
































































312
127
可乐漫画IT小课堂 篇二:连机器都在学习,你还不赶紧学一下?
2019-10-15 14:14:54
2点赞
7收藏
1评论
第一讲我们简单聊了有关人工智能的一些基础问题。但创造出人工智能只是一个目的,就好像“我要有钱”。具体怎么有钱呢?方法很多,可以去上班,可以炒股票,也可以在地铁站边上搞手机贴膜……而目前实现人工智能的方法中,最流行的就是机器学习(Machine Learning,ML)。
什么是机器学习?
机器学习这个名词儿比起人工智能就要生僻多了,广场舞大妈多半没听说过,能说得出来的基本都是理工科背景,说不定还念过蓝翔技校。
那么机器学习又是什么呢?现在的机器学习界普遍沿用一位名叫Tom M. Mitchell的牛人的说法。这位老兄曾经是卡耐基·梅隆大学(CMU)机器学习专业的主任。CMU我就不多做介绍了,在理工科尤其是计算机专业领域是如雷贯耳的存在。

这个定义的原文表述我就不说了,说出来只有让人徒增烦恼。不过我可以大概用人话翻译一下——所谓的机器学习,就是指让某个电脑程序通过不断的积累经验,把一件事情做得越来越好。
我仿佛听见你隔着屏幕说了一句“Are you joking?”

没错,听上去有点Low,我知道。很多理工科世界很高深的表述一旦翻译成人话都会显得有点Low,让外行人觉得理工男尽吃人饭不干人事。不过事实上,有许多事情说起来越简洁,稍微深究一下的话就会变得越复杂。比如“让领导满意”,机器学习大概也属于这一范畴。
如果稍微往下深究一点,机器学习的方法大概包含以下几个特征:
1. 不需要明确规则和传统的方法不同,如果你需要用机器学习的方法让一个电脑程序完成一件任务,比如判断一张照片上的人是不是你家隔壁的老王,并不需要告诉它这件事情具体要怎么做(比如告诉它老王是麻子脸单眼皮鹰钩鼻蛤蟆嘴)。程序会通过学习自己来总结规则,并且它的规则往往和你不同。这是机器学习的方法与传统方法最显著的区别。

2. 需要一定的数据用来作为学习的对象(术语叫做训练样本)
尽管你不需要告诉程序隔壁老王长什么样,但你需要提供给你的程序一些老王的照片,并且告诉它这就是隔壁老王。这些照片最好包含老王不同角度、发型、表情的形象。你还要给程序另外一些其他人甚至动物的照片,并告诉它这些不是老王。这个过程叫做训练。

3. 完成任务的质量能够随着训练过程而不断提高
一开始,当你的程序只学习了十几张老王的照片,它可能会把某张它没见过的老王的照片误认为是一条狗,或者反过来把一条狗的照片误认为是老王。但当它学习了几百张老王的照片之后,基本上就不会犯这种错误了。等到它学习了几千张老王的照片之后(这位老王多半不是王力宏就是王宝强,否则哪有人会给他拍那么多照片),甚至能够一眼认出男扮女装的老王或者十几年前的老王,连你这个人类都没这种水平。

