
















































































312
127
#NVIDIAStudio# RTX 30加速创意无需等待,AI助力事半功倍,比图灵效率提升两倍
2020-12-27 17:14:03
0点赞
0收藏
0评论
创作立场声明:综上所述,NVIDIA Ampere架构为GeForce RTX™ 30显卡带来了超强的性能与极高的效率,为用户提供了空前强大的游戏与生产力工具解决方案,确实是当下最值得升级的显卡产品。
《赛博朋克2077》终于如约上市了,不知道各位玩家有没有抢到心仪的RTX 30显卡呢?之所以NVIDIA这一代显卡如此受欢迎,一方面是因为性能提升幅度非常惊人、特别是在光追游戏大作中的表现更加成熟;另一方面就是价格大幅下调,“半价买上代旗舰”这样的性价比,谁不爱呢?那么,GeForce RTX™ 30系列显卡为何能做到如此大的提升?这首先就要从NVIDIA全新打造的Ampere架构相对Turing架构的进化说起。
GPU进化史上的奇迹!NVIDIA Ampere架构带来多项革命性升级
★安培VS图灵:SM单元大幅改进,效率巨幅进化!

要想提升GPU性能,只有提升频率和改进架构提升效率两个途径,不过单纯提升频率必然会带来功耗的激增,因此NVIDIAI在将制造工艺提升到8nm的前提下,也对新一代的Ampere架构进行了大刀阔斧的改进。
从图中可以看到,相对于第一代RTX显卡使用的Turing架构来讲,NVIDIA Ampere架构中全新设计的SM模块提供了两倍的FP32单元,每个时钟周期可以执行一次128bit FMA浮点运算操作,同时,增加的FP32单元在需要的时候也可以转为INT32单元,应对程序需求的方式更加灵活,效率也变得更高,这也是NVIDIA Ampere架构比Turing架构更加先进的革命性设计之一。
