
























































40
56
英特尔Ultra 200系列处理器暨ROG Z890 HERO评测报告
2024-10-27 22:36:23
5点赞
8收藏
4评论
我在国庆前就拿到了Ultra 200 K全系列处理器+ROG Z890 HERO主板+CUDIMM内存,再加上前期摸索时间接近2个月,因此我在这篇文章上还是投入了很多时间和精力,所以测试内容比较多,完全阅读预计需要10分钟。
测试平台

Z790的测试平台是ROG Z790 APEX Encore,14900K分别测试了开启多核增强和Baseline的性能。
Z890测试平台为ROG Z890 HERO,全部开启多核增强。intel平台使用是龙神3 Extreme散热器。
X870平台使用默认的PBO设置,散热器使用的是Abee Function A360。
测试设置的选择原则是普通用户在不明显增加成本或者有明显技术门槛/挑体质就可以达成稳定的设置,在这个原则上实现性能的优化。
Z790/Z890平台在没有特别说明的情况下,内存使用的是金士顿16GB DDR5 6800 x 2超频8000 MHz,Zen 5平台设置为7600 MHz,参数统一为34-46-46-58,tREFI=32767。这样设置对于CPU/主板/内存的档次/体质没有什么要求,都可以轻松达成稳定的设置。
测试系统为Windows 11 24H2,新版的KB5041587更新改善了处理器的分支预测,对于intel和AMD处理器部分性能有明显的改善,但对于部分项目也有明显的负优化。
缩写说明 RPL Raptor Lake/ARL Arrow Lake
Arrow Lake的整体架构
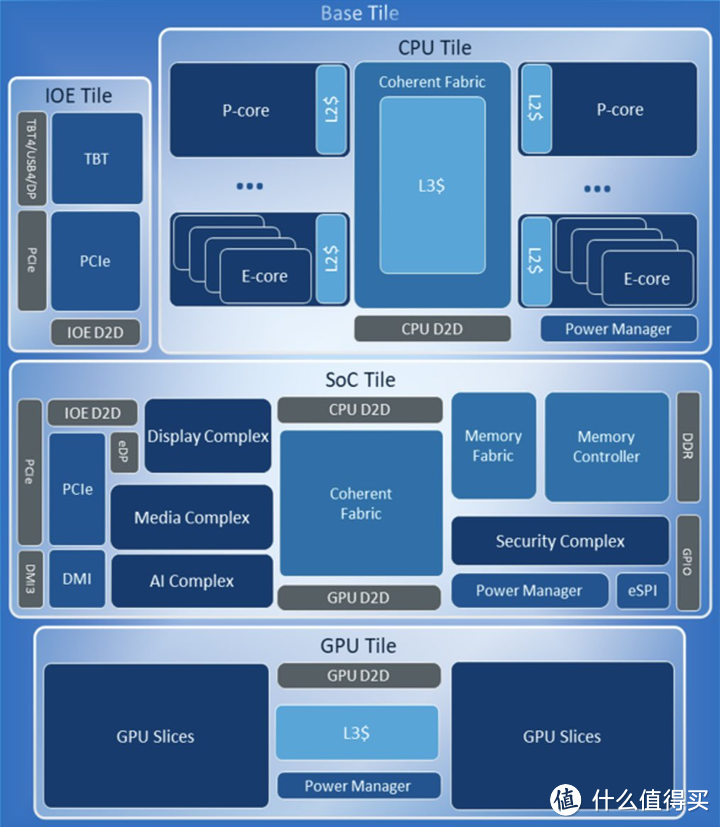
Arrow Lake基本可以说是Lunar Lake和Meteor Lake的混合体,内核架构是和Lunar Lake一样最新的Lion Cove和Skymont,但在整体设计上却还算沿用Meteor Lake的框架,使用3D Foveros,由多个不同工艺的Tile组成CPU,这样的好处能够使用不同工艺优化不同部分的性能和成本。ARL差不多可以说是MTL的皮,LNL的芯。

当然上面只是结构示意图,借用普普通通tony大叔的开盖图展示的实际布局还是有一些差别,TSMC N3B的计算核心靠上(蓝色),中间是TSMC N6的SoC Tile(黄色),下面的是TSMC N5的GPU Tile(绿色),左上和右下则是用来占位配平的dummy,它们由底部intel自己的22nm工艺基板互联。这样的布局CPU的核心热源会靠上,因此类似ROG 龙神 3 Extreme这样的散热器就自带了偏移扣具就能提供更好的散热效果。

其实ARL和MTL并不是intel首次在CPU上使用chiplet,10多年前的Haswell和Broadwell就曾经用过,Broadwell甚至还推出了支持超频的i7 5775C桌面处理器。

再来看看tony大叔的Dieshot,计算核心满规格包括8个P-core和16个E-core,但和LNL不一样ARL其依然还是通过ring环形总线连接。并且这次P-core和E-core改为交替排列,这可能是处于热管理或者是延迟优化的目的。P-core的L2缓存从2MB升级到3MB(移动版的LNL L2是2.5MB),285K L2缓存总容量3 x 8 + 4 x 4总计40MB,而L3缓存容量为36MB。
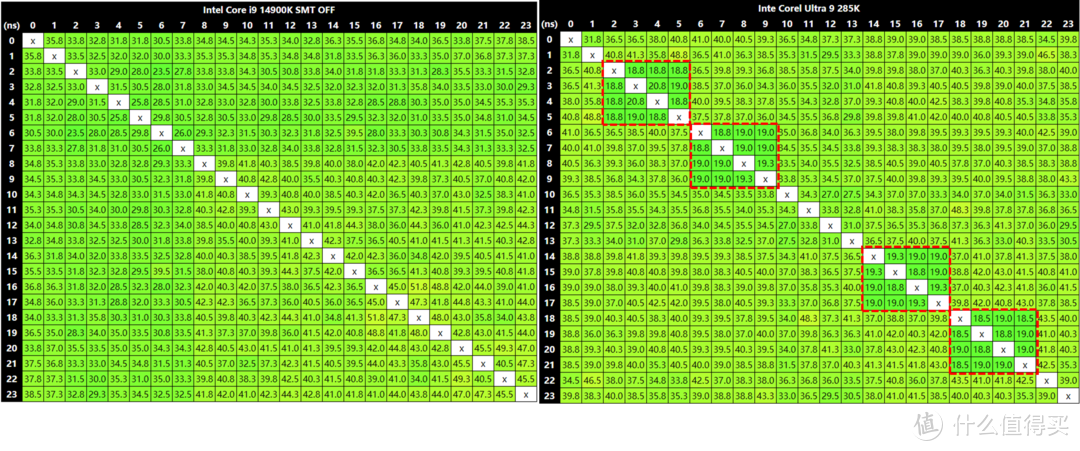
我使用MicroBenchX_v1.0.4进行C2C缓存一致性耗时测试,核心簇的排列也如上图那样P-core和E--core是交替排布。14900K的平均延迟是39.93ns,而285K的平均延迟为36.21ns。但这实际是因为同簇E-core是十字布局L2缓存互联拉低了延迟,实际其他部分的延迟要更高,这应该是uncore频率偏低导致。
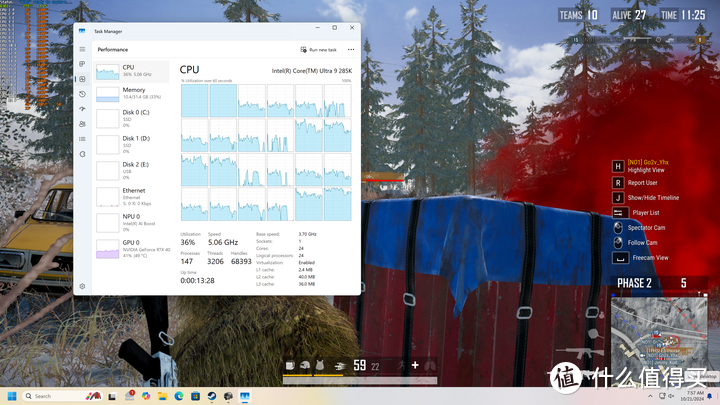
交替排列并没有影响系统对核心的调用,如吃鸡这样的实际负载游戏还是会优先满载使用P-Core,而E-core主要是处理后台或者外围任务,比如RTSS监视器和Capframe。
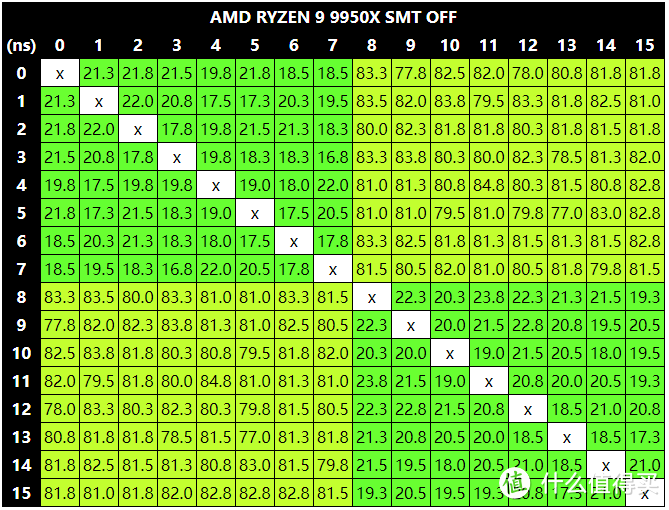
Zen 5平台在更新AGESA PI 1.2.0.2新版BIOS后,默认设置的跨CCD延迟降低了一半,但还是在80ns以上。因此Zen 4/Zen 5 Ryzen 9现在的游戏调用策略是仅使用高频的CCD0,9950x实际就是高频9700x,而9900x只是个高频9600x。
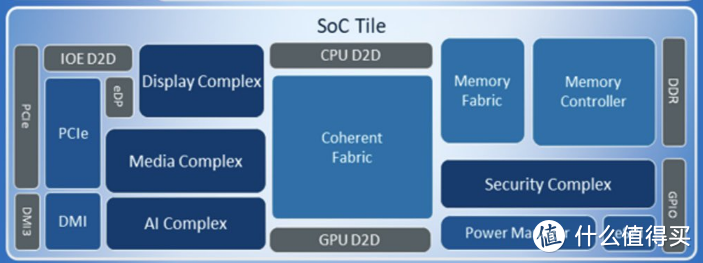
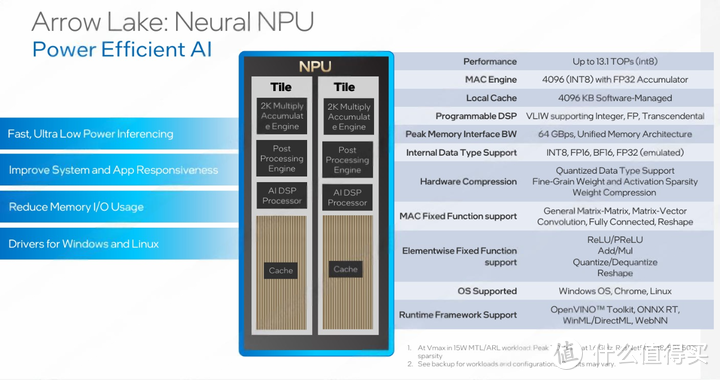
SoC Tile部分和MTL差不多,包含现实输出部分/视频解码/NPU/电源管理/安全模块/DMI/内存控制器和端口,另外需要注意的是ARL的内存控制器在SoC上而不是和计算核心一起,需要通过D2D进行通讯。
和MTL的SoC有点差别是没有LPE core,MTL在SoC挂LPE Core主要是为了移动平台待机和极低负载降低功耗,ARL-S台式机这个需求就不大,直接将E-core挂在ring上有更好通讯性能。
显示引擎部分居然支持完整的UHBR20,DP 2可以提供完整的80 Gbps带宽,这是目前NVIDIA/AMD消费级显卡办不到的。
Z790/Z890平台在没有特别说明的情况下,内存使用的是金士顿16GB DDR5 6800 x 2超频8000 MHz,Zen 5平台设置为7600 MHz,参数统一为34-46-46-58,tREFI=32767。这样设置对于CPU/主板/内存的档次/体质没有上面要求,都可以轻松达成稳定的设置。
SoC部分对于性能和密度需求不大,所以就采用的是TSMC N6工艺降低成本。