如果电脑程序完成某个任务的方法符合以上特征,那么就可以算作是机器学习。那么你要问,这算不算智能?
IT男回答你,你看,我们的程序通过学习解决了一个非常实际的问题,让你家的摄像头在隔壁老王靠近家门的时候能够自动认出他来,并且向你发出警报,维护了你的家庭稳定与和谐。
而且,今后如果你对门搬来了老李,只需要给我们的程序再学习一些老李的照片就搞定,程序都不用重新写。这个还不算智能?
课讲到这里,你应该对机器学习有了一个模糊的认识,和IT界以外的朋友吹吹牛大概也够了。
不过既然我们号称IT课堂,肯定不能仅仅满足于这种程度。毕竟除了认出隔壁老王,机器学习能做的事情还有很多,做不同的事情用的学习方法也不一样。
下面我们稍微展开一下,浅尝辄止。
机器学习的分类
有监督学习(Supervised Learning),包括分类,回归分析等
无监督学习(Unsupervised Learning),包括聚类,异常分析,主成分分析等
强化学习(Reenforced Learning),有点复杂,应用也比较少,暂时把它排除在外
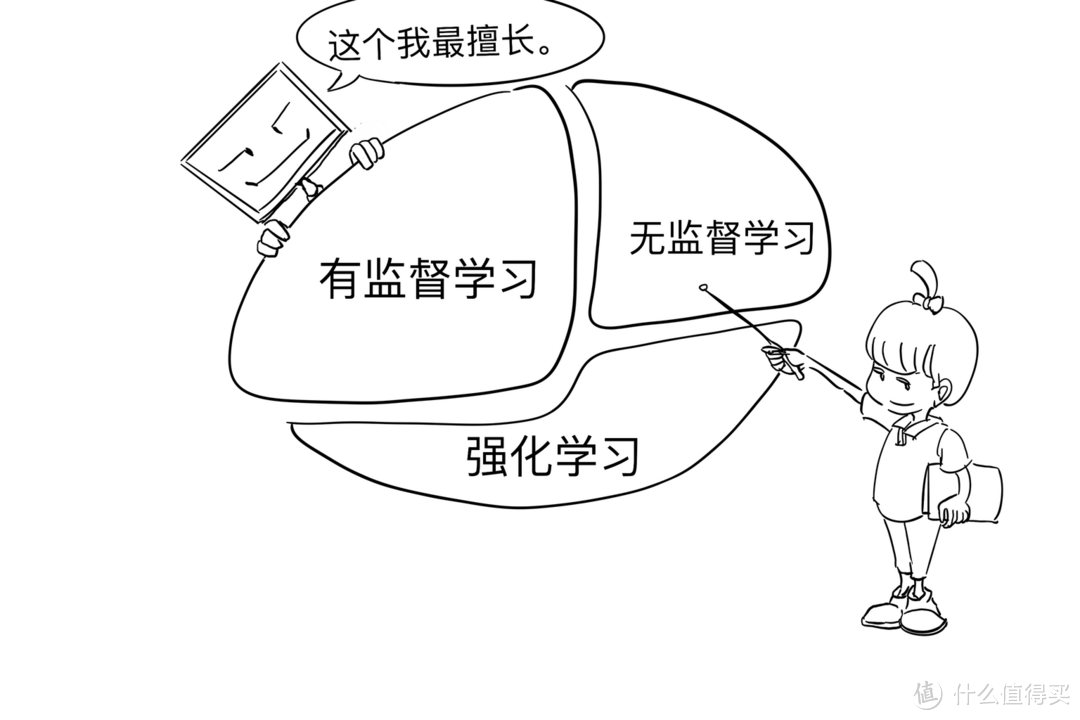
聪明人看到这里肯定会想,这个简单啊,假如把电脑比作咱们家娃,有监督学习就是老母亲陪读,天天盯着他做作业,无监督学习就是放羊,佛系带娃,纯靠自觉呗。
嗯,所谓聪明反被聪明误,说的就是你。
事实上,如果非要把电脑比作你家的娃,那么有监督学习和无监督学习的主要区别是--有没有在做题的时候告诉娃,这题的正确答案是什么。
告诉正确答案的,就是有监督学习
不告诉正确答案的,就是无监督学习。

