






























































28
59
一劳永逸解决Obsidian图床与上传——利用企业微信进行剪藏网页
2022-09-26 20:59:46
2点赞
35收藏
9评论
引言
本文较长且图片较多,所需阅读的时间可能较长。
写作本文的起因还是由于日常工作学习中的需求。很多时候,工作和学习中的很多事情需要去进行记录,日常生活的点点滴滴总是能够串起一段段令人回忆的时光,使得我们可以见证自己的成长,这就催生了云笔记的市场。传统的印象笔记以及有道云笔记,以及近几年兴起的notion给大家提供了非常多的选择。但是这些均有其弊端,如印象笔记愈发臃肿的体型,有道云笔记只能导入不能自由导出的机制,以及notion众所周知的原因导致使用上的体验仍不能令人满意。很多时候,需要的只是一个简单的记录工具,能够完全掌握自己的数据,以及愉快的同步体验,这就不得让目光转向开源的笔记系统。
在试过几款开源的云笔记软件,如obsidian、joplin、logseq后,最终还是选择了使用obsidian。究其原因,还是其美观的界面、拥有丰富的皮肤以及插件可以选择,以及相对完善的双链笔记的功能。但是,除了在美观以及功能的丰富性上超越joplin外,其始终缺少一个有效的网页剪藏功能还是令人觉得遗憾。虽然其自身插件市场有着Extracr url content这类插件可以完成日常的剪藏操作,但是需要以命令行方式去执行的方式实在是令人难以接受。
除去剪藏功能外,还有一个重要的因素就是图床。很多优秀的浏览器插件虽然可以实现将网页转为markdown格式的文件保存到本地,再移入obsidian中进行保存,但是其保存的图片链接往往会因为各种原因失效。采用开源笔记的一个原因,就是要将数据牢牢的掌握在自己手中,这种图片链接失效的问题无疑背离了这个初衷,因此,经过了很长时间的捣鼓,初步实现了向微信发送消息即完成剪藏并自动替换图片为本地图床链接的功能,这个项目理论上可以实现各种支持markdown以及webdav的笔记软件,可以放心进行食用。
1 预备工作
1.1 硬件部分
对于硬件的选择,大致有两种方案,即本地部署与云服务器。
关于云服务器的选择,阿里云腾讯云均可,但是考虑到国内的云服务器价格较贵,且贷款通常只有5M的小水管,虽说对于构建该项目完全够用,但是再次还是推荐一下阿里云的新加坡服务器(无利害关系),纯粹是因为真的很便宜。国内的云服务器来说虽然新人会有活动,但是到期后价格直接都是翻了好几倍,完全不划算。但是阿里云的新加坡服务器只需要24元一个月,而且续费始终都是这个价格,如果长期使用的话还是比较推荐这种的。
关于本地部署,可选择的范围就特别广了,可以采用最近站内很火的cm311,以及玩客云、n1、开发板以及其他的arm设备。除此之外,还有支持docker的一众nas设备。但是在此还是坚定的推荐x86设备,原因在于很多docker镜像并未提供支持arm的版本,为了后续的玩耍,还是一劳永逸的选择x86设备。关于x86设备,并不是传统大家想象中的高价,也有很多很便宜的设备可以选择,不在意百兆网口的话,即使是D525、D2550这种早已经过时的设备也堪堪够用(何况目前市面上还有很多D525这种的千兆软路由,价格只需五六十元即可找到)。如果说推荐的话,最好起步还是J1800、J1900、N3150这种入门的处理器,毕竟可以玩的时间更长嘛。
1.2 软件部分
1.2.1 企业微信
1.2.1.1 注册一个企业微信
注册一个企业微信
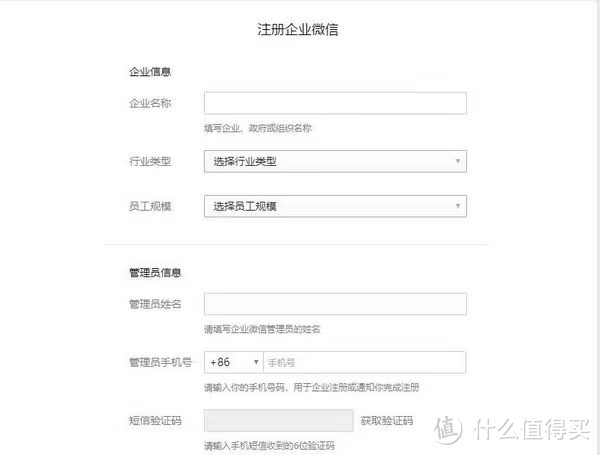 注册一个企业微信
注册一个企业微信
1.2.1.2 创建应用
注册完毕之后,进入企业微信,点击应用管理-应用-创建应用
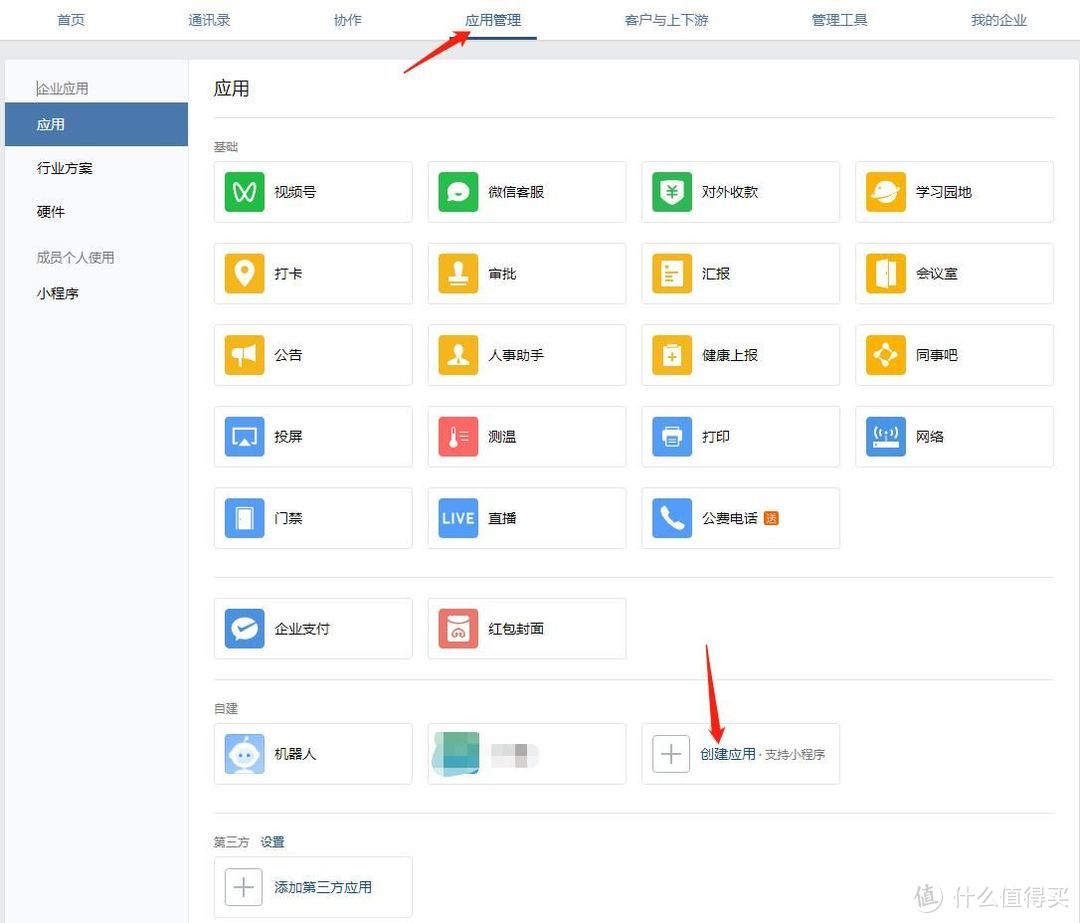 创建应用
创建应用
应用创建完毕之后,记住AgentId与Secret,后面会用到
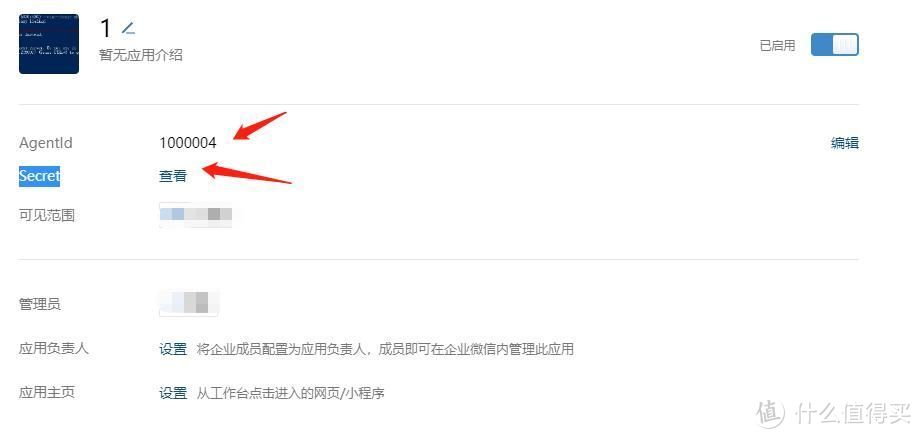 AgentId与Secret
AgentId与Secret
然后进入 我的企业,记住企业ID
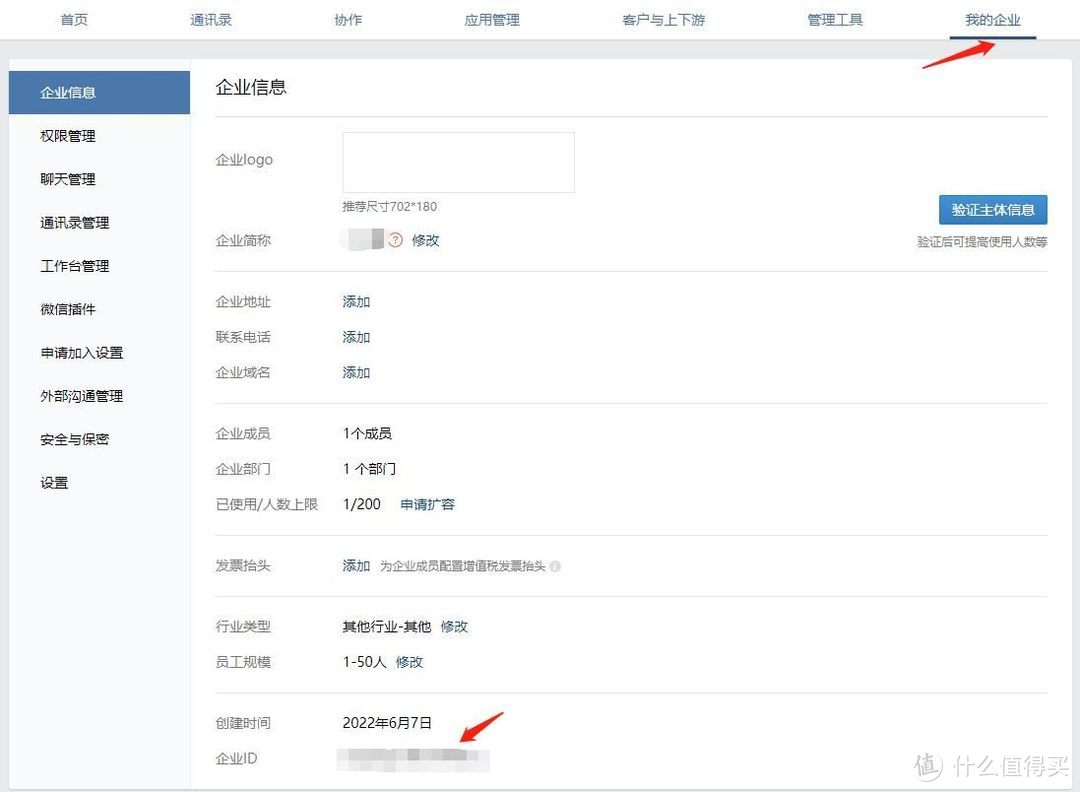 企业ID
企业ID
1.2.2 建立图床
1.2.2.1 引言
由于自己组建了一个unraid的nas,因此笔者采用的是自建图床的方式。本身为了图方便,想让图床以一个尽量简单的方式去满足需求,因此采用的Easyimages。本地部署的还可以采用兰空图床( Lsky Pro)或者Chevereto(Chevereto - 图像托管程序 (简体中文));如果是采用云服务商的方案的话,也有阿里oss、腾讯oss、七牛图床、SM.MS等方案可以采用。
除此之外,还有将图片转换为base64的方式保存在本地,但是该种方案并不推荐使用,其一是会导致笔记的体积较大,全部以字符串的方式进行保存,会导致笔记体积过大,往往图片一多的话就会导致单个笔记的体积超过10MB,会严重影响笔记软件的性能;其二是全部字符串的方式保存,在后续需要修改笔记的时候,会带来视觉上的障碍以及修改上的不便。关于阿里云oss与base64方案的参考代码后面会开文慢慢再写,届时只需要替换掉功能函数部分的代码即可,不再赘述。
1.2.2.2 建立Easyimages图床
docker run -itd --name easyige --restart=always -p 0:80 -v /docker/easyige/config:/app/web/config -v /docker/easyige/i:/app/web/i ddsderek/easyige
关于这个代码,需要根据自己需要修改的部分主要包括:
-p 18080:80修改18080为需要的端口号
-v /docker/easyige/config:/app/web/config -v /docker/easyige/i:/app/web/i ddsderek/easyige
对于两个-v,”:”前面的部分可以根据需要修改路径,如果没有特别的需求,照抄即可。
建立完毕之后,进入对应的地址,即http://服务器地址:指定端口号,完成注册。一般来说注册完毕之后直接会跳转设置界面,如果没有跳转的话,那么输入网址http://IP:端口号/admin即可进入下面的界面。
需要注意的主要有以下两个部分:
1、图片域名
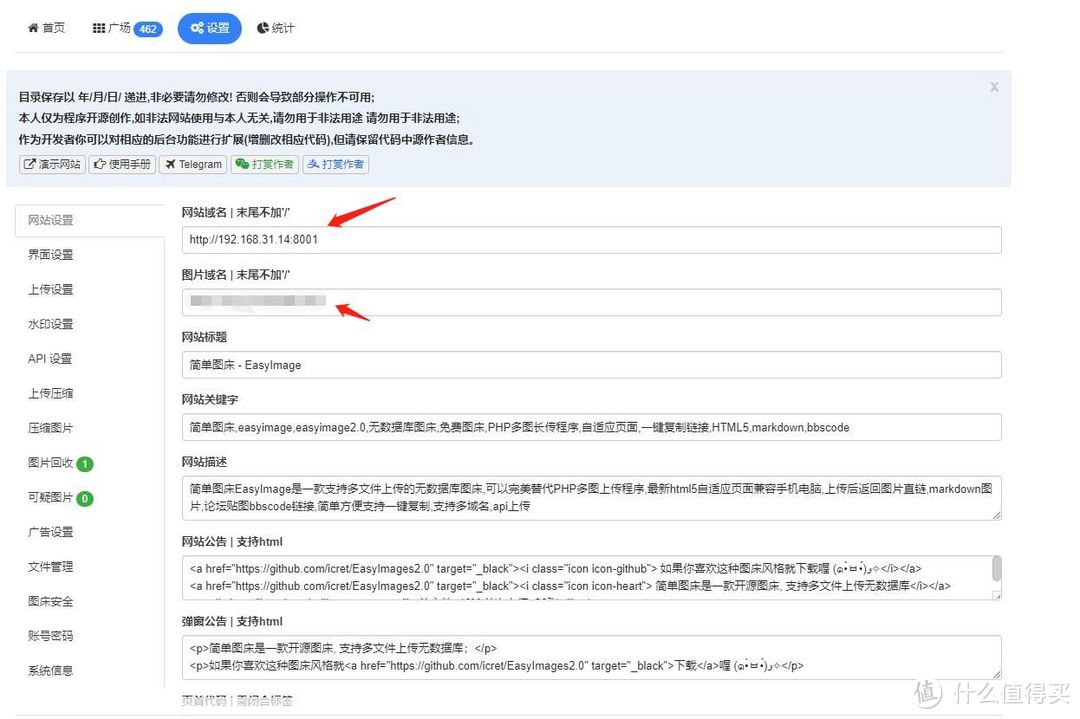 图片域名设置
图片域名设置
这部分的作用是,最后返回的图片链接经过处理是可以直接在markdown模式下显示出来的。如果是本地部署使用的,超出局域网的范围该链接就完全无法显示,对此可以采用内网穿透的方式绑定域名实现无论在哪里都能正确显示图片,这才是使用本地笔记的最终形态。对此可以采用内网穿透的方式进行部署,后面会简单介绍一下。如果是在云服务器部署的,直接填写服务器的IP加上端口号即可。
2、token
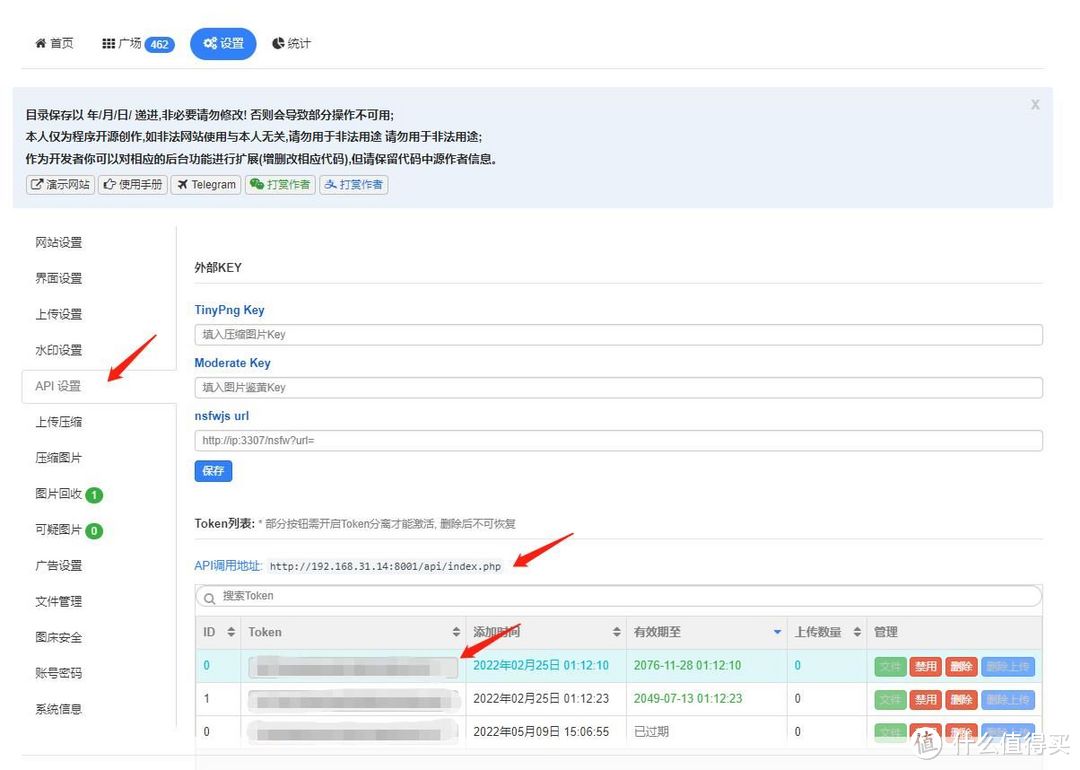 token与api
token与api
点击API设置,记住API调用地址,以及下面的token,后面会用到。多个token参照到期时间择一选用即可。
1.2.3 建立一个webdav,解决笔记的同步
1、镜像
镜像参照自己服务器的架构进行选用:
若为x86架构,简单点可以理解成采用的是intel与amd处理器的设备,进行如下操作:
docker pull ugeek/webdav:amd64
若为arm架构,即4k播放器、开发板等设备,即可进行如下操作(需要注意的是,部分设备如玩客云由于s805芯片由于是32位处理器,且为armv7架构,不一定支持该镜像,若有读者测试过,可以留言告知一下):
docker pull ugeek/webdav:arm
2、部署