核显部分依然为MTL的LPG Xe架构,而不是LNL的Xe2,并且规模是MTL低配规格才4个Xe内核,64 EU,属于亮机卡范畴。这部分是采用的TSMC N5,主要是为密度进行优化。另外由于核显独立,这代KF的GPU部分也应该是dummy占位,多芯片设计是有利于优化成本的。
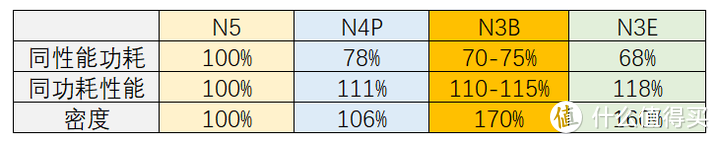
这次计算核心并没有采用intel自己的FAB的生产,而是台积电的N3B工艺。N3B其实台积电N3的分支工艺,在功耗和性能方面的表现比后来的N3E稍差,仅仅是晶体管密度更高。但N3B无论是功耗还是性能都还是比N4P更好一点,因此这是intel桌面处理器工艺在多年后首次领先AMD。
爆炸式扩张的核心规模
下面部分涉及一些微架构,可能会需要点专业知识,如果兴趣不大可以跳过继续阅读下面部分。
我们关注处理器性能,不能只看有几个核心/多少频率,相同频率的核心内部资源和规模不同性能也会有很大的差别。其实上代Redwood Cove相比Raptor Cove架构变化不太大,更多只是实验intel 4工艺和Tile的先进封装技术,而Lunar Lake这代P-Core和E-Core都是全新的架构。
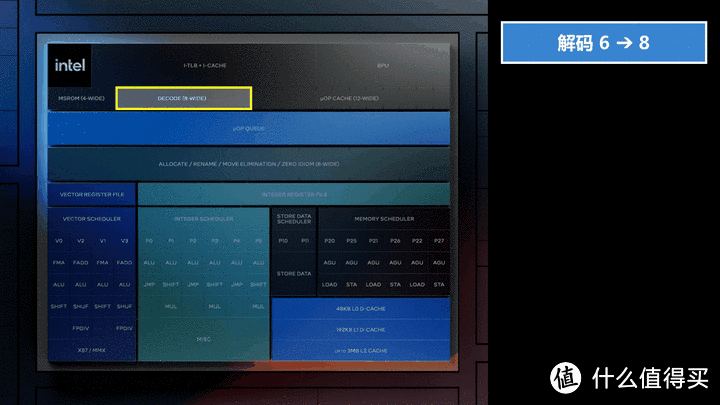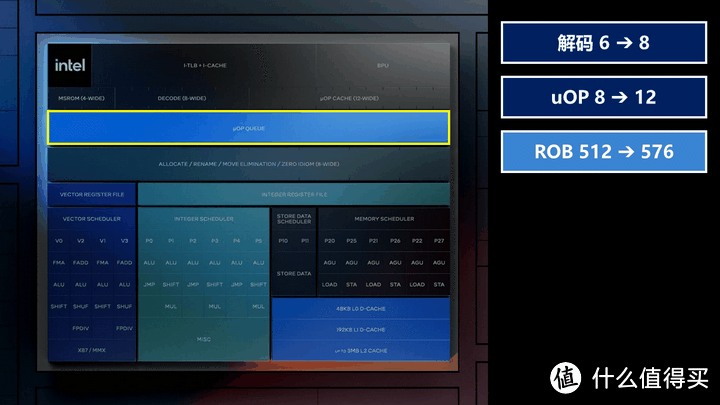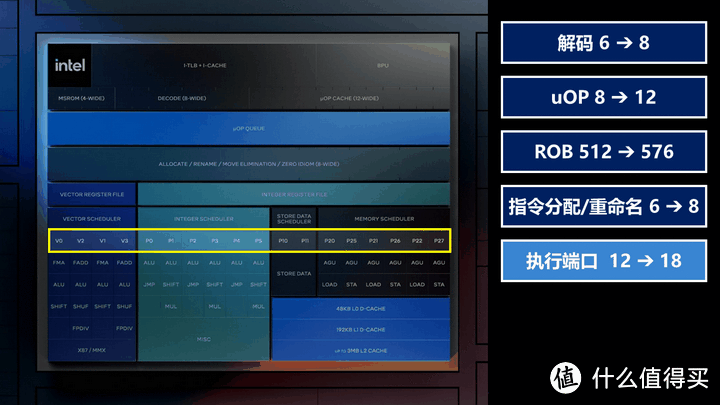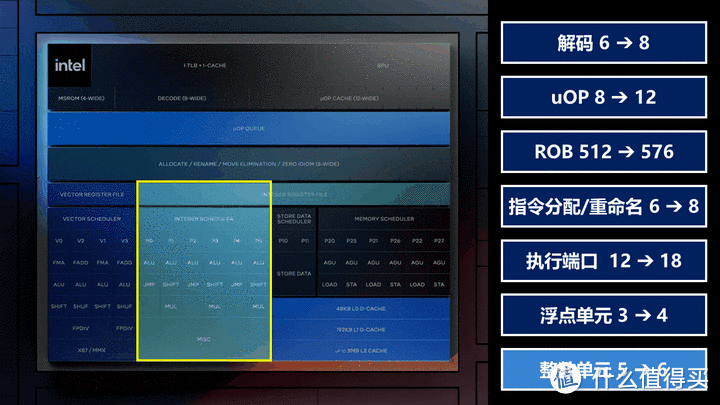
Lunar Lake的Lion Cove在规模上有极其激进的扩张,我在这里按照CPU处理的简化流程大概说下其在架构方面有什么进化:
Lion Cove的前端整体进行了重构,预测块部分规模是之前的8倍。
CPU访问内存前,首先会先访问i-Cache指令缓存看有没有最近的执行指令,如果有则可以直接进入uOP队列,如果没有就需要访问TLB。
TLB是虚拟地址到物理地址的映射表,查表如果表里有映射那就可以直接命中物理地址,如果没有就需要再次访问内存获得物理地址并写入TLB。
然后TLB里的指令会通过解码器进行解码,Lion Cove解码器从6-wide扩大到8-wide,这样解码就可以有更高的并行度和性能。
指令解码完成的微码存放在uOP缓存,当后续步骤需要这个指令的时候就可以直接在uOP缓存取用微码,而不用重新解码。Lion Cove的uOP缓存从之前的8-wide提升到了12-wide,同时读取带宽也有大幅提升,这样可以更快的访问已解码微码。
然后已编码的微码被放入ROB重排序缓存,等待微码被分配到不同的处理单元,Lion Cove的ROB容量从512提升到576,更大容量的ROB就可以容纳的可用于乱序执行的可选指令越多,这样选择余地也越大,性能也就会越好。
微码定位/重命名/移动部分也从6-wide升级到8-wide,而退出部分从8-wide升级到12-wide,这样就可以更高效的将乱序微码分发给不同的处理单元。
并且这次intel一改自P6的祖传做法,将整数和向量分别划分为两个调度器,这样两个调度器就可以有独立的工作状态。
执行端口也从上一代的12个提升到16个,这样也可以并行度更高更快的分发任务。
末端的向量浮点单元从之前的3个提升到4个,整数单元也从5个提升到6个,下部其他单元规模也有增加,这样就可以提供更强的浮点和整数处理能力。

