择合适的分类器是我们设计网络之前的问题。
传统的机器学习的监督学习分类分类和回归,分类是争对离散的数据,而回归是争对连续的数据,在数据预处理好的基础上要对数据进行预测,通常采用CV交叉验证来进行模型评价和选择。这篇文章通过连续的数据结合sklearn库对各种回归器做一比较:
1.linear regression
缺点:顾名思义,linear regression是假设数据服从线性分布的,这一假设前提也限制了该模型的准确率,因为现实中由于噪声等的存在很少有数据是严格服从线性的。
优点:基于这种假设,linear regression可以通过normal equation求闭合解的方式求得y_predict
2.logistic regression
缺点:从线性回归衍生而来,将线性的值域通过sigmoid函数压缩在(0,1)范围内,缺点同linear regression,且也是要求数据是无缺失的
优点:有两种方式求解,精确的解析解和SGD算法估计,在要求准确性时使用解析解,在要求时间效率时使用SGD 迭代
3.SVM(支持向量机 )
缺点:计算代价比较大,SVM是将低维无序杂乱的数据通过核函数(RBF,poly,linear,sigmoid)映射到高维空间,通过超平面将其分开
优点:SVM是通过支撑面做分类的,也就是说不需要计算所有的样本,高维数据中只需去少量的样本,节省了内存
在sklearn默认配置中三种核函数的准确率大概是:RBF>poly>linear
4.Naive Bayes
缺点:这一模型适合用在文本样本上,采用了朴素贝叶斯原理假设样本间是相互独立的,因此在关联比较强的样本上效果很差
优点:也是基于其独立的假设,概率计算大大简化,节省内存和时间
5.K近邻
缺点:k需要人为设定,且该算法的复杂度很高
优点:“近朱者赤,近墨者黑”KNN是无参数训练的模型
6.决策树(DT)
缺点:在训练数据上比较耗时
优点:对数据要求度最低的模型,数据可以缺失,可以是非线性的,可以是不同的类型,,最接近人类逻辑思维的模型,可解释性好
7.集成模型(众志成城模型)
random forest:随机抽取样本形成多个分类器,通过vote,少数服从多数的方式决定最终属于多数的分类器结果,分类器之间是相互去之间关联的
gradient boost:弱弱变强,最典型的代表是adaboost(三个臭皮匠,顶个诸葛亮),弱分类器按照一定的计算方式组合形成强的分类器,分类器之间存在关联,最终分类是多个分类器组合的结果
一般地,GB>RF>DT
但是集成模型缺点在于受概率的影响,具有不确定性
以上是常用的回归分类器的比较,在知道各种分类器的优缺点之后就可以使用正确的分类器完成自己的数据处理,如下表是通过计算各类分类器的残差来对比同一任务不同分类器之间的好坏,可以看出来在sklearn默认参数的前提下,准确率排序是:集成模型>DT>SVM>KNN>Linear
有关于预测准确度的设计:
在机器学习里面做一些分类任务时,经常会使用到一些评价指标,下面就一些常用的指标进行详细的说明。
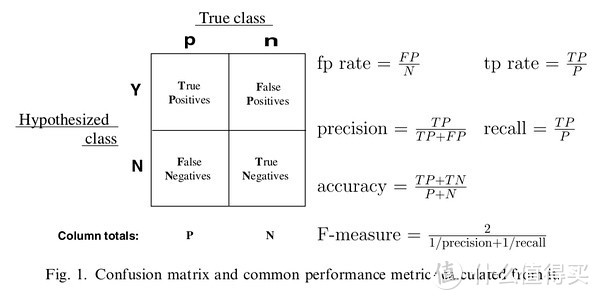
上图表示为一个二分类的混淆矩阵(多分类同理,只需要把不属于当前类的其他类都考虑为负例),表格中的四个参数说明:
True Positive(TP):预测为正例,实际为正例
False Positive(FP):预测为正例,实际为负例
True Negative(TN):预测为负例,实际为负例
False Negative(FN):预测为负例,实际为正例
从这我们可以看出,TP和TN都是预测对了,FP和FN都是预测错了。

【指标分析】
我们最容易搞混的就是accuracy和precision,好像两者都可以称为准确率,正确率,精度等等...其实我们不必要考究两者的中文称呼究竟是什么,搞清楚两者的含义自然就可以区分它们。首先,accuracy指的是正确预测的样本数占总预测样本数的比值,它不考虑预测的样本是正例还是负例。而precision指的是正确预测的正样本数占所有预测为正样本的数量的比值,也就是说所有预测为正样本的样本中有多少是真正的正样本。从这我们可以看出,precision只关注预测为正样本的部分,而accuracy考虑全部样本。
Recall可以称为召回率、查全率等等...我们也不考究如何翻译它,它指的是正确预测的正样本数占真实正样本总数的比值,也就是我能从这些样本中能够正确找出多少个正样本。
F-score相当于precision和recall的调和平均,用意是要参考两个指标。从公式我们可以看出,recall和precision任何一个数值减小,F-score都会减小,反之,亦然。
specificity指标平时见得不多,它是相对于sensitivity(recall)而言的,指的是正确预测的负样本数占真实负样本总数的比值,也就是我能从这些样本中能够正确找出多少个负样本。
【实例说明】
问题:假设某个学校有1000个王者荣耀玩家,其中有10个是王者段位,判断这个玩家是不是王者选手?
现在我有一个分类器,检测出来有20个王者选手,其中包含5个真正的王者选手。那么上述指标该如何计算呢?
分析:检测出来有20个王者选手,说明有980个选手被预测为非王者选手。这20个检测为王者选手包含5个真正的王者选手,说明另外15个实际为非王者选手,所以,
accuracy = (5+980-5) / 1000 = 0.98
precision = 5 / 20 = 0.25
recall = 5 / 10 = 0.5
F-score = 2 / (1/0.25 + 1/0.5) = 0.33
sensitivity = recall = 0.5
specificity = (980-5) / (1000-10) = 0.98
从这个案例我们可以发现,虽然分类器的accuracy可以达到98%,但是如果我的目的是尽可能的找出隐藏在这1000人中的王者选手,那么这个分类器的性能是不达标的,这也就是为什么要引入precision和recall以及F-score评价指标的原因。
ok,关于设计一整个机器学习的流程,我就介绍到这里。应该算是我简单的个人想法之一。要说简单也简单,你跟这个这个流程一步一步做下去肯定可以自己设计一个深度学习模型出来,要说难也难,因为中间每一个流程都涉及到了大量的数学知识,你要根据自己的问题实际情况去选择特定的数学工具组成这个的话,肯定是需要花费大量的时间的。
如果有问题可以在下面评论问我。

















沃日很皮
校验提示文案
值友9620713152
校验提示文案
值友9620713152
校验提示文案
沃日很皮
校验提示文案