






















































158
30
J4125折腾笔记2.1 网卡测试补充
2021-10-21 10:19:18
19点赞
62收藏
10评论
创作立场声明:上一次的测试并没有把网络吞吐性能考虑进去,在这里补上
## 前言
上篇测试只是单纯的测试了网卡的最大带宽,这样操作好像有点不严谨,那这次就加上包转发性能的测试吧。
这里纠正一下上篇测试中的一些错误,iperf3 作为客户端的时候主要进行发包操作,服务端反而是进行接收的,所以上篇得出的上下行带宽实际上搞反了,不好意思。
测试计划
软路由系统依然使用自编译的 OpenWrt,单纯的使用路由功能,默认不开启任何附加功能,只单纯测试系统的转发性能
网卡模式主要选择上一期胜出的三种网卡模式
| 网卡直通 | bridge + virtio | macvtap + virtio | |
|---|---|---|---|
| 测试项目 | 网络吞吐量及 CPU 占用 | 网络吞吐量及 CPU 占用 | 网络吞吐量及 CPU 占用 |
测试工具依然使用 iperf3
测试标准
通常而言,网络设备的转发性能以 包转发性能 来表示,即设备在单位时间内能够处理多少个 包 决定了设备转发能力的强弱。在这里,无论是长包、还是短包都具有相同的包转发率(如果是超长包则需要考虑MTU 值的问题)。