此外,NVIDIA Ampere架构相比Turing架构还增加了一倍的L1缓存带宽和一倍的缓存分区大小,NVIDIA Ampere的第二代RT Core和第三代Tensor Core还分别提供了两倍于Turing架构的三角形相交计算能力和稀疏矩阵计算能力。总而言之,NVIDIA Ampere架构相比Turing架构大幅改进了SM架构,从而带来了近乎翻倍的效率提升,这也是RTX 30系列显卡相比第一代RTX显卡的先天优越性所在。
★安培VS图灵:RT Core与Tensor Core全面升级,量变带来质变!
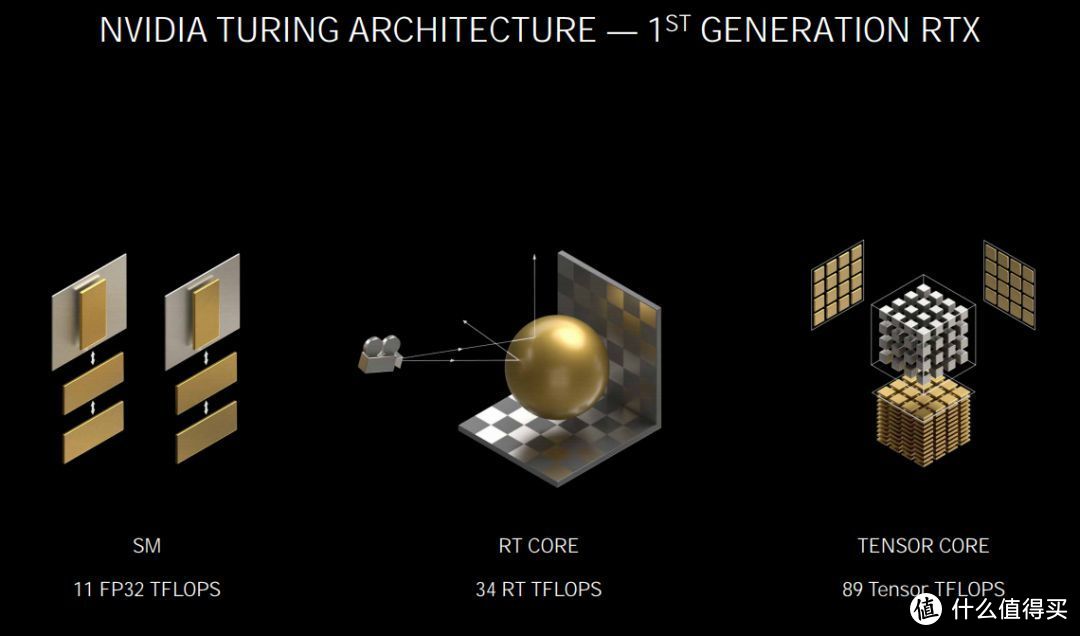

NVIDIA Ampere架构的SM单元、RT Core和Tensor Core都进行了升级,RT Core升级到了第二代,Tensor Core升级到了第三代

NVIDIA Ampere架构中的第二代RT Core可以同时高效实现光追和动态模糊计算
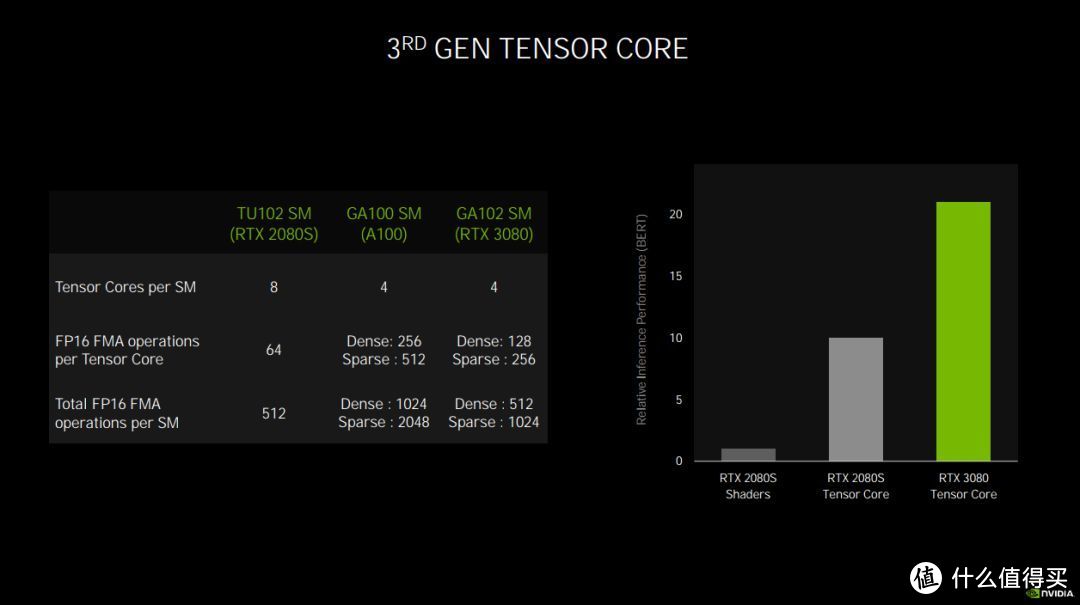
NVIDIA Ampere第三代的Tensor Core相比Turing架构的第二代Tensor Core性能高出一倍以上
前面我们也提到,从Ampere到 Turing,RT Core从第一代升级到了第二代,Tensor Core也从第二代升级到了第三代,除了前面提到的纯性能提升外,更高的性能也带来的更多的应用可能。NVIDIA Ampere架构的第二代RT Core由于架构的改进,现在可以同时实现高效的光追与动态模糊特效的计算,这就是一个量变到质变的表现,切切实实为玩家和设计师用户带来了新的体验和可能,这也是上代Turing架构RT Core无法做到的。NVIDIA Ampere架构的第三代Tensor Core部分,虽说每个SM单元的Tensor Core减少一半,但实际上的性能不降反升,从数据来看,效率相比第二代Tensor Core提升了一倍以上。第三代Tensor Core的性能大幅提升反映在游戏中就是DLSS效率突飞猛进,GeForce RTX™ 3090搭配最强悍的Ultra Performance DLSS模式甚至首次实现了8K分辨率下流畅运行光追游戏大作,这也是从Turing到Ampere为玩家体验带来的质的改变。
★安培VS图灵:每瓦性能几乎翻倍,能效比革命性进步!