Lion Cove的缓存结构也发生了一些变化,从之前Raptor/Redwood Cove的2级变成了3级,现在L0对应之前的L1,虽然容量和带宽并没变化,但载入周期从5缩短到4;L2部分从之前的2MB升级到3MB(移动版LNL为2.5MB)
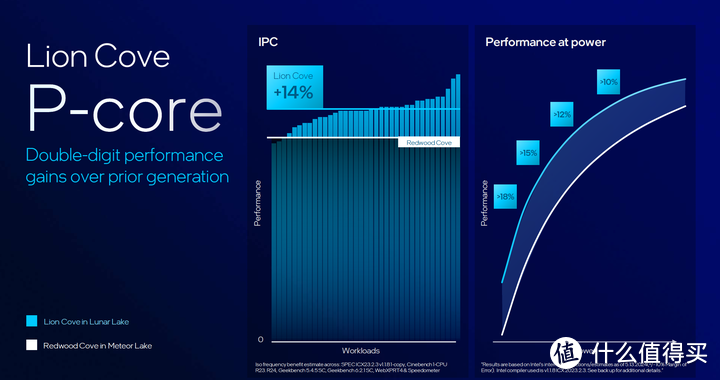
Lion Cove这样从前端到后端全流程无死角的疯狂规模扩张使得其IPC有平均14%的提升,再加上工艺的进步,使得Lion Cove同功耗性能也有10%以上的提升,特别是在低功率段,优势则更为明显。
不过Lion Cove设计初始更多是为能效考虑,就去掉了超线程功能,这样不仅能够提升能效,也能够节约一些芯片面积。但去掉超线程也必然牺牲了一些多线程性能。
超线程就是利用分时提高处理器核心的利用率,打个简单的比方,你一个人在工厂负责在一条流水线上工作并不满,现在让你同时处理两条流水线的工作,虽然每条线速度更慢,但整体还是工作更饱满,做的工作越多(特别是可以大幅提升后端利用率)。
并且这个流水线工作负载越轻(比如整数运算)提升幅度就越高,但你一条线工作负载足够高(比如AVX)都忙不过来的情况下,超线程能够带来的性能提升就会很小。再就是由于需要一心两用,即使另外一条线没什么工作,还是多少会影响第一条流水线的工作效率(这就是之所以PUBG之类电竞游戏关闭超线程反而可以提升性能的原因)。

但这次变化更大的其实是E-Core Skymont:
Skymont前端解码从Gracemont的2组3-wide扩展成3组3-wide。
ROB则直接从256大幅提升到416,,虽然比Raptor Cove/Redwood Cove的512少,但基本也是大核水平。
Skymont的微码定位/重命名/移动部分也同样从6-wide升级到8-wide,而退出部分更是直接从8-wide翻翻到16-wide。
执行端口也从上一代的17个大幅提升到26个。
浮点单元从3个直接翻翻提升到6个,而整数单元依然保持4个没变化。
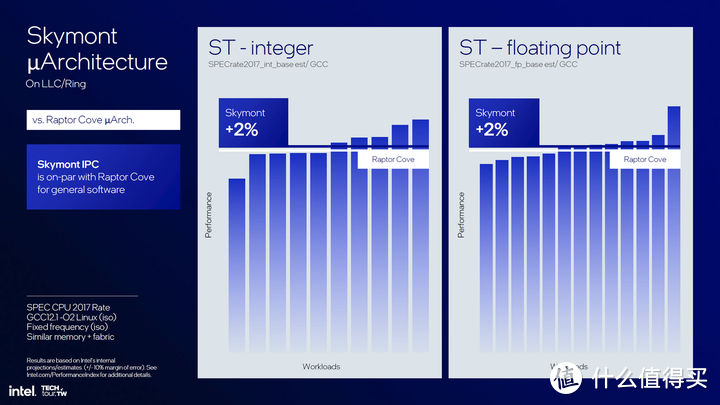
具体性能对比方面Skymont就不去欺负Gracemont了, 干脆就直接跟桌面13/14代的P-core Raptor Cove比较,固定同频的情况下使用SPECrate 2017测试,无论是整数还是浮点,Skymont相比Raptor Cove都有2%的性能优势。(后面我们会实际测试)
处理器实物和基础规格

Ultra 200系列更换为LGA1851接口,与之前12-14代的LGA1700并不兼容(防呆卡口的位置不同),CPU顶盖和散热器接触部分稍窄一点。

底部触点和电容排列也有明显差别。
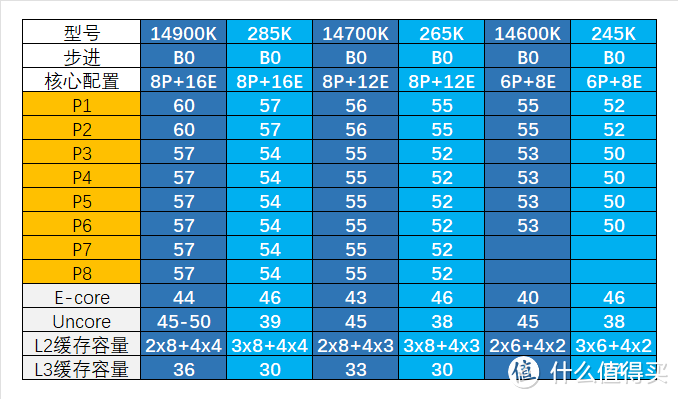
ARL-S首发的一共有U9-285K/U7-265K/KF/U5-245K/KF以及对应KF一共5个型号。
ARL-S的处理器核心数量和RPL报错一致,U9为8P+16E/U7为8P+12E/U5为6P+8E。P-core的频率相比RPL都低了3个倍频,无论是1-2核心负载的TVB频率还是3-8核心的负载频率。另外ARL的P-core去掉了对超线程的支持。
E-core三个规格均为4.6GHz固定频率,相比RPL的40-44有明显提升。
P-core的L2缓存容量从2MB提升到3MB,而E-core 四个一簇的L2依然保持2MB。
ARL Uncore频率相比RPL大幅降低,从全核心45下降到38。
处理器的电压/功耗和温度
这部分我还是先用VF电压频率曲线来说明:先来了解基本概念,每个处理器有个对应的默认VF电压频率曲线,在每个频率对应一个电压值,在高频电压高保证稳定,而在低频就不需要那么高的电压,就用比较低的电压来降低功耗。
在一个频率点默认电压低的处理器往往体质更好,默认设置功耗更低,一般来说,超频到相同频率也仅需要更低的电压,或者相同电压可以达到更高的稳定频率,也就是说默认电压低的往往也是超频能力更好,ROG主板的SP体质分也是依据电压而来,电压越低分数越高。
我们将我们手头的RPL/ARL K处理器的电压频率曲线制作成图表。粉红色为i9,并且标明处理器的SP分数和AIDA64 FPU满载功耗作为参考。
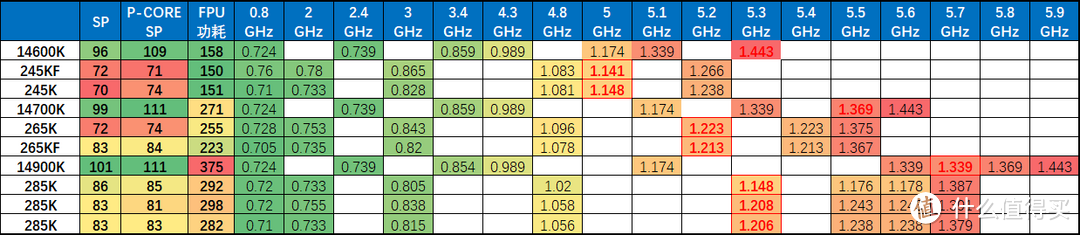
ARL VF曲线的最高频率电压还是在1.3V以上,但是全核心满载电压基本就1.2v不到的水平。但这也说明超频基本只有2个倍频的空间,比如285K默认54,到56就差不多,如果上到57就需要付出极大的电压和功耗代价。
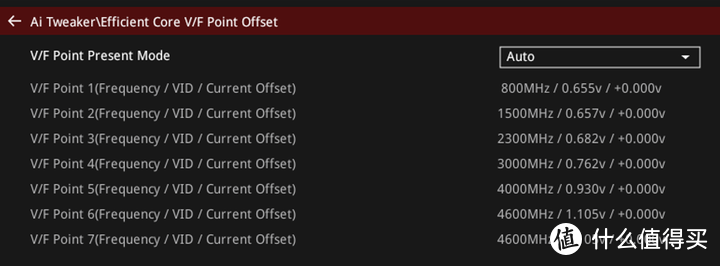
另外ARL的E-core有单独的VF电压曲线,E-core频率更低其实并不需要和P-core一样高的电压,最高4.6 GHz也就1.1 V水平,分离式的DLVR有利于降低E-core的功耗。
U5-245K FPU满载功耗150W水平,比14600K持平或者稍低一点,这个功耗稍好的5-6热管单塔就压得住。
U7-265K FPU满载功耗240W水平,相比14700K 280-300W水平大幅降低。也略微低于13700K,使用好点的双塔风冷就压得住,我这里使用SOPLAY V587可以压倒90度出头的水平,而360水冷可以压到80度以下。和预先的不一样,ARL的TSMC N3B虽然密度比intel 7的RPL要高的多,但积热问题还有改善。
U9-285K FPU满载功耗280-300W水平,当然如果跑YC/P95之类还是可以到360W水平,之前14900K FPU大概380-400W,AIO不解锁功耗墙是没办法压得住的,日常使用现在300价位的入门360水冷就可以压住。
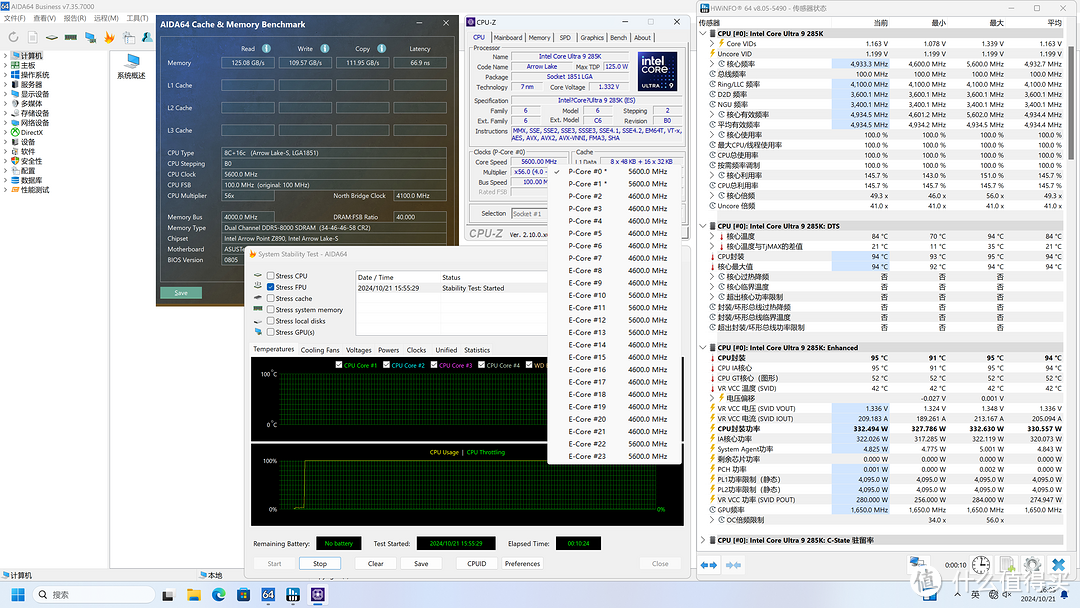
超频的话我将285K P-core锁定在56,E-core保持默认,AIDA64满载功耗330W,VID电压1.163V。
当然如果是长期重度AVX或者上面这样超频,那还是需要龙神3 Extreme这样的旗舰水冷。