docker run --name webdav --restart=unless-stopped -p 811:80 -v /docker/webdav:/media -e USERNAME=xxxx -e PASSWORD=xxxxx -e TZ=Europe/drid -e UDI=1000 -e GID=1000 -d ugeek/webdav:amd64
此处需要修改的,可以参照1.2.2.2中的进行修改。
需要注意的是,最后的ugeek/webdav:amd64,需要根据自己选择的镜像进行修改。
除此之外,还需要设置自己的用户名以及密码,修改部分为USERNAME与PASSWORD。
此步骤需要记住的是服务器地址,即http://ip:端口号,以及用户名、密码,后面会用到
3、Obsidian的同步设置
第一步:先下载对应的插件,名称为Remotely Save
建议是下载现成的文件,三个文件分别名为main.js、manifest.json、styless.css
下载这三个选项,创建一个新的文件夹,命名为Remotely Save,将下载的三个文件放到文件夹中
按照如图的路径找到Obsidian的插件储存路径,将文件夹复制到该文件夹下,重启Obsidian
 插件路径
插件路径
若这一步找不到.obsidian文件夹,参照该篇文章自行解决怎么显示win10系统隐藏文件夹 - 知乎 (zhihu.com)
打开Obsidian第三方插件里面的安全模式,搜索remotely save,点击开启。
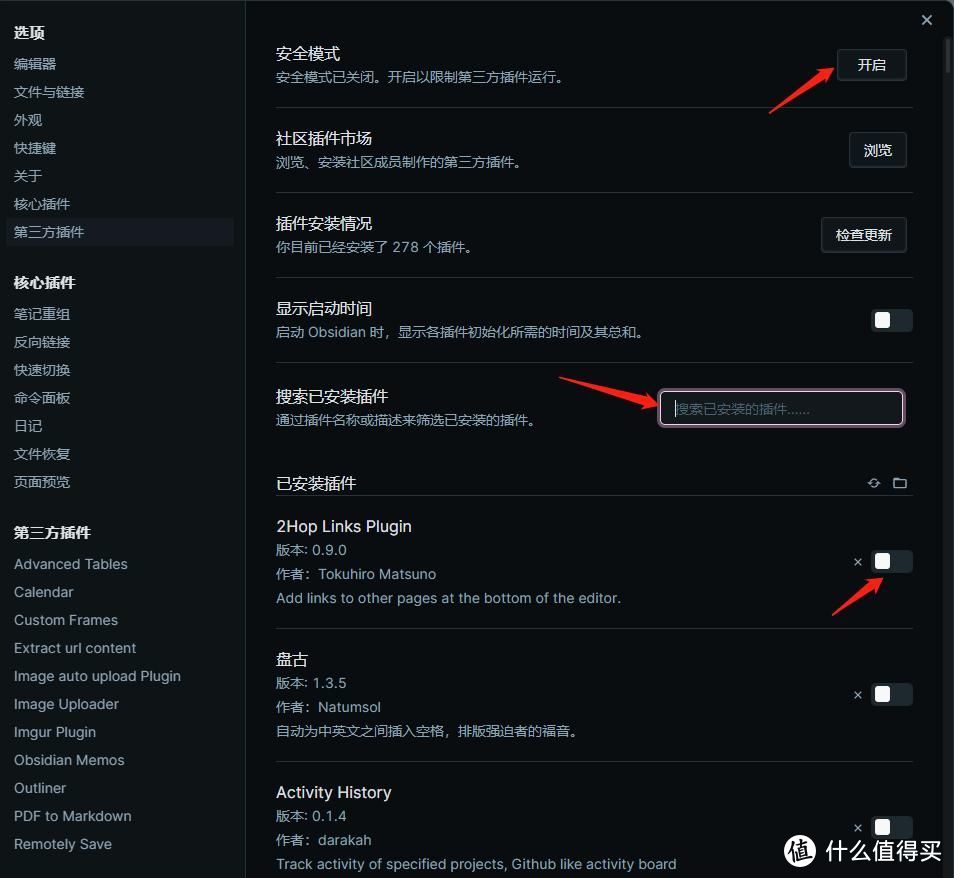 打开插件
打开插件
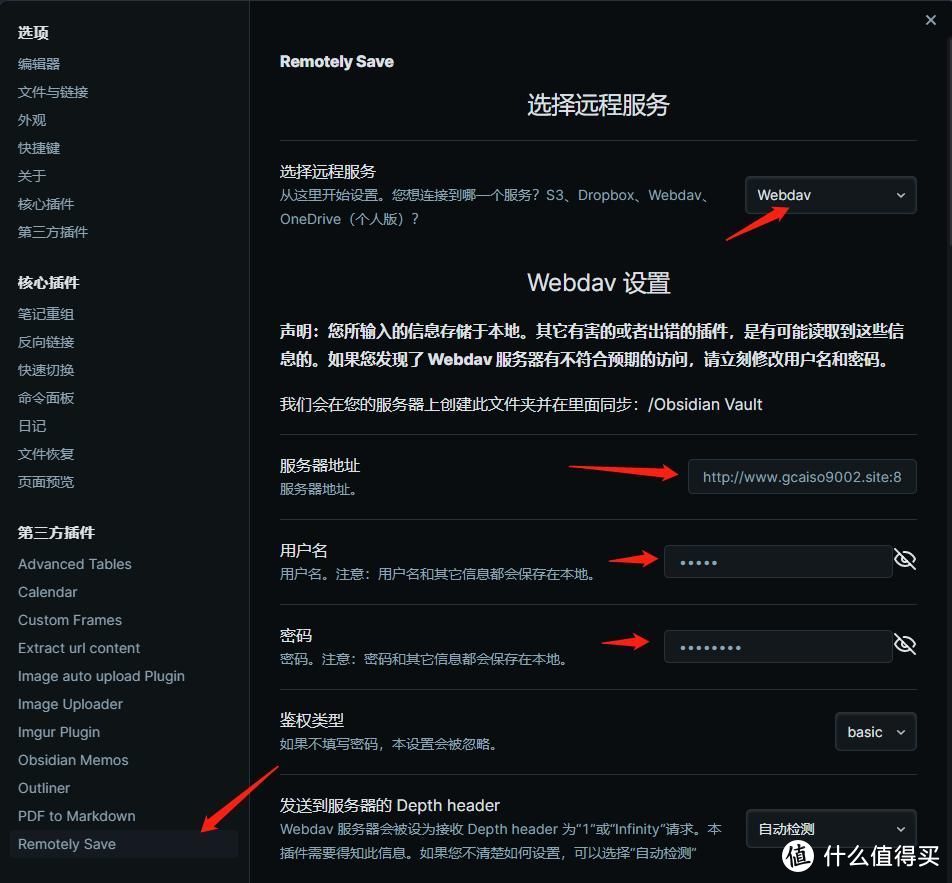
点击左侧的插件,选择远程服务为webdav,填入你的服务器地址、用户名、密码,点击下面的检查连接,如果他通过的话,就可以愉快的完成obsidian的同步了。
2 功能部分的构建
2.1 Python部分
2.1.1 主体功能函数
进行该步骤之前,建议先在Obsidian中建立一个名为网页剪藏的文件夹,以后剪藏的网页都会保存在这个文件夹中,后续整理的时候再陆续给移到其他文件夹中。
此处需要填入的内容(填在后面完整版的部分):
self.webdav_hostname:webdav服务器地址+你建立的库的名称(建议采用Obsidian Vault)+网页剪藏,如http://IP:端口号(或者直接写域名也行)/Obsidian Vault/网页剪藏
self.webdav_login:webdav用户名
self.webdav_password:webdav密码
self.imgurl:上述图床的api
self.token:上述图床的token
class Clipper:
def __init__(self):
# webdav参数
self.webdav_hostname = r''
self.webdav_login = ''
self.webdav_password = ''
# easyimage图床
self.imgurl = r''
self.token = r""
self.path = os.getcwd()
# 1 剪藏网页
def mdclipper(self, s):
s = str(s)
if 'http' not in s:
print('请输入正确网址')
return '请输入正确的网址'
else:
# 提取网址
print('正在提取网址')
link = re.findall(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*(),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', s)
url = link[0]
headers = {
'Connection': 'close',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42'
}
response = requests.get(url, headers=headers)
contents = response.content.decode('utf8')
doc = Document(contents)
# print('title:', doc.title())
# print('content:', doc.summary(html_partial=True))
# # print(type(doc.summary(html_partial=True)))
markdown = html2text.html2text(doc.summary(html_partial=True))
# 删除空的图片引用
markdown = markdown.replace('![]()', '')
mdname = '{}.md'.format(doc.title()) # md的文件名
return markdown, mdname
# 2 判断文件中是否有图片,有则返回True,没有则返回False
def judge(self, md_content):
# 图片的下载地址
img_patten = r')|<img.*?src=['"](.*?)['"].*?>'
img_urls = re.findall(img_patten, md_content)
if len(img_urls) != 0:
return True
else:
return False
# 3 处理图片
## 3.1 提取图片链接(建立在3中返回为True的情形下)
def process_md(self, md_content):
# 图片的下载地址
img_patten = r')|<img.*?src=['"](.*?)['"].*?>'
img_urls = re.findall(img_patten, md_content)
# markdown插入的图片格式
link_pattern = r'()|(<img.*?src=['"].*?['"].*?>)'
md_links = re.findall(link_pattern, md_content)
# 提取出有效信息
for i in range(len(md_links)):
md_links[i] = md_links[i][0] # file_name为文件储存路径及文件名
for i in range(len(img_urls)):
img_urls[i] = img_urls[i][0] # img_url为图片链接,
return img_urls, md_links
## 3.2 下载图片
def download_img(self, url):
t = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))
s = ''.join(random.sample(string.ascii_letters + string.digits, 8))
file_name = '{}-{}.jpeg'.format(t, s)
# 下载图片
res = requests.get(url)
with open(file_name, 'wb') as f:
f.write(res.content)
# 返回图片名称
return file_name
## 3.3 保存图片名称为列表
def createimglist(self, img_urls):
imglist = []
for i in img_urls:
name = self.download_img(i)
imglist.append(name)
return imglist
# 4 上传到自建图床imgurl
def sendImg(self, img_name, img_type="image/jpeg"):
with open(img_name, 'rb') as f:
f_abs = f.read()
url = self.imgurl # 自己想要请求的接口地址
body = {
"image": (img_name, f_abs, img_type)