包转发性能比较常见的单位是 pps ,即 Packet Per Second (包每秒);Mpps,即 Mega Packet Per Second (百万包每秒);Kpps,即 Kilo Packet Per Second (千包每秒)。因此,设备是否能够达到线速通常以短包来进行计算,如果短包能够达到某一带宽的线速,则设备(或设备的接口)能够达到线速。以 64 字节短包计算(以太网规定最小的数据帧长度为 64Byte)。
从网络上查询到的信息可知:1000Mb = 1.488Mpps,也就是说网络设备要在千兆以太网环境下做到线速转发,必须每秒钟能转发 148.8 万个数据包,千兆带宽使用 bit 作为单位,那么 1000Mbit 换算成 Byte 的话就是 125MByte,使用网络中最小的 64Byte 进行计算的话 125MByte / 64Byte = 1.953Mpps,这个结果明显是有违查询到的结果的,那为什么会出现这样的偏差呢?这就要从以太网帧的构成说起了。
MTU 与 MSS
标准的以太网帧结构图如下所示:
 802.3
802.3
由图所示,一般情况下(排除 802.1Q,巨型帧等特殊情况,此处没有考虑 802.1Q 的 4Byte),以太网最大的数据帧是 1518Byte,刨去以太网帧的帧头,那么剩下承载上层协议的地方也就是 DATA 域最大就只能有 1500Byte,这个值我们就把它称之为 MTU (Maximum Transmit Unit,最大传输单元)。1500 是正常情况下 MTU 的最大值。
| 目的地址(DMAC) | 源地址(SMAC) | 类型(TYPE) | 数据(DATA) | 校验(CRC) |