这次我们测试intel平台就是使用的龙神3 Extreme,其相比原版首先冷头方案从新Asetek 8代升级新8.5代,扣具方面针对ARL核心热源靠上也提供了偏移功能。风扇也从之前的7扇叶12025规格升级成了2800 RPM的9扇叶12030,风压和风量都有很大的提升。

此外,龙神3 Extreme的屏幕分辨率也提升到640 x 480分辨率,使得屏显效果更好。龙神3 Extreme在这些提升的同时还是加量不加价,依然维持了原版2899元的售价。
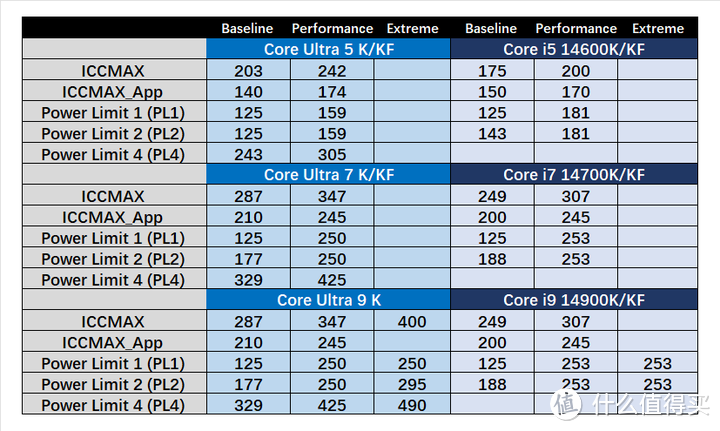
当然Ultra 200系列还是有Baseline设置,之前14代其实有不少情况,功耗并没触及Power Limit但撞电流l墙,这次ARL在略微降低PL的同时但提升了ICCMAX的电流上限。这代由于功耗的降低,Baseline基本不会限制245K/265K性能,对于285K的影响也很小,本次测试在没特别说明的情况下是在没限制的设置下进行测试。
ARL待机相比RPL也大幅降低,14代K待机封装功耗大概在50W水平,而ARL待机,8000 XMP大概在15W,如果不开XMP待机仅有7-8W。
Z890平台扩展性和ROG MAXIMUS Z890 HERO赏析

对于现在的平台而言,任何扩展接口本质都是PCIe,CPU和芯片组可以提供的PCIe通道数就直接决定平台的扩展性上限,我制作了一张Z790和Z890的PCIe Lanes通道分布图,来做简要分析。
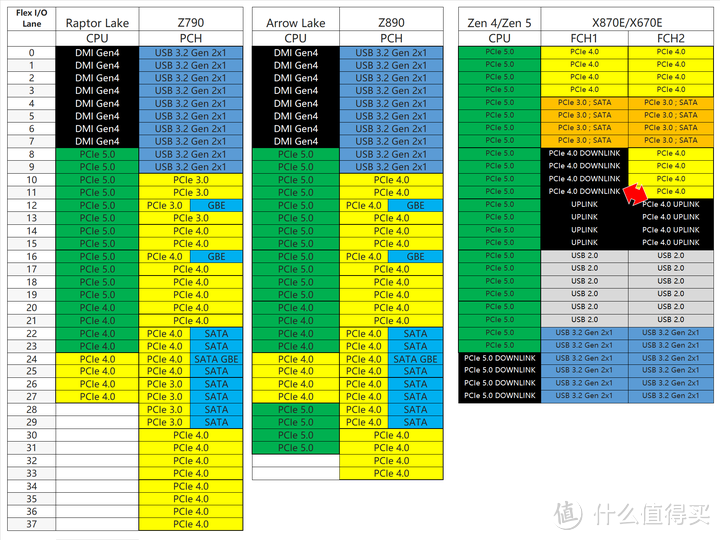
首先是CPU部分,Z890和AMD AM5平台一样,在4x 4.0之外再增加了一组CPU直出的PCIe 5.0 4x,这个主板一般会扩展出一组5.0的M.2。
之前RPL CPU直出的PCIe 5.0 16x只能拆分3为8+8,而ARL可以拆分为8+4+4。
之前Z790 PCH下是16个4.0+8个3.0通道,而Z890 PCH下全部升级为4.0,但通道总数降低为24个,就说把8个3.0换成了4个4.0,其实总带宽并无变化。
另外ARL还有2个CPU直出的雷电4,这也需要占用2个4x PCIe 4.0,虽然CPU提供了原生支持,但引出了需要额外昂贵的Retimer芯片,因此太便宜的Z890也应该不会标配雷电4。

我们以ROG MAXIMUS Z890 HERO来看看Z890是如何之形态,可以实现怎么样的功能。Z890 HERO基本还是延续之前HERO系列家族化的设计语言。

背后辅以大面积覆盖的装甲,这样可以增加主板PCB强度避免变形,安装的时候也不用担心机箱铜柱回刮伤PCB。

Arrow Lake-S采用LGA1851接口,同之前的LGA1700处理器不兼容,接口防呆卡口的位置有明显的差别。

不过两个接口的散热器孔距和处理器高度还是保持一致,LGA1851依然兼容之前的LGA1700散热器。

供电规模又有进一步的提升,从双向提升到类似APEX Encore三向包围供电布局,将LGA插槽包裹住。

在拆开厚重的散热片后,我们可以见到夸张供电的真容,具体是 CPU核心 22相110A+1相集显90A+2相 SA 90A+2相VNNaon 80A。

其中CPU供电的Mosfet型号是英飞凌的PMC41430,这个型号应该是首次在消费级主板上使用,单相能够承载110A电流。

Z890 HERO虽然还是采用4DIMM,不过采用了NitroPath的改进设计,去掉DRAM引脚触点上方的残线,进一步提升了信号强度,使得4 DIMM也能够支持更高的内存频率。内存插槽上方有4个风扇接口和Q-code出错灯。外侧前置Type-C接口也提升到了2个,为了满足2个Type-C全功率输出的供电需求,辅助供电也从6pin升级到了8pin。

Z890新增了一组CPU直连的PCIe 5.0 4x通道的M.2,Z890 HERO在这个M.2上采用了全新的快拆散热片,拉开右边的金属拉扣就可以取下,下面的塑料卡扣也改为滑动式,不仅能够免工具固定M.2 SSD,还可以支援不同的长度规格。

PCIe布局方面,CPU直连的16x可以设置拆分为8x和两个PCIe 5.0的M.2,再加上CPU直连的PCIe 5.0和4.0 M.2,一共就有4个CPU直连的M.2。下部还有2个PCH下的PCIe 4.0的M.2接口,一共有6个M.2接口。
右侧边缘除了4个SATA以外,还新增了1个PCIe 4.0的SlimSAS接口,可以用来外接企业级固态硬盘。虽然我觉得有这个需求的用户估计不到5%,但即使把SlimSAS再换成个M.2,需要使用到第7个M.2的需求应该还是会少于SlimSAS。此外SlimSAS还可以在BIOS切换成SATA模式,扩展出4个SATA盘,我这样的仓鼠党狂喜。

虽然Z890支持8+4+4的拆分,但这个并不会是Z890的标准功能,因为拆分所系的PCIe 5.0 Retimer的价格还是很昂贵,Z890 HERO在背部通过四颗嘉雨思JYS13008MF01 PCIe 5.0 Redriver来实现8+4+4的拆分功能。

Z890 PCH的基座和封装尺寸同Z790十分接近,但从一个月的使用看Z890 PCH的温度相比Z790下降很多。

后部挡板接口首先是2.5G+5G双网卡回归,再加上WiFi 7,USB方面有4个10G的USB Type-A,4个5G的USB Type-A。一个10G的USB Type-C和2个雷电。那些什么USB 3.2 Gen X谁搞得清楚啊,这样5G/10G写的清清楚楚明明白白,好评。
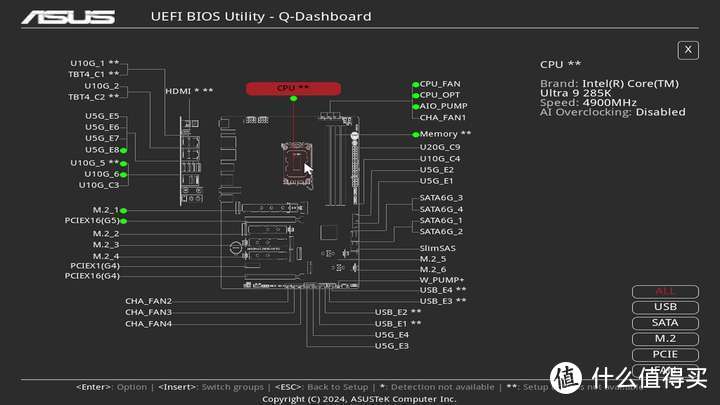
另外在新一代Z890主板BIOS里增加了Q-Dashboard功能,可以方便的查看主板各个接口的使用情况,整体十分直观明了。
缓存和内存系统
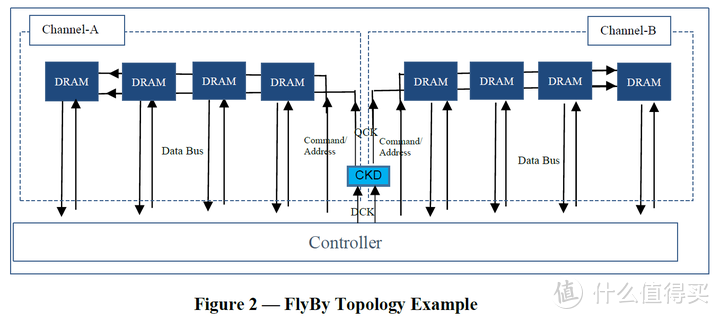
Z890开始支持CUDIMM,CUDIMM和普通的DDR5 UDIMM相互兼容,Z890可以使用普通的DDR5 UDIMM,CUDIMM也可以用在Z790这样的老平台主板上,当然这只能跑bypass模式。