}
data = {
"token": self.token
}
response = requests.post(url=url, files=body, data=data)
content = response.content.decode('utf-8')
# 将转换出来的字符串转换成字典,方便提取内容
content = json.loads(content)
print(content)
url = content['url']
t = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))
url = ''.format(t, url)
return url
# 5 删除图片和md文件
def delete(self):
for root, dirs, files in os.walk(self.path):
for name in files:
if name.endswith(".jpeg") or name.endswith(".md"): # 填写规则
os.remove(os.path.join(root, name))
# 7 上传到webdav
def upload(self, file_name):
options = {
'webdav_hostname': self.webdav_hostname,
'webdav_login': self.webdav_login,
'webdav_password': self.webdav_password,
'disable_check': True, # 有的网盘不支持check功能
}
client = Client(options)
# 我选择用时间戳为备份文件命名
try:
# 写死的路径,第一个参数是网盘地址
client.upload(file_name, self.path + '/' + file_name)
# 打印结果,之后会重定向到log
print('正在上传:' + file_name)
except LocalResourceNotFound as exception:
print('An error happen: LocalResourceNotFound ---' + file_name)
def mainclipper(self, url):
md = self.mdclipper(url)
if isinstance(md,str):
return md
else:
mdname = md[1]
mdcontent = md[0]
if not self.judge(mdcontent):
with open(mdname, 'w+', encoding='utf-8') as file:
file.write(mdcontent)
# 上传文件到webdav
self.upload(mdname)
# 删除md文件
self.delete()
return '剪藏成功,文件名为:{}'.format(mdname)
else:
img = self.process_md(mdcontent)
# 图片的下载地址
img_urls = img[0]
# 待替换的图片链接
md_links = img[1]
# 获得图片名称列表
imglist = self.createimglist(img_urls)
urls = []
for i in imglist:
# 传入文件名称,自动生成路径上传至图床
res = self.sendImg(i)
urls.append(res) # 获得符合markdown格式的图片链接
for i in range(len(urls)):
mdcontent = mdcontent.replace(md_links[i], urls[i])
# 保存文件
with open(mdname, 'w+', encoding="utf-8") as f:
f.write(mdcontent)
# 上传文件到webdav
self.upload(mdname)
# 删除md文件
# 删除图片
self.delete()
return '剪藏成功,文件名为:{}'.format(mdname)
2.1.2 发送消息到微信
此处代码参考了前人的代码
需要填入的部分为上述的AgentId、Secret以及CompanyId
def send2wechat(message):
AgentId = ''
Secret = ''
CompanyId = ''
# 通行密钥
ACCESS_TOKEN = None
# 如果本地保存的有通行密钥且时间不超过两小时,就用本地的通行密钥
if os.path.exists('ACCESS_TOKEN.txt'):
txt_last_edit_time = os.stat('ACCESS_TOKEN.txt').st_mtime
now_time = time.time()
if now_time - txt_last_edit_time < 7200: # 官方说通行密钥2小时刷新
with open('ACCESS_TOKEN.txt', 'r') as f:
ACCESS_TOKEN = f.read()
# print(ACCESS_TOKEN)
# 如果不存在本地通行密钥,通过企业ID和应用Secret获取
if not ACCESS_TOKEN:
r = requests.post(
f'https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={CompanyId}&corpsecret={Secret}').json()
ACCESS_TOKEN = r["access_token"]
# print(ACCESS_TOKEN)
# 保存通行密钥到本地ACCESS_TOKEN.txt
with open('ACCESS_TOKEN.txt', 'w', encoding='utf-8') as f:
f.write(ACCESS_TOKEN)
# 要发送的信息格式
data = {
"touser": "@all",
"msgtype": "text",
"agentid": f"{AgentId}",
"text": {"content": f"{message}"}
}
# 字典转成json,不然会报错
data = json.dumps(data)
# 发送消息
r = requests.post(
f'https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={ACCESS_TOKEN}', data=data)
# print(r.json())
2.1.3 腾讯官方解码函数
此处将该函数命名为decode.py,并放置在整个项目的根目录,此处代码参考利用Python制作微信机器人(二)_学徒。的博客-CSDN博客_python制作微信机器人
回到企业微信,点击创建的应用
 点击创建的应用
点击创建的应用
设置api接收
 设置api接收
设置api接收
点击随机获取,记住这两个参数,加上上述获取的companyip,一并填入下面函数对应的部分

填好对应的参数,保存为decode.py
import logging
import base64
import random
import hashlib
import time
import struct
from Crypto.Cipher import AES
import xml.etree.cElementTree as ET
import socket
WXBizMsgCrypt_OK = 0
WXBizMsgCrypt_ValidateSignature_Error = -40001
WXBizMsgCrypt_ParseXml_Error = -40002
WXBizMsgCrypt_ComputeSignature_Error = -40003