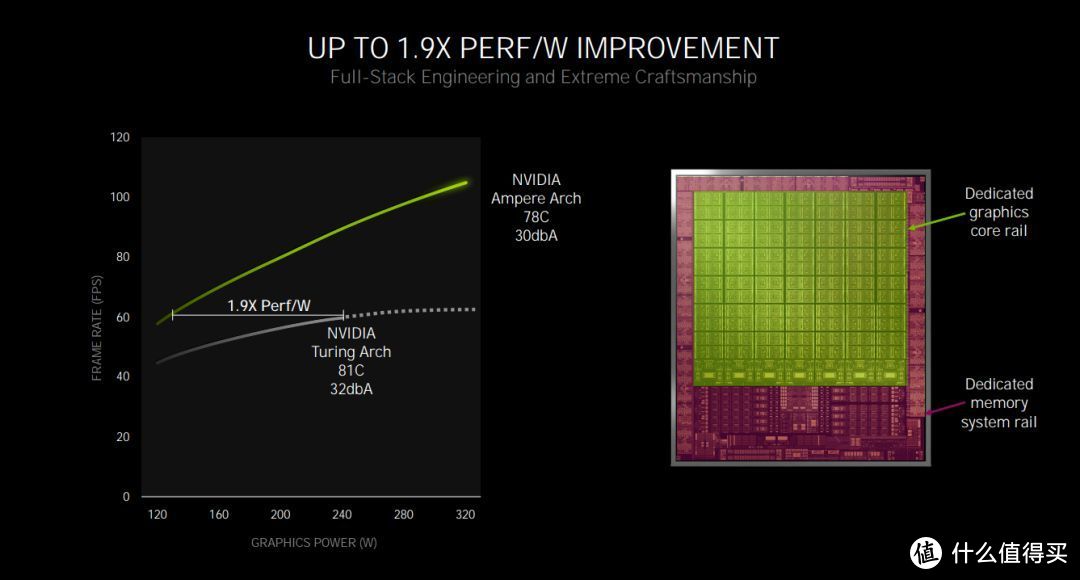
NVIDIA Ampere架构的每瓦性能约为Turing架构的1.9倍
从图中可以看到,Ampere架构的核心布局采用了新的设计,芯片中间区域是图形芯轨,周围区域则是存储系统芯轨,两块区域分离之后可以获得更高的芯片利用率与执行效率。因此,在每瓦性能方面,Ampere架构相对图灵架构几乎翻倍,此外,先进的8nm工艺也功不可没。温度和噪音方面,NVIDIA Ampere架构的GeForce RTX™ 30显卡在30dbA工作噪音下的温度为78℃,Turing架构的GeForce RTX™ 20显卡在32dbA的噪音下温度为81℃,而前者的游戏帧率几乎是后者的两倍,升级幅度非常明显。
★安培VS图灵:新一代GDDR6X显存加持,高分辨率游戏性能无可比拟

GeForce RTX™ 3090/GeForce RTX™ 3080首次采用GDDR6X显存,速率为GDDR6的两倍
NVIDIA Ampere架构的GeForce RTX™ 3090/3080显卡还有一个巨大的升级值得重点介绍,那就是使用了NVIDIA与美光合作开发的GDDR6X显存。由于GDDR6X显存采用了PAM4信号编码,也就是每个周期利用4个电平信号进行数据传输,效率相比GDDR6的两个电平信号大幅增加,从而带来了更高的显存数据带宽。这一点也是Turing架构的RTX 20显卡所不具备的。
★安培VS图灵:从性能到接口,首次全面满足8K输出需求

RTX 30系列显卡提供HDMI 2.1接口,可单数据线输出8K/60Hz HDR视频信号,同时还提供了对AV1的硬件解码加速,支持8K/60fps视频实时解码
视频输出方面,采用NVIDIA Ampere架构的RTX 30系列显卡首次提供了对HDMI 2.1接口的支持,可以实现单数据线8K/60Hz或者4K/120Hz的HDR画面输出。此外,RTX 30系列也是全球首批支持AV1硬件解码的显卡,可以流畅解码8K/60fps视频,为视频剪辑师用户提供了强大生产力支持。