虽然本次测试主要还是以普通的UDIMM 16GBx2 8000为主要平台,但我们也单独测试CUDIMM,我们收到的金士顿提供的CUDIMM工程样品。
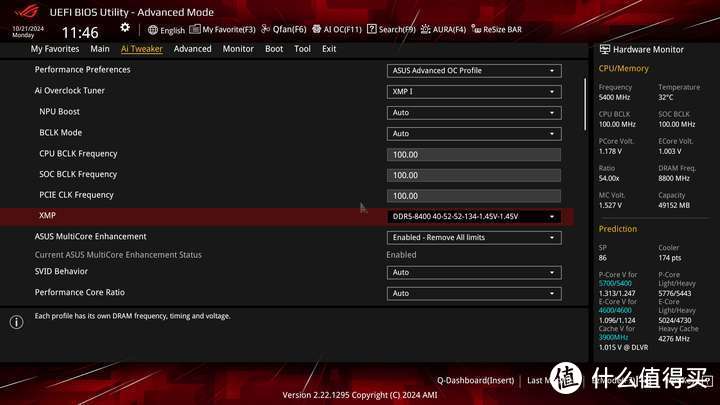
其提供了三组XMP设置,最高设置为DDR5 8400 40-52-52-134 1.45v。

CUDIMM主要是在内存增加了一个Client Clock Driver(上图是我拍的另外一只Adie 16GB的CUDIMM,CKD是PMIC下的长条芯片),CKD生成时钟频率信号给内存颗粒,用来取代由CPU内存控制器发出频率控制信号。一套平台内存频率可以跑多少,是由CPU内存控制器/内存通路和颗粒三方共同决定,CKD并不会提升CPU内存控制器和颗粒的体质。但CKD可以直接在内存产生频率信号来提升信号强度,从而降低CPU内存控制器和颗粒的体质需求。在效能上CUDIMM和普通UDIMM并没差别,仅仅是可以上更高的频率。
不过CUDIMM只是改善高频,我尝试过4根Adie 16GB CUDIMM在菊花链的ROG Z890 HERO上依然也只能支持到6400频率。
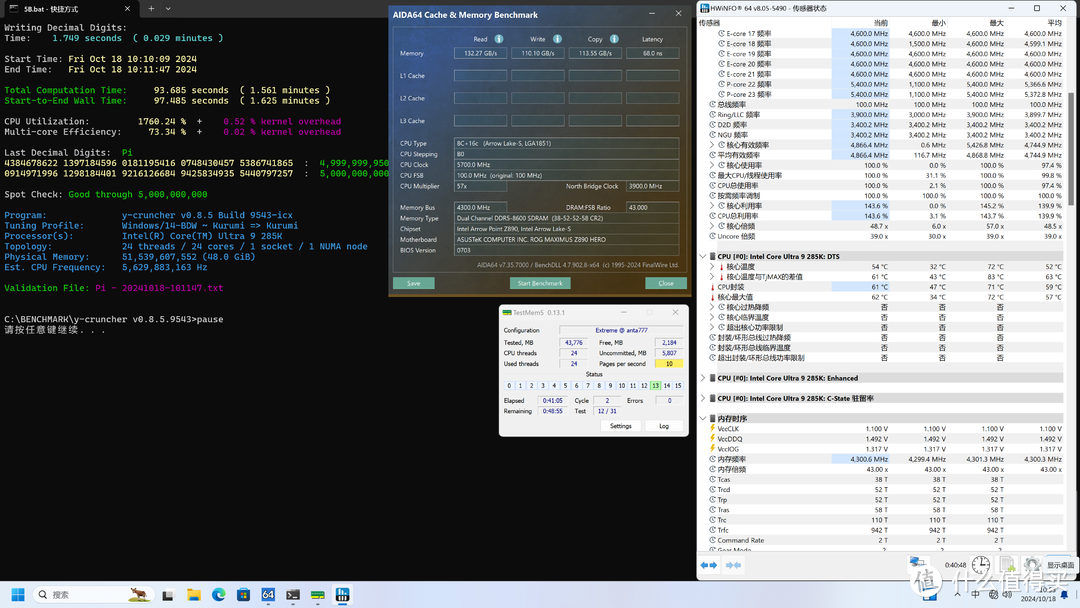
在8600频率 38-52-52-58 tREFI=65535可以过YC和TM5 ant777 Extreme测试,虽然带宽可以到133 GBps,但延迟还是有小幅倒退。更极限点,在44-56-56-152 tREFI=32767可以跑到8800,但这参数太松,不仅延迟而且带宽都有倒退,当然这个小参还有压缩空间,只不过我没时间细调了,俗话说的好,一杯茶一包烟,几个小参调半天。
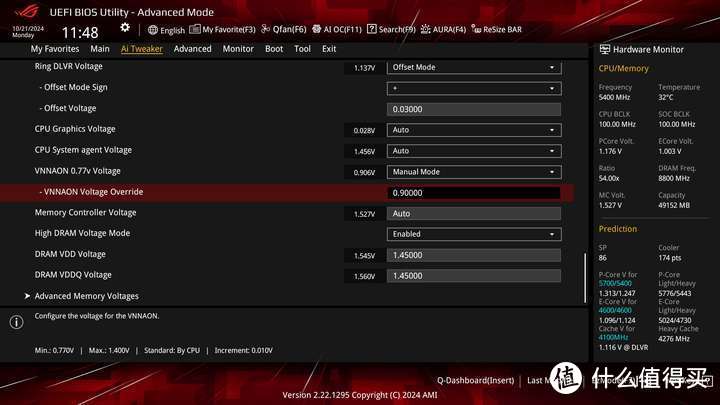
不过ROG Z890 HERO相对比较省心,之前Z790 SA/IVR/MCV需要反复摸索排列组合,而Z890 HERO SA/MCV auto给的都很准,如果不稳定自己尝试手动往往只会更不稳定,自己关注内存频率/电压和小参就可以。
当然内存不能只看频率,必须更为关注效能。我们使用AIDA64 6.75测试9950X/285K/14900K的6000-8600频率的内存带宽和延迟。分为两组,第一组为统一34-46-46-58 tREFI=12481的统一设置。第二组为各个平台/各个平日段的比较优化设置,6400以下为28-38-38-58,6800-8000为34-46-46-58 tREFI=65535 tRFC=520 (16GB x2 Adie),8400-8600为38-52-52-58 tREFI=65535 (24GB x 2 Mdie CUDIMM),这设置不算完全压榨,差不多是不挑体质一般都可以达成的稳定设置。
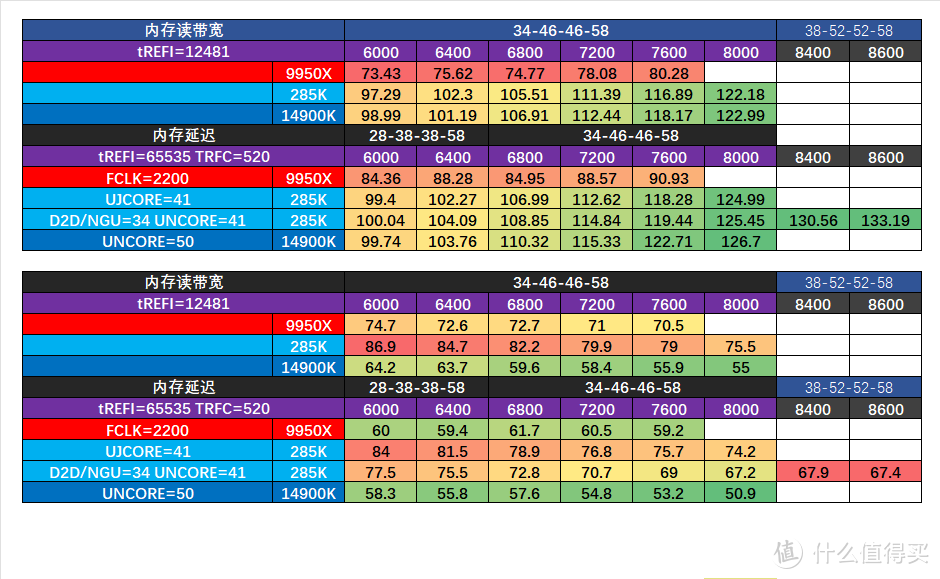
在同设置下,285K的带宽基本和14900K持平,但延迟同频同大参设置基本要高25ns。另外内存上到8400-8600频率,参数也要相应的放松到38-52-52-58,虽然带宽可以提升到133 GBps,但延迟并没改善。
如果降低内存延迟这要从内存的访问路径看:首先核心L2会通过L3缓存/环形总线到Die to Die的接口,通过D2D到SoC Die的互联总线连接到内存控制器。要降低内存延迟就需要提升这几个通路的速率。
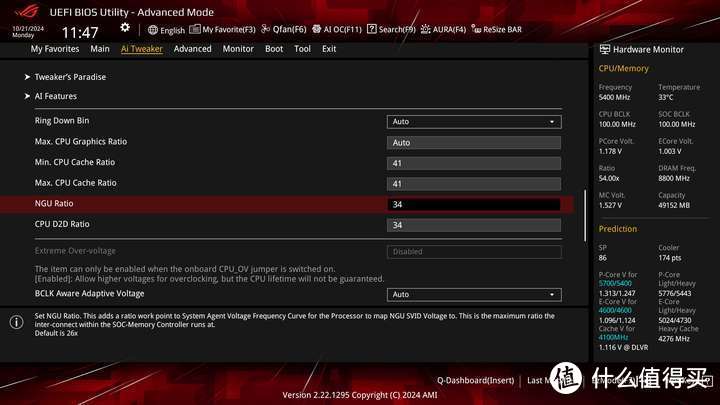
14900K的uncore倍频在45-50(重载-轻载),而这次ARL UNCORE频率低了很多,默认只有38,超频也只能到41-43(42-43可能需要加RING电压)。其实uncore对于游戏性能影响还是很大,当年13代比12代游戏性能提升很大程度都是依靠拉高uncore。
而连接计算核心和SoC Die的D2D默认为2.1GHz,默认电压超频一般可以到34,如果加VNNAON 0.77V电压可以到36-37。
而SoC核心的NGU频率全称是Next Generation Uncore,这个是SoC Die内部总线频率,默认频率是28,一般可以超到34。
我个人感觉D2D和NGU都超34比较合适,虽然可以再超高D2D但收益并不大,可能是D2D上去了后面的NGU也是瓶颈。设置Uncore 41/D2D/NGU=34是比较优化的设置,可以将延迟再压低6-7ns。