WXBizMsgCrypt_IllegalAesKey = -40004
WXBizMsgCrypt_ValidateCorpid_Error = -40005
WXBizMsgCrypt_EncryptAES_Error = -40006
WXBizMsgCrypt_DecryptAES_Error = -40007
WXBizMsgCrypt_IllegalBuffer = -40008
WXBizMsgCrypt_EncodeBase64_Error = -40009
WXBizMsgCrypt_DecodeBase64_Error = -40010
WXBizMsgCrypt_GenReturnXml_Error = -40011
"""
关于Crypto.Cipher模块,ImportError: No module named 'Crypto'解决方案
请到官方网站 https://www.dlitz.net/software/pycrypto/ 下载pycrypto。
下载后,按照README中的“Installation”小节的提示进行pycrypto安装。
"""
class FormatException(Exception):
pass
def throw_exception(message, exception_class=FormatException):
"""my define raise exception function"""
raise exception_class(message)
class SHA1:
"""计算企业微信的消息签名接口"""
def getSHA1(self, token, timestamp, nonce, encrypt):
"""用SHA1算法生成安全签名
@param token: 票据
@param timestamp: 时间戳
@param encrypt: 密文
@param nonce: 随机字符串
@return: 安全签名
"""
try:
sortlist = [token, str(timestamp), nonce, encrypt]
sortlist.sort()
sha = hashlib.sha1()
sha.update("".join(sortlist).encode())
return WXBizMsgCrypt_OK, sha.hexdigest()
except Exception as e:
logger = logging.getLogger()
logger.exception(e)
return WXBizMsgCrypt_ComputeSignature_Error, None
class XMLParse:
"""提供提取消息格式中的密文及生成回复消息格式的接口"""
# xml消息模板
AES_TEXT_RESPONSE_TEMPLATE = """<xml>
<Encrypt><![CDATA[%(msg_encrypt)s]]></Encrypt>
<MsgSignature><![CDATA[%(msg_signaturet)s]]></MsgSignature>
<TimeStamp>%(timestamp)s</TimeStamp>
<Nonce><![CDATA[%(nonce)s]]></Nonce>
</xml>"""
def extract(self, xmltext):
"""提取出xml数据包中的加密消息
@param xmltext: 待提取的xml字符串
@return: 提取出的加密消息字符串
"""
try:
xml_tree = ET.fromstring(xmltext)
encrypt = xml_tree.find("Encrypt")
return WXBizMsgCrypt_OK, encrypt.text
except Exception as e:
logger = logging.getLogger()
logger.error(e)
return WXBizMsgCrypt_ParseXml_Error, None
def generate(self, encrypt, signature, timestamp, nonce):
"""生成xml消息
@param encrypt: 加密后的消息密文
@param signature: 安全签名
@param timestamp: 时间戳
@param nonce: 随机字符串
@return: 生成的xml字符串
"""
resp_dict = {
'msg_encrypt': encrypt,
'msg_signaturet': signature,
'timestamp': timestamp,
'nonce': nonce,
}
resp_xml = self.AES_TEXT_RESPONSE_TEMPLATE % resp_dict
return resp_xml
class PKCS7Encoder():
"""提供基于PKCS7算法的加解密接口"""
block_size = 32
def encode(self, text):
""" 对需要加密的明文进行填充补位
@param text: 需要进行填充补位操作的明文
@return: 补齐明文字符串
"""
text_length = len(text)
# 计算需要填充的位数
amount_to_pad = self.block_size - (text_length % self.block_size)
if amount_to_pad == 0:
amount_to_pad = self.block_size
# 获得补位所用的字符
pad = chr(amount_to_pad)
return text + (pad * amount_to_pad).encode()
def decode(self, decrypted):
"""删除解密后明文的补位字符
@param decrypted: 解密后的明文
@return: 删除补位字符后的明文
"""
pad = ord(decrypted[-1])
if pad < 1 or pad > 32:
pad = 0
return decrypted[:-pad]
class Prpcrypt(object):
"""提供接收和推送给企业微信消息的加解密接口"""
def __init__(self, key):
# self.key = base64.b64decode(key+"=")
self.key = key
# 设置加解密模式为AES的CBC模式
self.mode = AES.MODE_CBC
def encrypt(self, text, receiveid):
"""对明文进行加密
@param text: 需要加密的明文
@return: 加密得到的字符串
"""
# 16位随机字符串添加到明文开头
text = text.encode()
text = self.get_random_str() + struct.pack("I", socket.htonl(len(text))) +
text + receiveid.encode()
# 使用自定义的填充方式对明文进行补位填充
pkcs7 = PKCS7Encoder()
text = pkcs7.encode(text)
# 加密
cryptor = AES.new(self.key, self.mode, self.key[:16])
try:
ciphertext = cryptor.encrypt(text)
# 使用BASE64对加密后的字符串进行编码
return WXBizMsgCrypt_OK, base64.b64encode(ciphertext)
except Exception as e:
logger = logging.getLogger()
logger.error(e)
return WXBizMsgCrypt_EncryptAES_Error, None