|---|---|---|---|---|
| 6Byte | 6Byte | 2Byte | 46-1500Byte | 4Byte |
但上述 DATA 部分却并不能包含所有的传输信息,这里还需要考虑 MSS (Maximum Segment Size,最大分段大小),它们的关系根据协议不同如下所示:
UDP 包的 MSS 是 1500 - IP头(20) - UDP头(8) = 1472
TCP 包的 MSS 是 1500 - IP头(20) - TCP头(20) = 1460
MSS 受限于 MTU 的值,由于两者都是范围值,可以通过设置进行改变,但需要遵守一个原则: MSS 的值不能大于 MTU,MSS 部分承载了信息传输过程中的数据部分。
实际情况
在 TCP 协议中的最小以太网帧长度 64Byte = DMAC(6) + SMAC(6) + TYPE(2) + IP头(20) + TCP头(20) + 最小 MSS(6) + CRC(4),但在实际传输过程中,还需要加上 前导码(7),帧开始符(1),帧间距(12),才能正常通讯,所以实际上的最小帧长度应该是 84Byte。那么 125Mbit / 84Byte = 1.488Mpps,这样的话就对应上了查询到的数据。
测试遇到的问题
包转发性能一般情况下都是用专用设备进行测试的,这些设备都能模拟 64Byte 短包通信,但如果需要使用操作系统来测试的话,就会有一个问题,操作系统限制了 MSS 的最小值,Windows 和 Linux 的最小 MSS 