先说说有监督的学习。
分类(Classification)
我们回来看隔壁老王的那个程序。你在训练程序的时候给它看了好多老王的照片,并告诉它“丫就是老王”,这就是学习的时候给了正确答案。
给它看对门老李的照片,你也得告诉它“这个是老李”,如果你还需要程序认出更多的人,你在给它看照片的同时,都要同时告诉它,“这是王俊凯”,“这是志玲姐姐”,“这是苍老师”。
 分类的学习阶段
分类的学习阶段
这样学习完了之后,它在看见一张以前没见过的照片时才能告诉你这是不是它所见过的某个人。
 学习完毕的应用阶段
学习完毕的应用阶段
所以这个就叫做有监督学习。而这个隔壁老王程序所完成的任务,是有监督学习的一个重要分支,叫做“分类”。
回归分析(Regression Analysis)
除了分类之外,有监督学习还有能完成另一种任务,比如通过学习历史上的数据来预测一下明天的大盘指数或者明年的房价之类。这种任务叫做“回归分析”,以后的课上还会讲。虽然听上去超级高端,但是冷静一下——对房价之类复杂的事情要做到准确的回归分析是很难的,否则我为什么还没开上宾利呢?
 回归分析
回归分析
说完了有监督学习,再来说说无监督学习。
所谓无监督,就是你并不会告诉电脑程序正确的答案是什么,因为其实很可能你自己也不知道。那么问题来了,连人都不知道答案的问题,你让机器怎么学?
不用紧张,拼乐高或者写作文之类的不也没有标准答案,你家娃还不是学的杠杠的?
不过无监督学习并不是要让电脑程序发挥想象力,而是用来处理那些你事先不清楚规律的事情,让程序通过学习自己发现规律并把这个规律告诉你。
聚类(Clustering)
 聚类
聚类
再举个例子,你发现家周围老有那么一些你不认识的人在晃荡,形迹可疑。你家门口的摄像头自动拍下了几千张这些人各种角度的照片。
为了弄清楚到底有多少人觊觎你家的财产,你把这些照片全都扔给电脑程序,让它帮你鉴定一下这几千张照片到底分属多少个不同的人。
既然这些人你一个也不认识,当然也就没法告诉程序这张照片是老王,那张是老李,所有的照片都是没有确定答案的。所以这是典型的无监督学习。
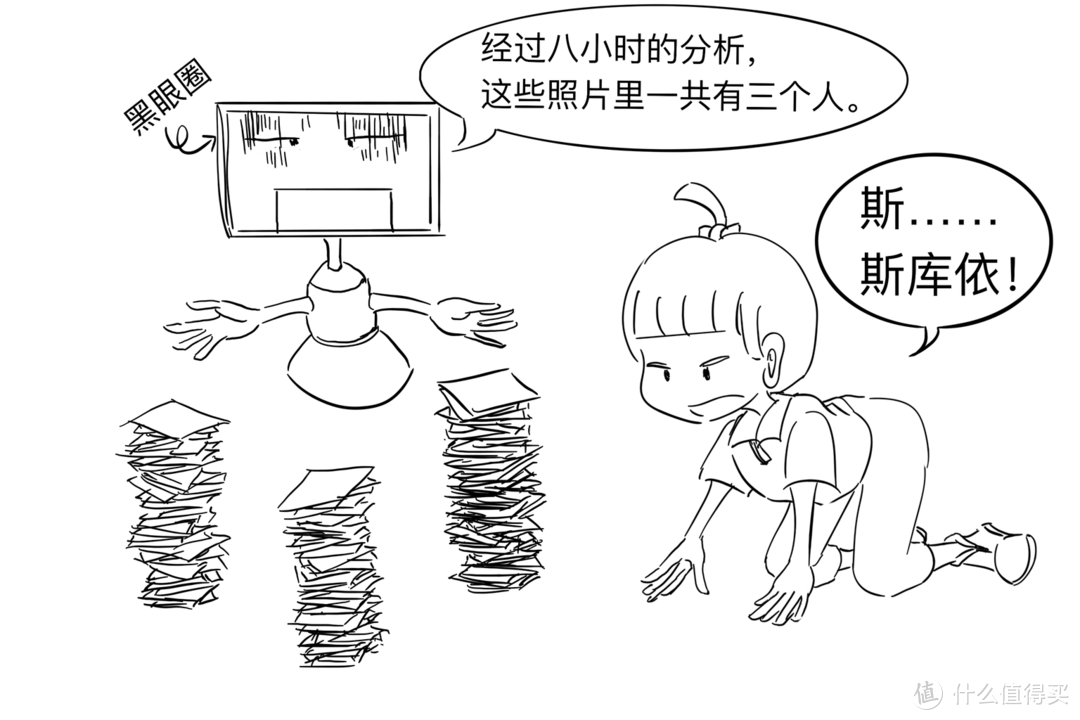
在学习完毕之后,电脑告诉你这些照片分别是五个不同的人,其中甲的照片350张,乙的照片560张……这项任务属于无监督学习领域一个主要的分支,叫做“聚类”。
除了聚类,无监督学习还可以做异常检测(Outlier Detection)和主成分分析(Principle Component Analysis,PCA)等等其他任务,由于篇幅有限,就不多介绍了。
总的来说,无监督学习比有监督学习更难得到让人满意的结果,就好像写作文拿高分永远比数学题更难一样道理(文科不服来辩)。但因为这个世界上存在太多的数据我们不知道它们的规律,所以无监督学习的存在依然有很大的价值。
说了那么多,你说嗯,机器学习有很多好处,可以不用教电脑怎么干事儿,让它自己学,还能越干越好。但到底怎么让机器有这个学习的能力呢?他又不是我的娃,我跟它说一句宝贝儿赶紧去做作业,它就能听我的。

没错,要实现机器学习,必须得有码农写许许多多的代码,然后编译成一个专门用来做机器学习的程序才行。
不过,码农们并不需要自己来想怎么写这些程序(绝大多数码农想破头也想不出来),也不需要从头来写这些程序,因为在以往的几十年中,许多科学家和研究人员已经总结了不少能够用做机器学习的现成方法,并且已经被一些大的IT公司(比如谷歌、微软)做成了软件库。
使用现成的软件库,只需要自己写很少的代码,就能快速编写出一个能够进行机器学习的程序。这些现成的方法,称作模型(Model)。

最早的机器学习模型出现于1958年的美国康奈尔航空实验室,叫做Perceptron(中文翻译为感知器) 。这个年代对于IT领域而言就好像是侏罗纪一样古老。可见机器学习(包括人工智能)并不是什么新鲜东西。
在那以后,科学家们根据不同的需要设计出了许许多多的机器学习模型,比如k近邻法(k-NN)、支持向量机(SVM)、决策树(Decision Tree)、朴素贝叶斯(Naïve Bayes),线性回归(Linear Regression)、人工神经网络(ANN)、k-均值(k-Means)、DBSCAN等等。
这些模型有些适合有监督学习,有些适合无监督学习,在各自所擅长的领域和无数的码农和攻城狮们死磕。
这堂课到这里讲完了。你今后在朋友们面前吹牛皮的时候应该能说清楚下面的问题:
什么是人工智能;
目前人工智能可以靠什么方法实现;
机器学习有哪些特点;
什么是有监督的机器学习和无监督的机器学习,以及
如何防范隔壁老王。
小编注:本文作者@ imeasy 是什么值得买生活家,他的个人自媒体信息为:
微信公众号:逸飞影话 ,微信搜索“YifeiPic”
扶持推广个人品牌是生活家新增福利,更多详细内容请了解生活家页面(https://zhiyou.smzdm.com/author/)。欢迎大家踊跃申请生活家,生活家中表现优异的用户还将有机会成为『首席生活家』,欢迎有着特别生活经验的值友们踊跃加入生活家大家庭!
















部川内酷
校验提示文案
部川内酷
校验提示文案