def decrypt(self, text, receiveid):
"""对解密后的明文进行补位删除
@param text: 密文
@return: 删除填充补位后的明文
"""
try:
cryptor = AES.new(self.key, self.mode, self.key[:16])
# 使用BASE64对密文进行解码,然后AES-CBC解密
plain_text = cryptor.decrypt(base64.b64decode(text))
except Exception as e:
logger = logging.getLogger()
logger.error(e)
return WXBizMsgCrypt_DecryptAES_Error, None
try:
pad = plain_text[-1]
# 去掉补位字符串
# pkcs7 = PKCS7Encoder()
# plain_text = pkcs7.encode(plain_text) # 去除16位随机字符串
content = plain_text[16:-pad]
xml_len = socket.ntohl(struct.unpack("I", content[: 4])[0])
xml_content = content[4: xml_len + 4]
from_receiveid = content[xml_len + 4:]
except Exception as e:
logger = logging.getLogger()
logger.error(e)
return WXBizMsgCrypt_IllegalBuffer, None
if from_receiveid.decode('utf8') != receiveid:
return WXBizMsgCrypt_ValidateCorpid_Error, None
return 0, xml_content
def get_random_str(self):
""" 随机生成16位字符串
@return: 16位字符串
"""
return str(random.randint(1000000000000000, 9999999999999999)).encode()
class WXBizMsgCrypt(object):
# 构造函数
def __init__(self, sToken, sEncodingAESKey, sReceiveId):
try:
self.key = base64.b64decode(sEncodingAESKey + "=")
assert len(self.key) == 32
except:
throw_exception(
"[error]: EncodingAESKey unvalid !", FormatException)
# return WXBizMsgCrypt_IllegalAesKey,None
self.m_sToken = sToken
self.m_sReceiveId = sReceiveId
# 验证URL
# @param sMsgSignature: 签名串,对应URL参数的msg_signature
# @param sTimeStamp: 时间戳,对应URL参数的timestamp
# @param sNonce: 随机串,对应URL参数的nonce
# @param sEchoStr: 随机串,对应URL参数的echostr
# @param sReplyEchoStr: 解密之后的echostr,当return返回0时有效
# @return:成功0,失败返回对应的错误码
def VerifyURL(self, sMsgSignature, sTimeStamp, sNonce, sEchoStr):
sha1 = SHA1()
ret, signature = sha1.getSHA1(
self.m_sToken, sTimeStamp, sNonce, sEchoStr)
if ret != 0:
return ret, None
if not signature == sMsgSignature:
return WXBizMsgCrypt_ValidateSignature_Error, None
pc = Prpcrypt(self.key)
ret, sReplyEchoStr = pc.decrypt(sEchoStr, self.m_sReceiveId)
return ret, sReplyEchoStr
def EncryptMsg(self, sReplyMsg, sNonce, timestamp=None):
# 将企业回复用户的消息加密打包
# @param sReplyMsg: 企业号待回复用户的消息,xml格式的字符串
# @param sTimeStamp: 时间戳,可以自己生成,也可以用URL参数的timestamp,如为None则自动用当前时间
# @param sNonce: 随机串,可以自己生成,也可以用URL参数的nonce
# sEncryptMsg: 加密后的可以直接回复用户的密文,包括msg_signature, timestamp, nonce, encrypt的xml格式的字符串,
# return:成功0,sEncryptMsg,失败返回对应的错误码None
pc = Prpcrypt(self.key)
ret, encrypt = pc.encrypt(sReplyMsg, self.m_sReceiveId)
encrypt = encrypt.decode('utf8')
if ret != 0:
return ret, None
if timestamp is None:
timestamp = str(int(time.time()))
# 生成安全签名
sha1 = SHA1()
ret, signature = sha1.getSHA1(
self.m_sToken, timestamp, sNonce, encrypt)
if ret != 0:
return ret, None
xmlParse = XMLParse()
return ret, xmlParse.generate(encrypt, signature, timestamp, sNonce)
def DecryptMsg(self, sPostData, sMsgSignature, sTimeStamp, sNonce):
# 检验消息的真实性,并且获取解密后的明文
# @param sMsgSignature: 签名串,对应URL参数的msg_signature
# @param sTimeStamp: 时间戳,对应URL参数的timestamp
# @param sNonce: 随机串,对应URL参数的nonce
# @param sPostData: 密文,对应POST请求的数据
# xml_content: 解密后的原文,当return返回0时有效
# @return: 成功0,失败返回对应的错误码
# 验证安全签名
xmlParse = XMLParse()
ret, encrypt = xmlParse.extract(sPostData)
if ret != 0:
return ret, None
sha1 = SHA1()
ret, signature = sha1.getSHA1(
self.m_sToken, sTimeStamp, sNonce, encrypt)
if ret != 0:
return ret, None
if not signature == sMsgSignature:
return WXBizMsgCrypt_ValidateSignature_Error, None
pc = Prpcrypt(self.key)
ret, xml_content = pc.decrypt(encrypt, self.m_sReceiveId)
return ret, xml_content