值都是 88Byte,那么最小帧长度就做不到 84Byte 了,最小也要 166Byte(DMAC(6) + SMAC(6) + TYPE(2) + IP头(20) + TCP头(20) + MSS(88) + CRC(4) + 前导(7) + 帧开始符(1) + 帧间距(12)),那差距就有点大了。125MByte / 166Byte = 0.753Mpps,即使真能做到线速转发,这样的结果也比理论值差很多。
测试时可以通过 iperf3 的 -M 命令设置,低于 88 的话会报错
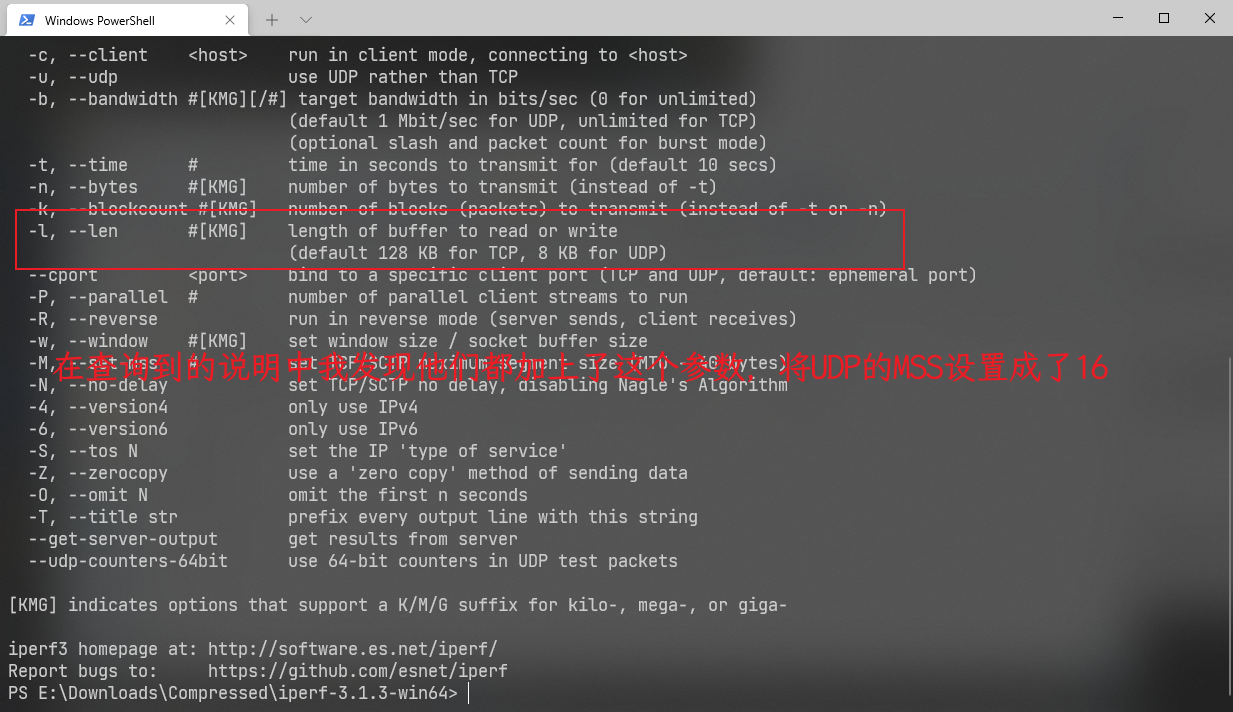 tcp-mss
tcp-mss
那是不是 iperf3 就不能用来测试吞吐量了?答案肯定不是。
为此我特意查询了几家云服务商的帮助页面,发现他们都是使用 UDP 协议进行测试的,iperf3 命令中特意手动设置了 -l 16 参数,相关文档如下:
根据上述帮助页说明,它们使用 iperf3 主参数数如下:
| 参数 | 参数说明 |
|---|---|
| -p | 端口号(使用默认即可) |
| -c | 接收端IP地址 |
| -u | UDP报文 |
| -b | 发送带宽 |
| -t | 测试时长 |
| -l | 数据包大小,测试 pps 时建议设置为 16 |
系统限制了 TCP 的最小 MSS,但并没有限制 UDP,那完全可以使用 UDP 进行测试,说干就干,当我打算测试的时候,突然想到如果这个16是数据长度的话,和 TCP 头什么的相加的话好像还小于 64Byte,这是什么情况呢!那就抓包看看到底是什么情况。