应用性能测试
SPEC CPU 2017性能测试
SPEC CPU是一套行业标准的CPU密集型基准测试套件。SPEC设计了此套件,以使用实际用户应用程序开发的工作负载,在最广泛的实际硬件范围内提供计算密集型性能的比较度量。我们测试关闭SMT,使用gcc/g++/gfortran 14.2 mareth=native -ofast C/C++/jemalloc 5.3.0设置进行测试。这次我们主要考察的是浮点和整数rate的单线程性能。
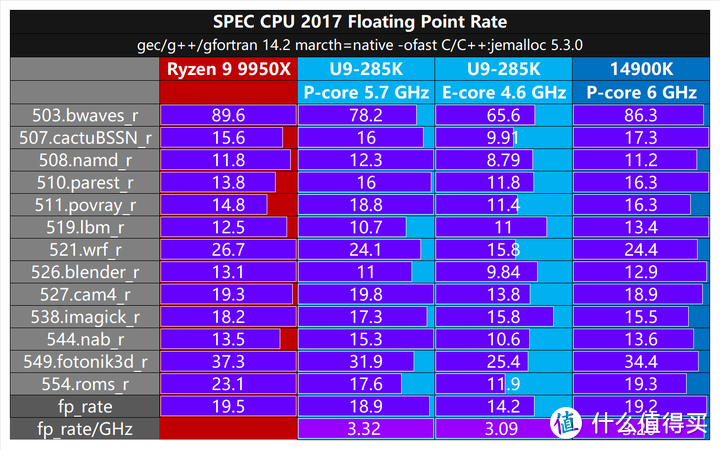
U9-285K的P-core fp_rate为18.9,E-core为14.2,P-core虽然性能低于14900K,但单位频率性能还是更好。(Zen 5由于非定频就没有统计这个项目)
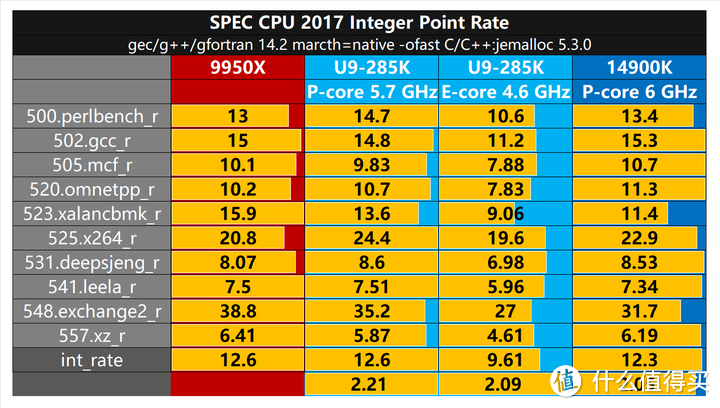
int_rate部分285K P-core和E-core分别为12.6和9.61,285K用5.7GHz的频率超过了14900K 6 GHz的整数性能,并且E-core Skymont的单位频率性能直接超过了Raptor Cove。
在Raptor Lake时代 4个E-core占用比1个P-core稍大的面积,实现2个P-core的多线程性能,而在Arrow Lake全新的Skymont核心,单个E-core就可以实现P-core 3/4的性能,并且相对面积占比也没有变化太大,可以说是十分高效的核心架构。
Cinebench 2024
新版CineBench 2024不再采用先前的标准渲染器,而是转向使用Maxon公司旗舰软件Cinema 4D的默认渲染引擎Redshift,并且新增了对GPU渲染的支持。我使用vTune初步分析2024相比R23,AVX/SSE的这样的Packed指令占比有所提高。
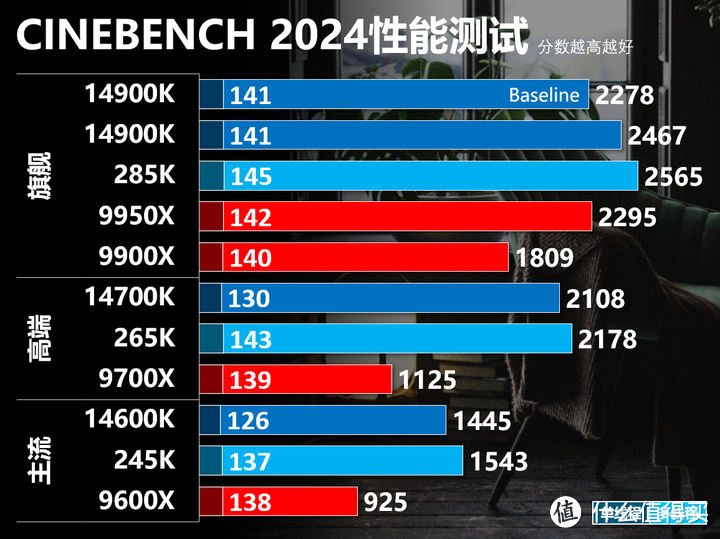
得益于Skymont性能大幅提升,ARL在去掉超线程/频率更低的情况下性能还是略微领先RPL。Zen 5的默认TDP设置还是比较保守,如果手动PBO其实还是有比较大的提升空间。单线程部分ARL在频率下降0.3 GHz的情况下性能还是可以超高RPL,这说明Lion Cove的浮点性能还是有明显的提升。
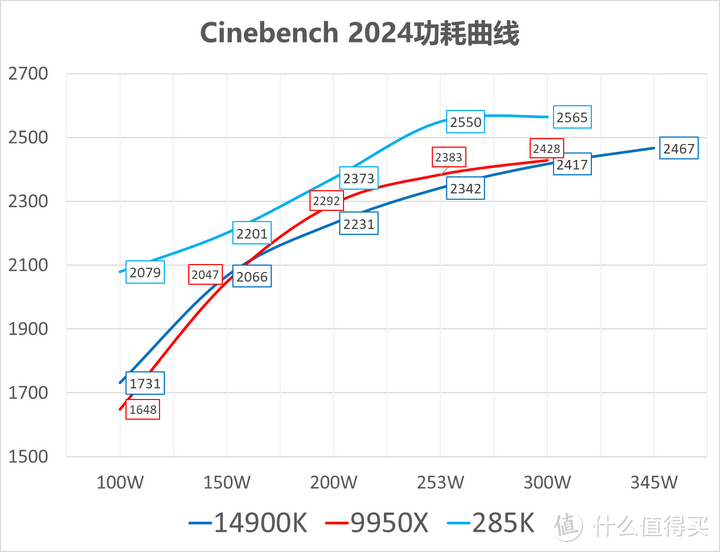
我在以50W为间隔设置功耗墙(不修改电压和其他设置),测试14900K/9950X/285K在不同功耗下的多线程性能,9950X虽然在中间功率段相比14900K有一定优势,但在100-150W低功耗段被落后工艺的IOD拖累(9950X 300W段实际就290W不到),同功耗性能甚至被14900K反超。而285K在全功耗段优势明显,特别是在100W同功耗285K相比9950X有26%的性能优势。另外在253W的Baeline设置,285K相比完全放开功耗性能损失也仅有0.6%,几乎可以忽略不计。
7ZIP性能测试
7ZIP测试主要是对内存延迟敏感,对内存/缓存带宽不敏感,而对于数据缓存容量/速度和TLB,还有乱序执行/分支预测敏感。这个测试不使用FPU和SEE,大部分代码是32位整型,少部分是64位整型。压缩测试有大量随机访问内存和缓存,执行时间的很大一部分CPU都在等待缓存或内存的数据。

ARL在这个测试项目劣势明显,主要原因是:
ARL后端的INT部分改进不如FP那样大。
INT整型负载比较低,超线程的提升比例大,没有SMT的ARL相对RPL吃亏。
INT整型负载比较低,对于Zen 5而言功耗墙的影响就小,可以Boost到更高的频率。
虽然ARL缓存系统大幅加强,但内存延迟高,不命中的情况下惩罚高,7Zip是延迟敏感性测试。
y-cruncher AVX性能测试
y-cruncher是一个多线程计算Pi的测试程序,可以充分利用AVX甚至AVX-512进行计算。具体测试使用以下命令行:
y-cruncher.exe skip-warnings priority:0 bench 5b
Windows 11 24H2 YC相比23H2慢了10秒以上,单这个测试使用23H2进行测试。