# todo, 填入自己上面网页生成的token
Token = ''
# todo, 填入自己上面网页生成的EncodingAESKEY
EncodingAESKEY = ''
# todo, 填入自己的的CompanyId
CompanyId = ''
wxcpt = WXBizMsgCrypt(Token, EncodingAESKEY, CompanyId)
def decode_url_wechat(msgSig, timeStamp, notice, echoStr):
ret, sEchoStr = wxcpt.VerifyURL(msgSig, timeStamp, notice, echoStr)
if(ret != 0):
return("ERR: VerifyURL ret: " + str(ret))
return sEchoStr
def decode_msg(msgSig, timeStamp, notice, dat):
ret, Msg = wxcpt.DecryptMsg(dat, msgSig, timeStamp, notice)
if ret != 0:
return ret
return Msg
def assamble_res_data(msg, msgId, AgentID, nonce):
timestamp = int(round(time.time()*1000))
respData = "<xml><ToUserName>%s</ToUserName><FromUserName>admin</FromUserName><CreateTime>%s</CreateTime><MsgType>text</MsgType><Content>%s</Content><MsgId>%s</MsgId><AgentID>%s</AgentID></xml>" % (
CompanyId, timestamp, msg, msgId, AgentID)
ret, sEncryptMsg = wxcpt.EncryptMsg(respData, nonce, timestamp)
if(ret != 0):
return "ERR: EncryptMsg ret: " + str(ret)
return sEncryptMsg
2.1.4 整体项目
此处填好上述保存的参数,保存为py文件,例如clipper.py
# -*- coding: utf-8 -*-
import xml.etree.cElementTree as ET
from pydantic import BaseModel
from fastapi import FastAPI, Request, Response
import requests
import warnings
import re, time, random, string, os, requests, json, html2text
from webdav3.client import Client
from webdav3.exceptions import LocalResourceNotFound
from readability import Document
from decode import assamble_res_data, decode_msg, decode_url_wechat
warnings.filterwarnings("ignore")
app = FastAPI() # 对象app
class Item(BaseModel):
text: str
class Clipper:
def __init__(self):
# webdav参数
self.webdav_hostname = r''
self.webdav_login = ''
self.webdav_password = ''
# easyimage图床
self.imgurl = r''
self.token = r""
self.path = os.getcwd()
# 1 剪藏网页
def mdclipper(self, s):
s = str(s)
if 'http' not in s:
print('请输入正确网址')
return '请输入正确的网址'
else:
# 提取网址
print('正在提取网址')
link = re.findall(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*(),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', s)
url = link[0]
headers = {
'Connection': 'close',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.42'
}
response = requests.get(url, headers=headers)
contents = response.content.decode('utf8')
doc = Document(contents)
markdown = html2text.html2text(doc.summary(html_partial=True))
# 删除空的图片引用
markdown = markdown.replace('![]()', '')
mdname = '{}.md'.format(doc.title()) # md的文件名
return markdown, mdname
# 2 判断文件中是否有图片,有则返回True,没有则返回False
def judge(self, md_content):
# 图片的下载地址
img_patten = r')|<img.*?src=['"](.*?)['"].*?>'
img_urls = re.findall(img_patten, md_content)
if len(img_urls) != 0:
return True
else:
return False
# 3 处理图片
## 3.1 提取图片链接(建立在3中返回为True的情形下)
def process_md(self, md_content):
# 图片的下载地址
img_patten = r')|<img.*?src=['"](.*?)['"].*?>'
img_urls = re.findall(img_patten, md_content)
# markdown插入的图片格式
link_pattern = r'()|(<img.*?src=['"].*?['"].*?>)'
md_links = re.findall(link_pattern, md_content)
# 提取出有效信息
for i in range(len(md_links)):
md_links[i] = md_links[i][0] # file_name为文件储存路径及文件名
for i in range(len(img_urls)):
img_urls[i] = img_urls[i][0] # img_url为图片链接,
return img_urls, md_links
## 3.2 下载图片
def download_img(self, url):
t = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))
s = ''.join(random.sample(string.ascii_letters + string.digits, 8))
file_name = '{}-{}.jpeg'.format(t, s)
# 下载图片
res = requests.get(url)
with open(file_name, 'wb') as f:
f.write(res.content)
# 返回图片名称
return file_name