其实,除了制造工艺、架构和硬件规格方面的大幅度升级,NVIDIA Ampere架构的GeForce RTX™ 30显卡还带来了大量实用的黑科技。
RTX 30显卡又增加了一大把实用黑科技
★NVIDIA REFLEX低延迟技术
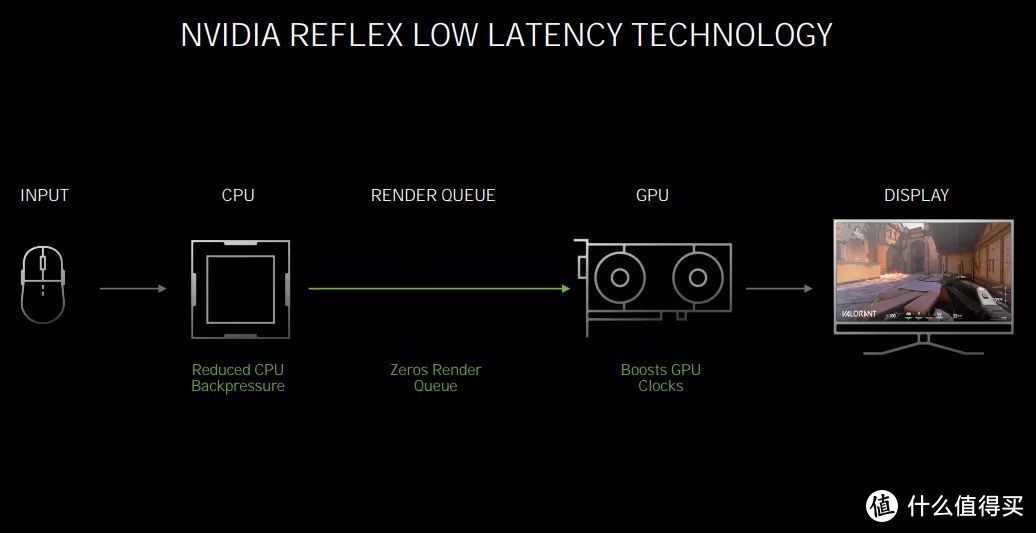
与RTX 30显卡一同登场的NVIDIA REFLEX低延迟技术可以提供更低的游戏画面与操作延迟,提升对战中的胜率
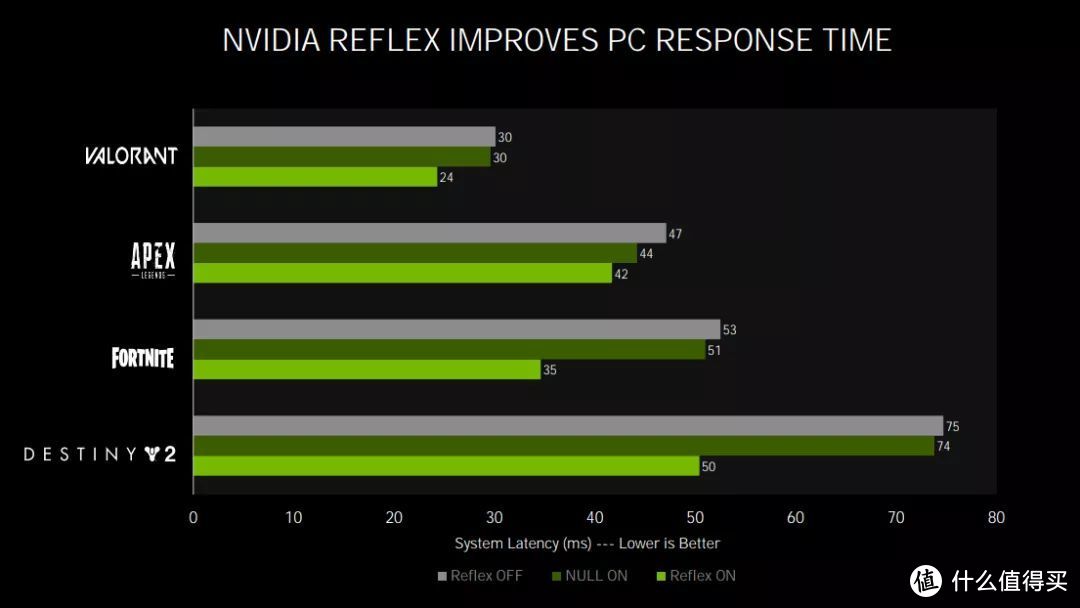
启用REFLEX技术的情况下,热门电竞游戏的系统延迟时间都得到了明显降低
NVIDIA REFLEX低延迟技术通过将渲染队列的延迟时间降低为0、大幅降低处理器负担、提升GPU频率来降低整个系统的延迟,让玩家在电竞游戏中的操作更加快捷、顺滑。当然,要达到最佳效果,也需要RTX 30显卡的Shader单元、RT Core、TENSOR Core同时加速来提供强大的运算能力。从统计数据来看,RTX 3080在开启硬件光追+DLSS+Async的情况下,响应速度是GeForce RTX™ 2080的1.9倍!此外,REFLEX低延迟技术还需要支持高刷新率的G-Sync电竞显示器来配合才能达到最佳效果。例如360Hz刷新率的G-Sync电竞显示器,而且这些显示器中还首次集成了可监测延迟的REFLEX硬件模块。同时,操控外设方面也需要支持REFLEX技术的电竞鼠标配合实现最好的低延迟操控体验,目前华硕、罗技、赛睿、雷蛇都有支持该技术的鼠标产品。
★RTX IO快速载入技术
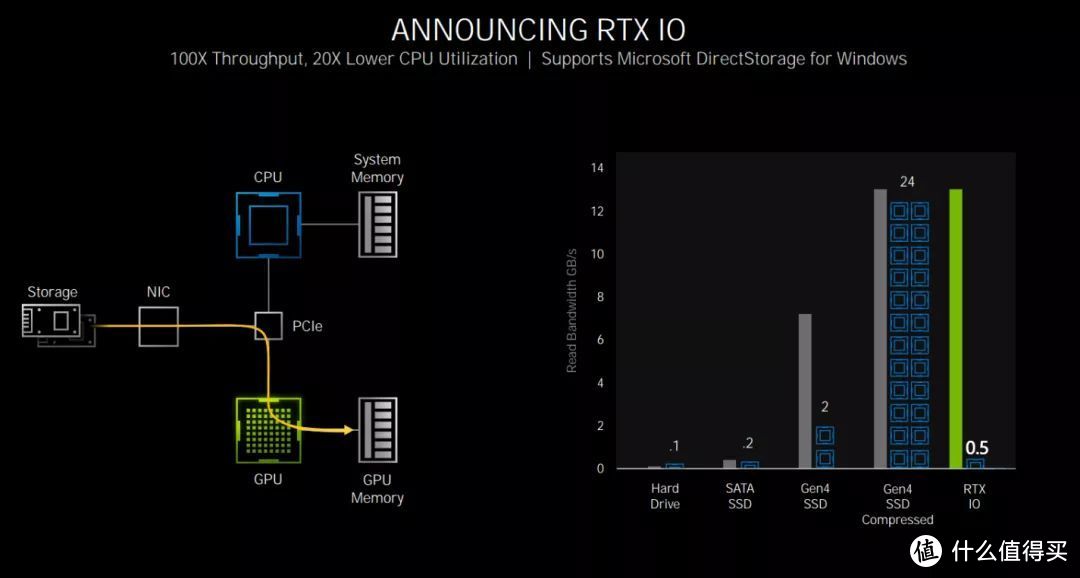
RTX IO技术可直接将压缩数据读取到显存,CPU占用率缩减为1/20、载入速度相较HDD提升百倍