ARL相比RPL AVX性能有明显提升,并且性能要快于AVX2的Zen 5,但Zen 5在开启AVX512后性能会有十分大幅度的提高,Ryzen 9都可以反超285K。但AVX-512对于普通消费者很少有应用的机会,除了少部分模拟器需要用到。另外y-cruncher这个测试项目对于内存带宽极其敏感,提升内存频率可以大幅提升性能。
X265编码性能测试
X265编码是重AVX的测试项目,这个测试基本是CPU最高负载的测试,同时我们使用X265考核处理器的极端条件的功耗和温度。 编码使用的视频源文件是ducks_take_off_2160p50.y4m,使用 slow 预设,以 28 恒定速率因子来压缩,码块树 CTU 数量为 64 个。对于Zen 5我分别使用AVX2和AVX-512指令集进行测试。使用的命令行分别如下:
x265.exe ducks_take_off_2160p50.y4m –preset slow –crf 28 -o duck.mp4 –ctu 64 –profile main10
x265.exe ducks_take_off_2160p50.y4m –preset slow –crf 28 -o duck.mp4 –ctu 64 –asm avx512 –profile main10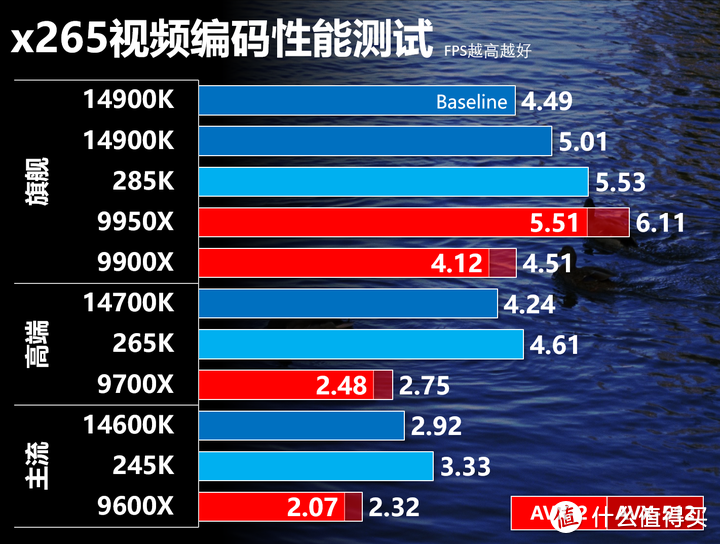
ARL整体相比RPL性能还是有明显提升,AVX这样的重载超线程对于性能的提升并不太大。
9600x和9700x核心太少,245K和265K性能有明显优势,16C的9950X使用AVX2性能基本同285K持平,但在使用AVX-512后就反超285K。
Office应用性能测试
应用性能测试我们们使用UL的Procyon进行测试,其特点是调用真实应用进行实际操作来测试硬件性能,这样更为贴近用户的真实使用情况。 办公室生产力基准测试是根据在办公室里典型一天的常见任务而设计的。该基准测试打开Excel 表格、PowerPoint 演示文稿、Word 文档和 Outlook 电子邮件。这些应用程序会同时运行,而焦点会从一个任务移到另一个任务。例如,该基准测试从 Excel 中复制一个图表并将其添加到 PowerPoint 幻灯片中。它从一个 Word 文档中获取文字并将其添加到另一个文档中。该基准测试着重于测量直接影响用户体验的性能方面,如提供流畅的互动和快速处理大型任务。
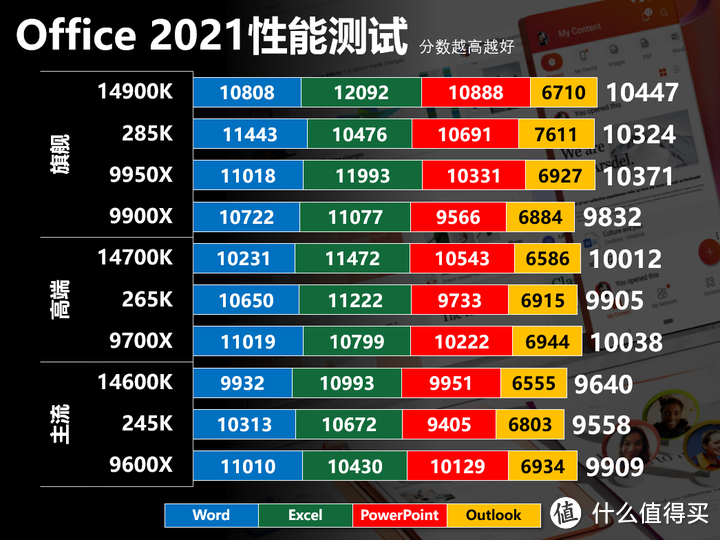
24H2修复分支预测后Office的性能,AMD和intel平台都有10%以上的提升,但Zen 5的提升幅度还是更大。zen 5在Excel项目有些优势,但在后面的Power Point/Outlook项目落后,应该是后两个项目需要同时调用多个软件,在跨CCD核心调用上还是存在问题。
游戏性能测试
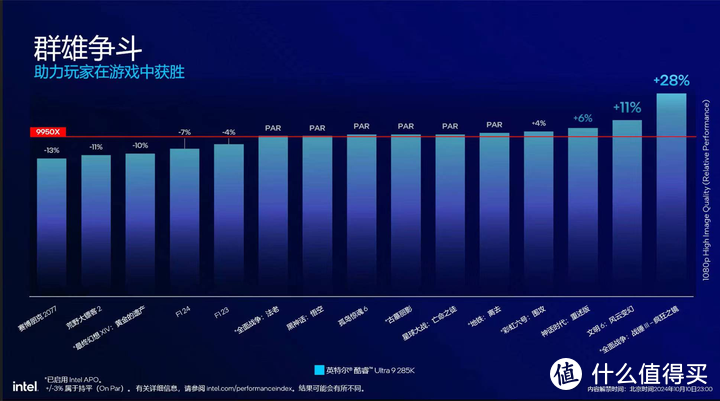
添加图片注释,不超过 140 字(可选)
其实在10号发布会英特尔的这张PPT已经降低了大众对于ARL游戏性能的心理预期,但ARL游戏性能实际到底如何还是需要靠实测来证明。在游戏性能测试开始之前,我再重复一次几个CPU游戏性能的相关概念。
看玩游戏CPU够不够用,不是看CPU是否吃满,而是看GPU是否吃满,如果GPU占用率不是吃满,那就说明CPU性能并不能完全带动GPU。因此CPU的游戏性能本质不是CPU跑不跑得动游戏,而是CPU的速度是否可以让GPU性能完全发挥,发挥多少。
再引入第二个概念,CPU FPS和GPU FPS,游戏实际的FPS是由CPU FPS和GPU FPS的下限决定,如果CPU FPS比GPU高,GPU就可以跑满,如果CPU FPS比GPU FPS低,那就会限制GPU性能的发挥,降低游戏性能。例如极限竞速地平线5就由CPU FPS/GPU FPS的相关数据图表。
游戏画质越好/分辨率设置越高,那GPU FPS下降的幅度会远远大于CPU FPS,这样性能瓶颈就会更为倾向GPU,而如CS2/PUBG/永劫无间/英雄联盟/APEX这样的偏电竞的游戏,画面技术和画质不算太好,再加上大多玩家为了追求性能和可识别度也倾向设置避免低的分辨率和画质,导致GPU FPS很高,就容易出现CPU性能瓶颈,导致GPU占用率低。
我们本次游戏性能也包含电竞和3A不同类别的游戏,具体分辨率和画面设置也是使用接近真实玩家的情况,而并不会为突显CPU的性能差距全部选择1080p低画质,对于追求视觉享受的3A还是会测试高画质和高分辨率,不会真有人用RTX 4090去跑赛博朋克2077的中低画质吧?
反恐精英2
CS2我们使用工坊的FPS Benchmark进行测试,使用的是1920x1080低画质进行(实际大多玩家都是这样设置,低分分辨率头的像素比较大更容易爆头,低画质画面也更干净,顶多开个动态阴影来看敌人影子。),在这样的设置下RTX 4090基本没有GPU瓶颈。
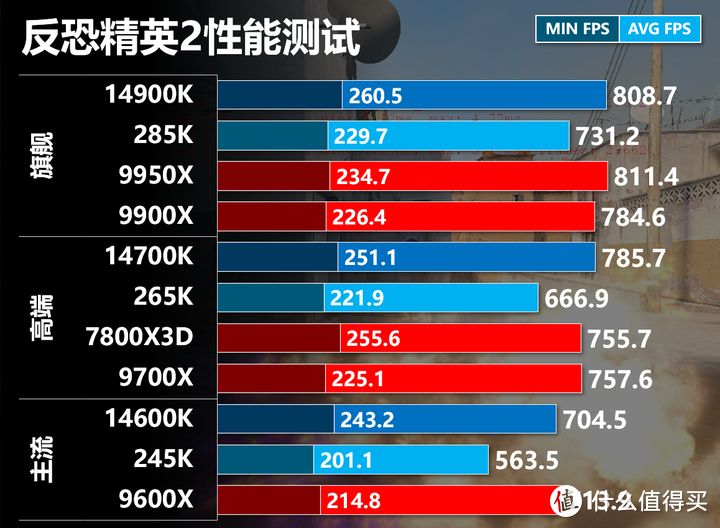
测试14900K和7800X3D我第一感觉帧数是偏低的,在经过对比验证后发现相同BIOS和画面设置的情况下,24H2相比23H2要慢30 FPS以上。但这个性能下降的幅度各个平台基本相同也还算公平。另外这个设置也不是完全最优化设置,并未过于收紧内存小参/调整FCLK/Uncore,关闭SMT,这些动作都可以比较大幅度的提升性能,将14900K/7800X3D/9950X优化到850 甚至900 FPS的性能水平。