## 3.3 保存图片名称为列表
def createimglist(self, img_urls):
imglist = []
for i in img_urls:
name = self.download_img(i)
imglist.append(name)
return imglist
# 4 上传到自建图床imgurl
def sendImg(self, img_name, img_type="image/jpeg"):
with open(img_name, 'rb') as f:
f_abs = f.read()
url = self.imgurl # 自己想要请求的接口地址
body = {
"image": (img_name, f_abs, img_type)
}
data = {
"token": self.token
}
response = requests.post(url=url, files=body, data=data)
content = response.content.decode('utf-8')
# 将转换出来的字符串转换成字典,方便提取内容
content = json.loads(content)
print(content)
url = content['url']
t = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))
url = ''.format(t, url)
return url
# 5 删除图片和md文件
def delete(self):
for root, dirs, files in os.walk(self.path):
for name in files:
if name.endswith(".jpeg") or name.endswith(".md"): # 填写规则
os.remove(os.path.join(root, name))
# 7 上传到webdav
def upload(self, file_name):
options = {
'webdav_hostname': self.webdav_hostname,
'webdav_login': self.webdav_login,
'webdav_password': self.webdav_password,
'disable_check': True, # 有的网盘不支持check功能
}
client = Client(options)
# 我选择用时间戳为备份文件命名
try:
# 写死的路径,第一个参数是网盘地址
client.upload(file_name, self.path + '/' + file_name)
# 打印结果,之后会重定向到log
print('正在上传:' + file_name)
except LocalResourceNotFound as exception:
print('An error happen: LocalResourceNotFound ---' + file_name)
def mainclipper(self, url):
md = self.mdclipper(url)
if isinstance(md,str):
return md
else:
mdname = md[1]
mdcontent = md[0]
if not self.judge(mdcontent):
with open(mdname, 'w+', encoding='utf-8') as file:
file.write(mdcontent)
# 上传文件到webdav
self.upload(mdname)
# 删除md文件
self.delete()
return '剪藏成功,文件名为:{}'.format(mdname)
else:
img = self.process_md(mdcontent)
# 图片的下载地址
img_urls = img[0]
# 待替换的图片链接
md_links = img[1]
# 获得图片名称列表
imglist = self.createimglist(img_urls)
urls = []
for i in imglist:
# 传入文件名称,自动生成路径上传至图床
res = self.sendImg(i)
urls.append(res) # 获得符合markdown格式的图片链接
for i in range(len(urls)):
mdcontent = mdcontent.replace(md_links[i], urls[i])
# 保存文件
with open(mdname, 'w+', encoding="utf-8") as f:
f.write(mdcontent)
# 上传文件到webdav
self.upload(mdname)
# 删除md文件
# 删除图片
self.delete()
return '剪藏成功,文件名为:{}'.format(mdname)
clipper = Clipper()
def send2wechat(message):
AgentId = ''
Secret = ''
CompanyId = ''
# 通行密钥
ACCESS_TOKEN = None
# 如果本地保存的有通行密钥且时间不超过两小时,就用本地的通行密钥
if os.path.exists('ACCESS_TOKEN.txt'):
txt_last_edit_time = os.stat('ACCESS_TOKEN.txt').st_mtime
now_time = time.time()
if now_time - txt_last_edit_time < 7200: # 官方说通行密钥2小时刷新
with open('ACCESS_TOKEN.txt', 'r') as f:
ACCESS_TOKEN = f.read()
# print(ACCESS_TOKEN)
# 如果不存在本地通行密钥,通过企业ID和应用Secret获取
if not ACCESS_TOKEN:
r = requests.post(
f'https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={CompanyId}&corpsecret={Secret}').json()
ACCESS_TOKEN = r["access_token"]
# print(ACCESS_TOKEN)
# 保存通行密钥到本地ACCESS_TOKEN.txt
with open('ACCESS_TOKEN.txt', 'w', encoding='utf-8') as f:
f.write(ACCESS_TOKEN)
# 要发送的信息格式
data = {
"touser": "@all",
"msgtype": "text",
"agentid": f"{AgentId}",
"text": {"content": f"{message}"}
}
# 字典转成json,不然会报错
data = json.dumps(data)
# 发送消息
r = requests.post(
f'https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={ACCESS_TOKEN}', data=data)
# print(r.json())
@app.post("/")
async def predict(request: Request):
msg_signature = request.query_params['msg_signature']
timestamp = request.query_params['timestamp']
nonce = request.query_params['nonce']
databyte = await request.body()
data = databyte.decode("utf-8")