针对大型游戏载入特别占处理器资源、效率较低的问题,NVIDIA推出了RTX IO技术,通过这项技术,就能让GPU来处理数据解压,从而大幅度降低CPU的占用率。从图上可以看到,在PCIe 4.0固态硬盘上达到同样读取速度的时候,如果采用传统的方式,会占用24个CPU核心,而采用RTX IO技术后,只需要占用0.5个CPU核心,这在游戏中就可以体现为载入地图数据和模型文件的时候更加流畅,避免卡顿。当然,这项技术不止可以用在游戏中,也可以用在需要载入大量素材文件的3D渲染工作中,获得更流畅的操作体验。要享受这项技术,需要游戏或应用软件支持微软的DirectStorage API,当然,也需要GeForce RTX™ 30系列显卡。
★基于RTX 30系列显卡的NVIDIA STUDIO

GeForce RTX™ 30系列显卡的高超算力为内容创作提供了强大的动力

GeForce RTX™ 3090高达24GB的显存可以轻松应对高细节几何建模、多应用3D渲染动画、8K RED EAW的AI剪辑等高运算量专业应用

在达芬奇视频剪辑中,GeForce RTX™ 3080的效率甚至超过了GeForce RTX™ 2080 SUPER的两倍
NVIDIA的NVIDIA STUDIO为设计师用户提供了效率极高的生产力解决方案,而搭载RTX 30系列显卡的NVIDIA STUDIO在性能和效率方面的表现更是空前强大。从官方提供的数据来看,RTX 3080在各种主流渲染器中的加速性能都远超GeForce RTX™2080 SUPER,在LUXMARK和V-Ray中甚至超过了GeForce RTX™ 2080 SUPER的两倍。视频剪辑部分,RTX 3080也表现出了惊人的性能,DaVinci测试中的成绩远远领先GeForce RTX™ 2080 SUPER,甚至有些项目几乎达到了GeForce RTX™ 2080 SUPER的2.5倍性能。
此外,我们知道很多复杂3D建模与高码率8K视频剪辑是非常吃显存的,而RTX 3090具备的24GB超大显存无疑是针对这些应用而来,为设计师用户提供更高效的解决方案。