285K默认是731 FPS,在拉高D2D/NGU到34,可以提高到764 FPS,再超频到5.6 GHz的话那就可以到830 FPS超过默认的Zen 5。CS2对于CPU主频还是比较敏感,主频偏低的245K/265K就有点吃亏。
其实对于Zen 5,特别是单CCD型号游戏内存跑同步6400C28性能会比7600C34稍好一点,但我手头9600X/9900X都不能跑同步6400,因此游戏依然还是设置的7600C34。
英雄联盟
英雄联盟同样也是完全CPU瓶颈,2K和4K分辨率对于RTX 4090来说性能都一样,我这里使用召唤师峡谷的回放最后三分钟使用Capframe进行性能测试,记录的平均FPS和P1 FPS。
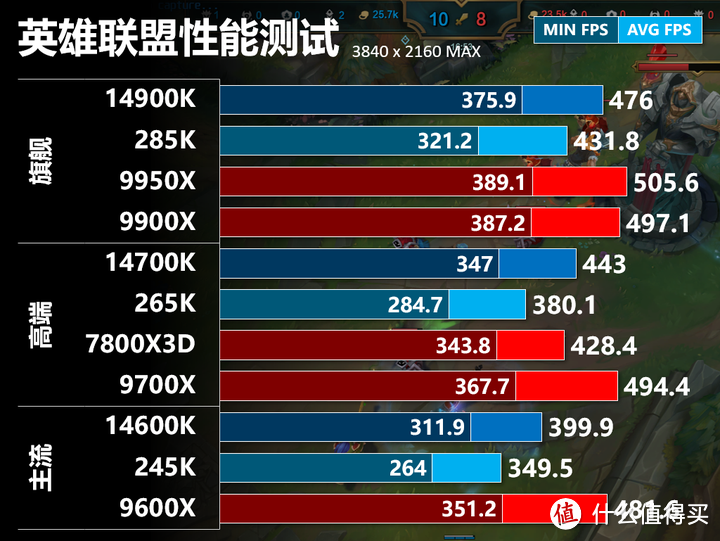
英雄联盟不太吃L3,频率过低的7800X3D性能表现不佳,其他Zen 5性能十分接近,现在的英雄联盟版本是频率敏感性,核心数不会影响性能。
绝地求生
绝地求生我们依然使用DX11增强路径,画面我们设置成2K分辨率,纹理、视野距离和抗锯齿最高,其他最低,这样的设置能够在画质和性能之间能够较好的平衡,同时画面也较为干净方便索敌。测试我们使用4排雪地图3分钟回放,前90秒是驾车高速行驶,后半段是围绕空投的中距离混战,有大量的手雷和烟雾弹。我使用CapFrameX记录的平均FPS和P1 FPS。
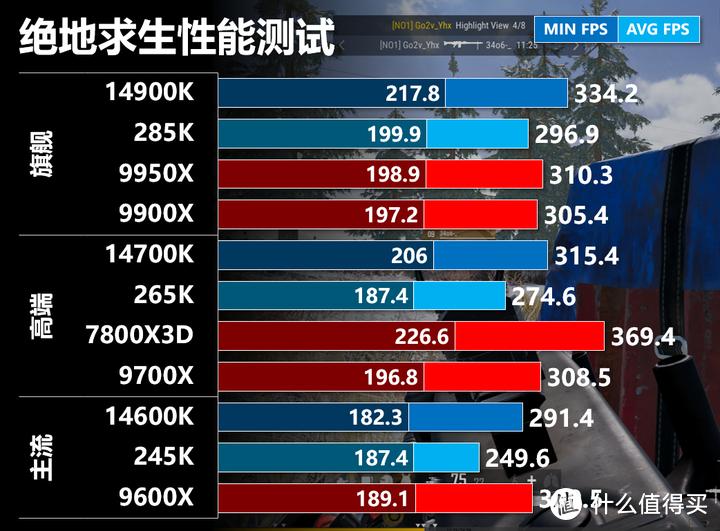
绝地求生对于缓存/内存延迟和频率都比较敏感,7800X3D有一定优势,而RPL小幅领先Zen 5。285K性能和Zen 5接近,但265K和245K频率还是偏低。
极限竞速地平线5
极限竞速地平线5设置全特效果,测试2K和4K分辨率下的性能。这个测试项目我们除了关注游戏的FPS,也关注CPU FPS。游戏的实际FPU是由CPU FPS和GPU FPS的下限决定,如果CPU FPS低于GPU FPS,就会限制GPU性能的发挥形成CPU性能瓶颈。
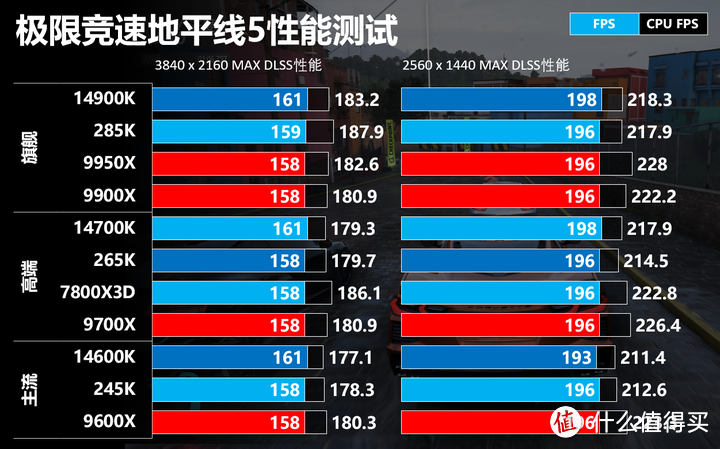
RPL和Zen 5的CPU FPS是有少许优势,但对于4K和2K DLSS性能全特效而言,CPU性能都可以满足需求,基本不会影响游戏FPS,其实测试出来没差别同样也是结论。
赛博朋克2077
赛博朋克2077我们使用4K和2K DLSS性能模式全特效(包括路径追踪)进行测试,这2个设置实际渲染分辨率为1080p和720p。
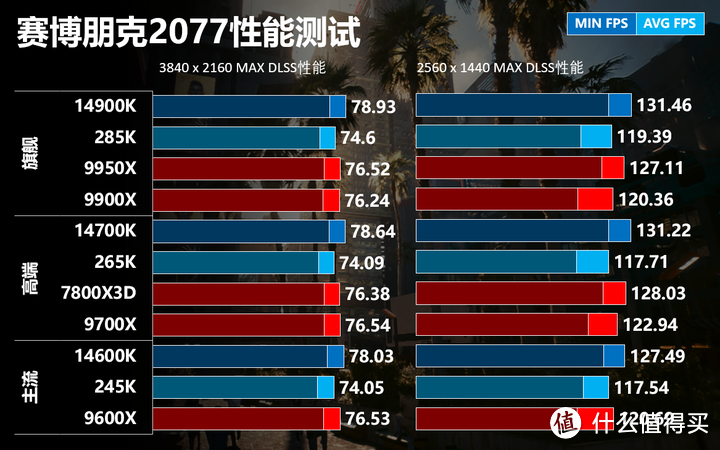
ARL和Zen 5的游戏性能基本持平,而RPL在2K/4K分辨率分别有2-4 FPS的优势。赛博朋克2077的CPU线程利用十分充分,单CCD的9600X和9900X由于可用核心数量只有6个性能还是受到一定影响。
测试总结
intel Core 200 Ultra Arrow Lake相比14代Raptor Lake有更高的IPC,更高的能效比,在生产力浮点运算方面还是有比较明显的提升(特别是渲染和视频类生产力性能),并且这还是在没有超线程的情况下实现的。Arrow Lake的Lion Cove首先是为Lunar Lake这样的移动平台开发,更多考虑能效比和面积效率去掉了对SMT的支持,这样就影响了其多线程性能。不过幸好E-core Skymont性能有很大的提升,完全弥补了去掉超线程的性能损失。因此ARL对于以浮点/SSE/AVX负载为主的内容创作者和生产力用户来说,还是一个很不错的处理器平台。
游戏测试ARL相比14代和Zen 5还是有一些差距,特别是在GPU轻载的电竞游戏。游戏性能的差距主要是以下原因导致的:内存控制器在SoC Tile和计算核心分离导致内存延迟过高,Uncore频率偏低导致延迟偏高和L3缓存带宽偏低。再就是偏低的CPU频率,285K 5.4 GHz全核心比14900K要低0.3 GHz,也要低于Zen 5的游戏频率,就更不用5.2 GHz的265K和5 GHz的245K了。不过ARL考虑到之前RPL的稳定性问题本身的频率设置比较保守,并没有出厂即灰烬,无论是P-core主频还是D2D/NGU手动超频还是有一定的空间,特别是对于245K和265K还是有比较大的空间,可以通过超频来提升CPU的游戏性能。
再者我一直觉得CPU的游戏性能问题有被夸大化的倾向。就拿我自己来说,除了锁帧的米哈游也就玩黑猴这样3A,虽然我自己使用的是RTX 4090,但GPU在这些3A中绝对不会有机会偷懒,因此CPU的游戏性能对于我来说是无所谓的。
现实情况是并不是所有人都是CS2/PUBG/APEX/永劫无间这样的电竞游戏玩家,也并不是每个人有480或者540 Hz的1080p高刷电竞显示器可以让高出的FPS显示出来,更不是每个人也都有RTX 4090让GPU性能过剩,实际大多数人还是使用着RTX 4070甚至3060,搭配着144 Hz的显示器玩着3A或者MMO,即使是对于玩这些这些电竞游戏的玩家,Ultra 200系列的游戏性能对于99%的人来说也都是绰绰有余的。虽然我说我的测试设置尽量接近真实玩家的游戏情况,但实际还是在夸大CPU性能差别和并制造了焦虑。
对于我而言我还是更为注重平台的日常使用体验,Ultra 200系列更低的功耗就意味着更少热量/更低的风扇转速和更低的噪音,并且就如本次测试的ROG Z890 HERO这样,Z890平台提供了更多的PCIe通道,还有原生的雷电4支持,整体有更强扩展性,这对于我这样的仓鼠党是有极大诱惑力的。
关联阅读:

















cctv凝
校验提示文案
moresure
校验提示文案
雨后青空
校验提示文案
cctv凝
校验提示文案
雨后青空
校验提示文案
cctv凝
校验提示文案
cctv凝
校验提示文案
moresure
校验提示文案