# 此处用到的也是上面的那个解密方法
ret = decode_msg(msg_signature, timestamp, nonce, data)
ret = str(ret, encoding='utf-8')
xml_tree = ET.fromstring(ret)
timestamp = xml_tree.find("CreateTime").text
msgId = xml_tree.find("MsgId").text
agentID = xml_tree.find("AgentID").text
msg_type = xml_tree.find("MsgType").text
content = '解析失败'
if msg_type == 'text':
content = xml_tree.find("Content").text
elif msg_type == 'image':
content = xml_tree.find("PicUrl").text
# todo, 自定义函数,用于针对发来的信息做相应回复
res = clipper.mainclipper(content)
# send2wechat(res)
res = assamble_res_data(res, msgId, agentID, nonce)
return Response(content=res)
2.2 Docker部分
2.2.1 Dockerfile
此处需注意python的版本,经试验,很多更高的版本不支持pycrypto的安装,很容易报错,指定python:3.8.9能够顺利通过pycrypto的安装。
该部分需要修改的参数只有1111,即选择自行选定的端口号。
FROM python:3.8.9
RUN python3 -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip && pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fastapi uvicorn pycrypto requests webdavclient3 html2text readability readability-lxml
COPY ./ ./
EXPOSE 1111
CMD [ "uvicorn", "serviceAPI:app", "--host", "0.0.0.0", "--port", "1111"]
2.2.2 执行代码
2.2.3 建立镜像
cd到存放三个文件的文件夹,执行如下命令
docker build . -t clipper
2.2.2 建立容器
docker run --restart=always --name=clipperserver -d -p 1111:1111 clipperserver
3 接收消息服务器配置
3.1 云服务器方式的实现
本文采用阿里云服务器进行演示:
进入阿里云官网-控制台-轻量应用服务器
 轻量应用服务器
轻量应用服务器
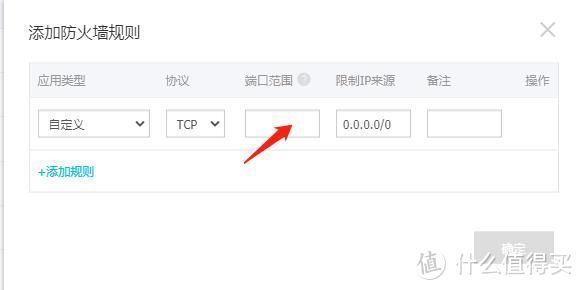
点击防火墙-新建规则
 防火墙-新建规则
防火墙-新建规则
填入刚刚选择的容器的端口号
 设置端口号
设置端口号
保存即可,那么现在的接收消息服务器地址即为http://服务器ip:端口号/(最后一个/不要忘了填)
3.2 本地服务器通过frp方式进行实现
3.2.1 配置frps服务器
3.2.1.1 云服务器
1、拉取frps
docker pull snowdreamtech/frps
2、设置配置文件
配置文件(xxxx的部分均自行填写):
[common]
bind_addr=0.0.0.0
bind_port = 8000
token=xxxxxx
vhost_http_port = 80
vhost_https_port = 443
dashboard_port = 7500
dashboard_user = xxxx
dashboard_pwd = xxxx
通过ssh进入云服务器
输入:vi /mnt/docker/frp/frps/frps.ini
粘贴上面的配置文件(通常鼠标右键即可粘贴)
输入::wq
3、启动容器
输入如下代码启动docker容器:
docker run -d --restart=always -p 8000:8000 -v /mnt/docker/frp/frps/frps.ini:/etc/frp/frps.ini --name frps snowdreamtech/frps
3.2.1.2 本地服务器
1、拉取frpc
docker pull snowdreamtech/frpc
2、设置配置文件
配置文件(xxxx的部分均自行填写):
[common]
server_addr = 云服务器ip
server_port = 8000
token = xxxxxxx # 对应的token
[clipper]
type = tcp
local_ip = 127.0.0.1 # 或者填写本地服务器的内网ip
local_port = xxxx # 本地建立docker容器的端口号
remote_port = xxxxx
通过ssh进入本地服务器
输入:vi /mnt/docker/frp/frpc/frpc.ini
粘贴上面的配置文件(通常鼠标右键即可粘贴)
输入::wq
3、启动容器
输入如下代码启动docker容器:
docker run -d --restart=always -p 8000:8000 -v /mnt/docker/frp/frpc/frpc.ini:/etc/frp/frpc.ini --name frpc snowdreamtech/frpc
4、云服务器防火墙放行
参照上述设置,放行对应的端口号,即remote_port填写的端口号
5、总结
该种方案导出的接收消息服务器地址即为http://云服务器ip:remote_port/
3.3 本地自有公网ip的实现
默认已经通过ddns绑定了域名,后续可能会更新通过python方式实现ddns解析到域名
1、路由器设置端口转发
进入路由器的配置页面,找到端口转发,ip填你的服务器ip地址,内网端口与转发的端口均填上述自行建立的docker容器的端口号。
2、总结
该种方案到处的接收消息服务器地址即为http://域名:转发的端口号/
3.4 调试自建的api
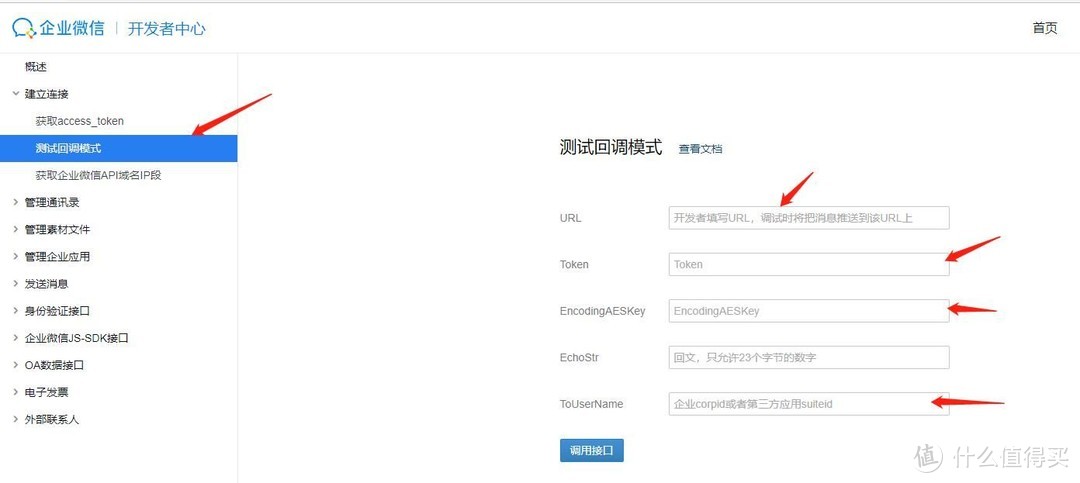
想要设置api接收,就必须先通过api的调试
进入工具页面:工具 - 企业微信开发者中心 (qq.com)
点击建立回调模式,url填入刚刚导出的api,其他的按照上述内容进行填写,EchoStr可以随便拿一个网址或者字符串进行测试
 测试api
测试api
若最终通过,显示成功,就可以进入最后一步。
3.5 完成项目
填入对应的api,后面两个一定要与最前面填写进py文件的完全一致,然后点击保存,即可在微信中进行测试了
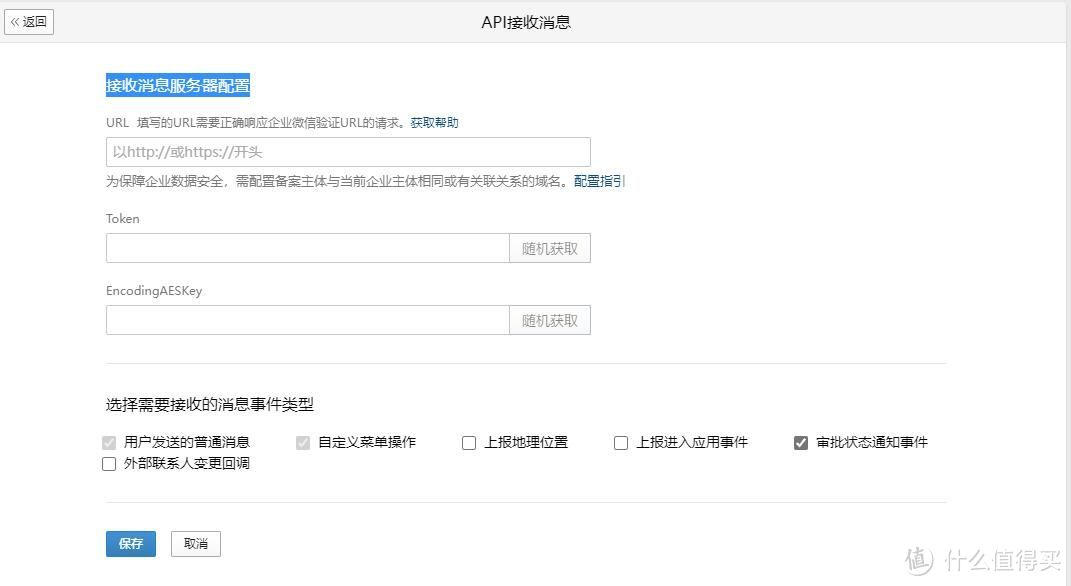 done
done
4 成果展示
输入不包含url的字符串,就会提示请求输入正确的网址
 不包含url的字符串
不包含url的字符串
输入不包含图片的网页,直接剪藏进去obsidian的剪藏的文件夹中供后续归类
 不包含图片的网页
不包含图片的网页
输入包含图片的网页,就自动上传图片,替换md文件中的图片链接为本地图床链接,并上传到obsidian的剪藏的文件夹
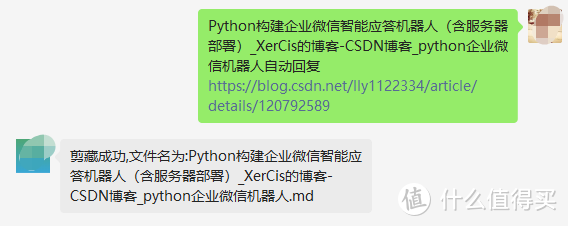 包含图片的网页
包含图片的网页
5 结语
由于本人水平有限,还有很多需要改进的地方还请大家多多提供建议。
此外,本文未经本人同意禁止转载,侵权必究,毕竟学的就是这个玩意。
作者声明本文无利益相关,欢迎值友理性交流,和谐讨论~

















祥子1986
校验提示文案
拉德布鲁赫信徒
校验提示文案
祥子1986
校验提示文案
拉德布鲁赫信徒
校验提示文案