★NVIDIA OMNIVERSE MACHINIMA

NVIDIA OMNIVERSE MACHINIMA可以让用户使用游戏素材打造电影级视频
NVIDIA OMNIVERSE MACHINIMA是基于GeForce RTX™ 30系列GPU强大计算能力打造的游戏叙事APP,能够让玩家利用现有的游戏素材,通过RTX 30显卡AI技术制作出电影级的视频。NVIDIA OMNIVERSE MACHINIMA可以从支持该技术的游戏中获取素材、工具,然后通过赋予材质、Audio2Face(声音转表情)、增加物理效果、AI采集动作,最后使用RTX光线追踪渲染从而制造出堪比电影画质的视频。
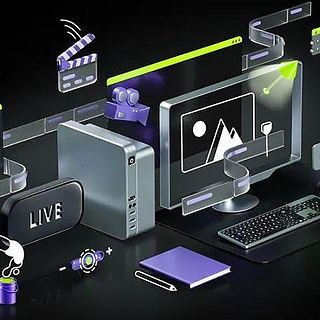
★NVIDIA BRODCAST
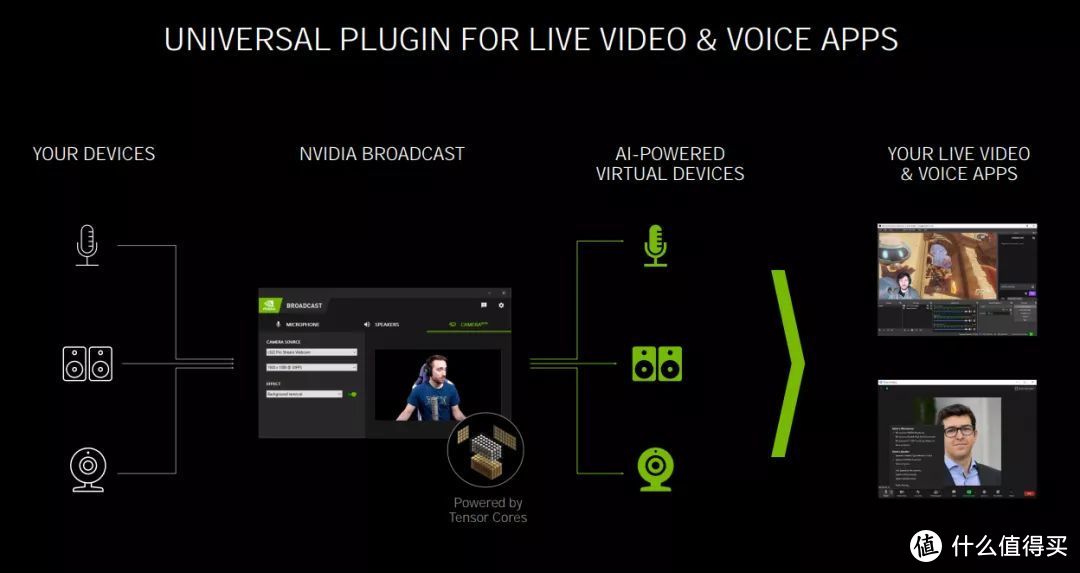
得益于GeForce RTX™ 30系列显卡强大的视频加速和AI计算能力,玩家可以轻松打造家庭工作室
NVIDIA BROADCAST工具可以为玩家提供强大的直播应用解决方案,它主要包括了音频降噪(降低录音的环境噪音)、虚拟背景(通过AI抠出人像,并提供各种直播时需要的虚拟背景)、摄像头自动构图(可以保证改变动态视频图像比例时,自动将目标位于视觉中央)等实用功能。从图上可以看到,麦克风、音箱(或耳机)、摄像头等设备连接到电脑后,通过NVIDIA BROADCAST工具可以被AI技术强化形成虚拟设备,从而获得各种强大的功能。虽说只要是RTX显卡都可以使用NVIDIA BROADCAST,但要达到最佳效果和流畅度,还是得搭配使用NVIDIA Ampere架构的RTX 30系列显卡。
综上所述,NVIDIA Ampere架构为GeForce RTX™ 30显卡带来了超强的性能与极高的效率,为用户提供了空前强大的游戏与生产力工具解决方案,确实是当下最值得升级的显卡产品。