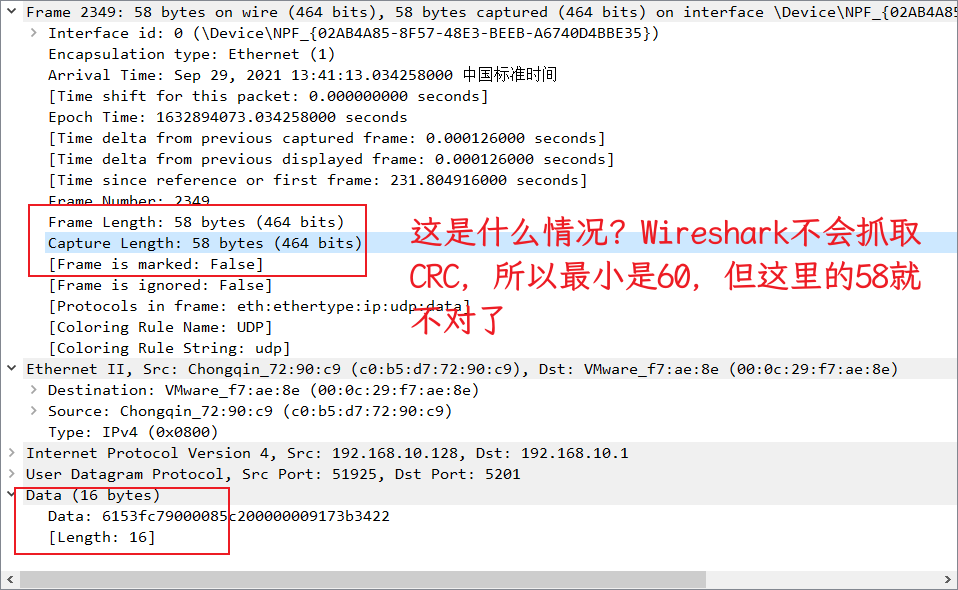 windows-udp
windows-udp
这是什么情况,抓包的结果有点让人郁闷,最小包都低于 64Byte 了,会不会是系统的原因,换个 Linux 测试一下!
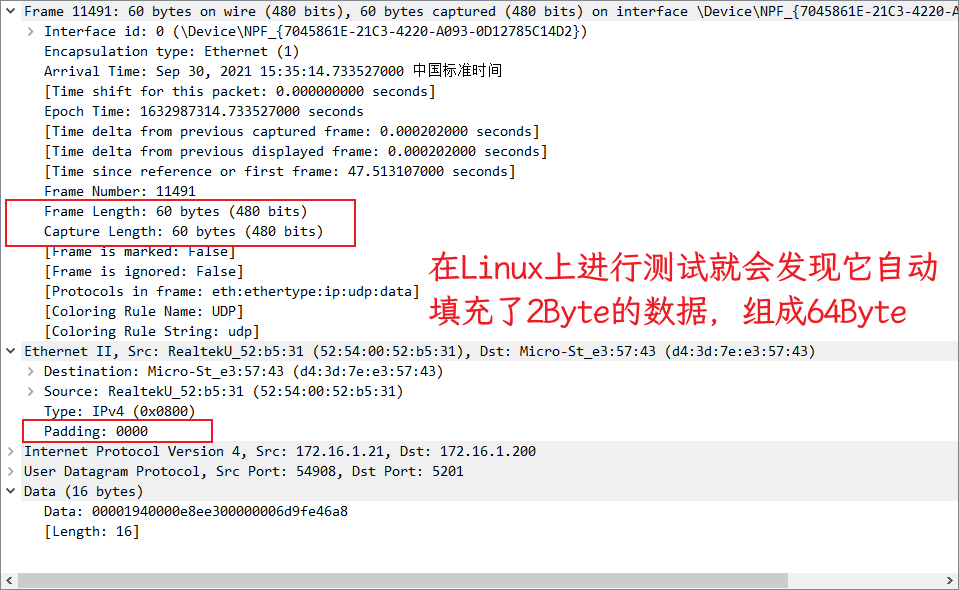 linux-udp
linux-udp
诶,在linux上测试怎么是正常的,从抓包上可以看出,相比于 Windows,在 Linux 上发出的包会有 2Byte 的额外数据帧,自动将其填充成了 64Byte 的最小包
所以,如果在 Windows 平台上进行测试的话,就需要把 -l 的参数设置成18才能得到 64Byte 的最小包,那么,最终的测试命令应该是,服务端:
iperf3 -s,客户端:iperf3 -c 172.16.1.200 -b 1000M -i 1 -t 100 -l 18 -u,每次测试持续 100 秒,最终通过转发的数据包数量除以时间就可以得到包转发性能。
测试过程
网卡直通:
WAN-LAN 下行测试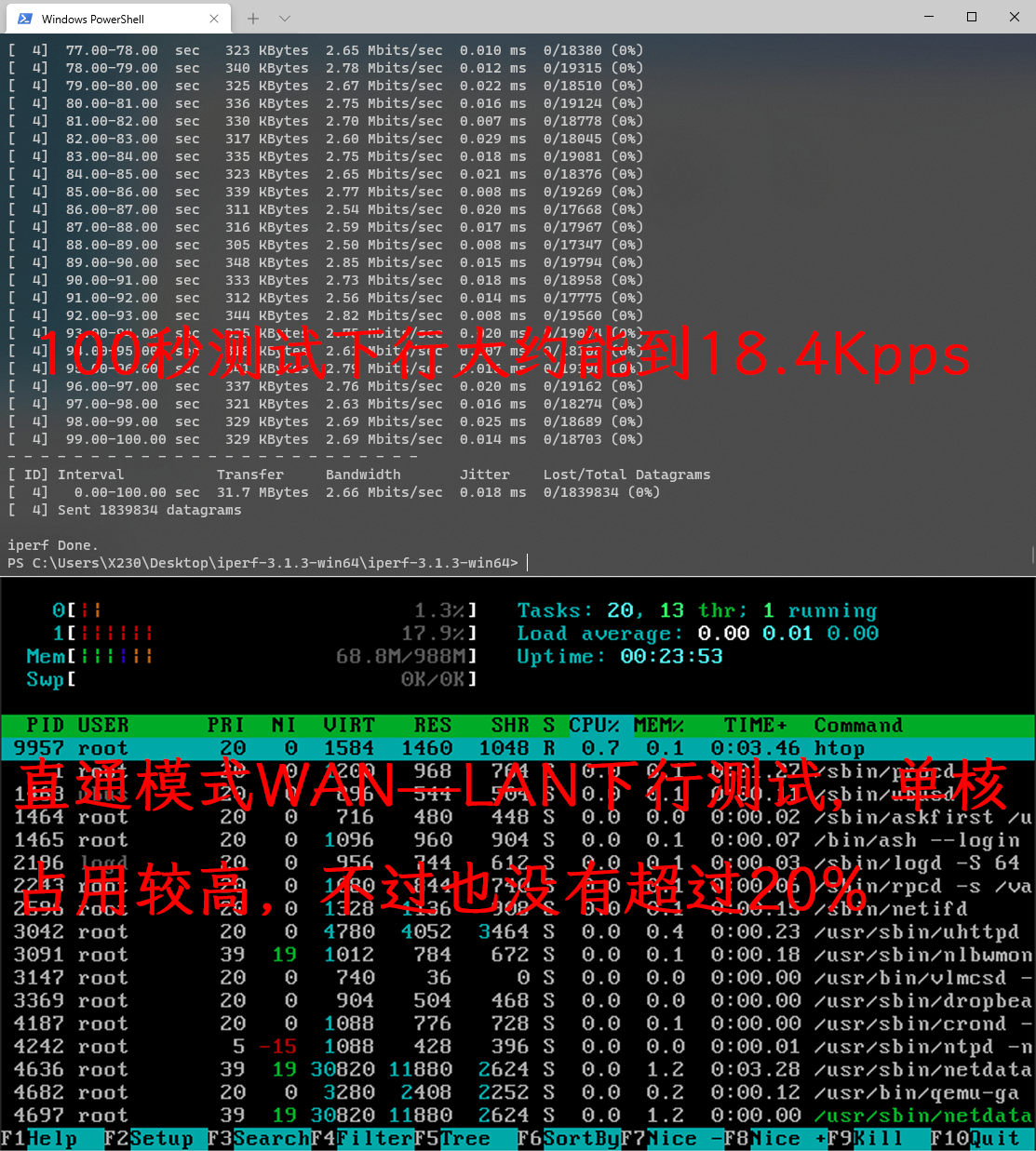 wan-lan
wan-lan
LAN-WAN 上行测试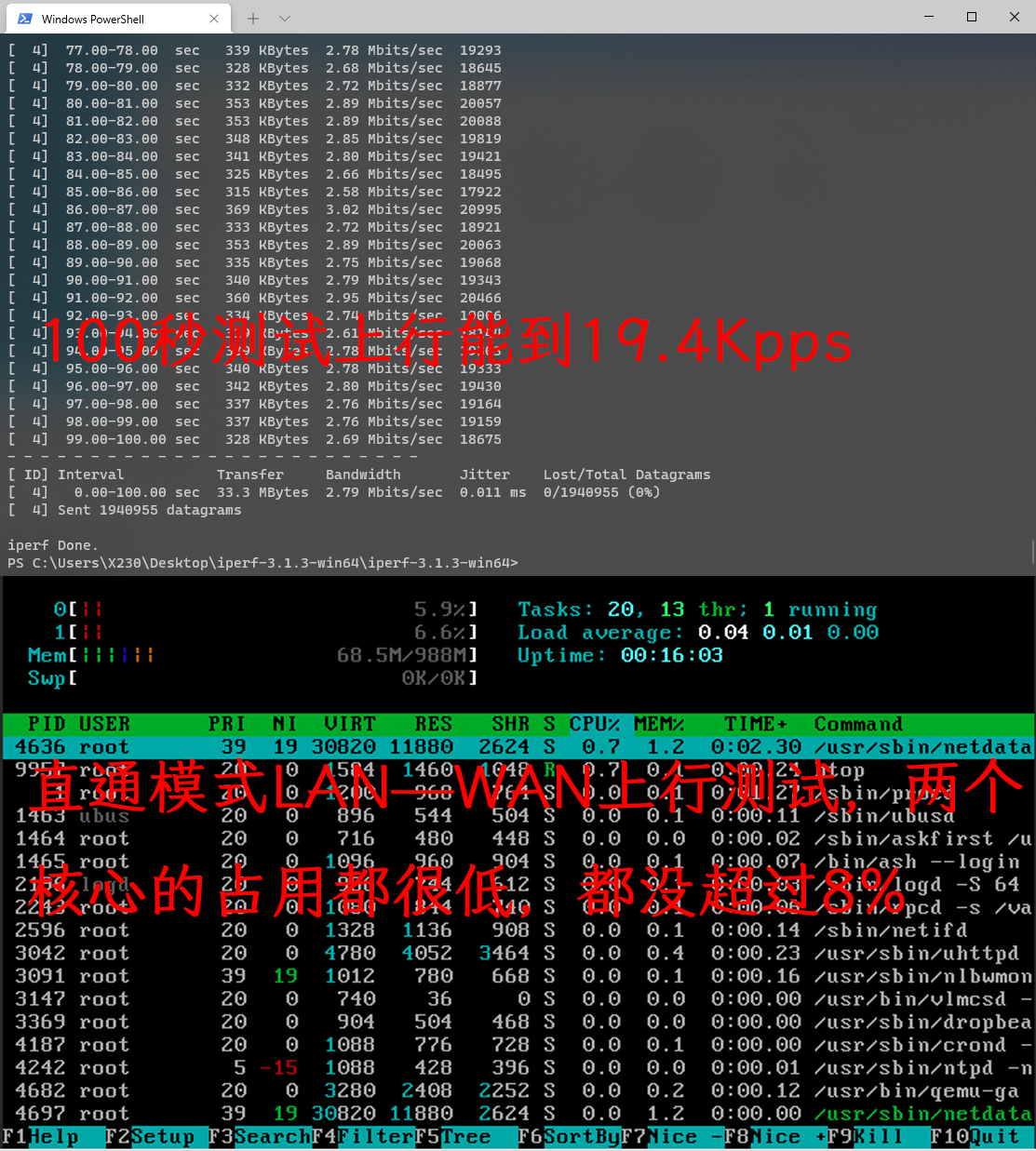 lan-wan
lan-wanbridge + virtio:
WAN-LAN 下行测试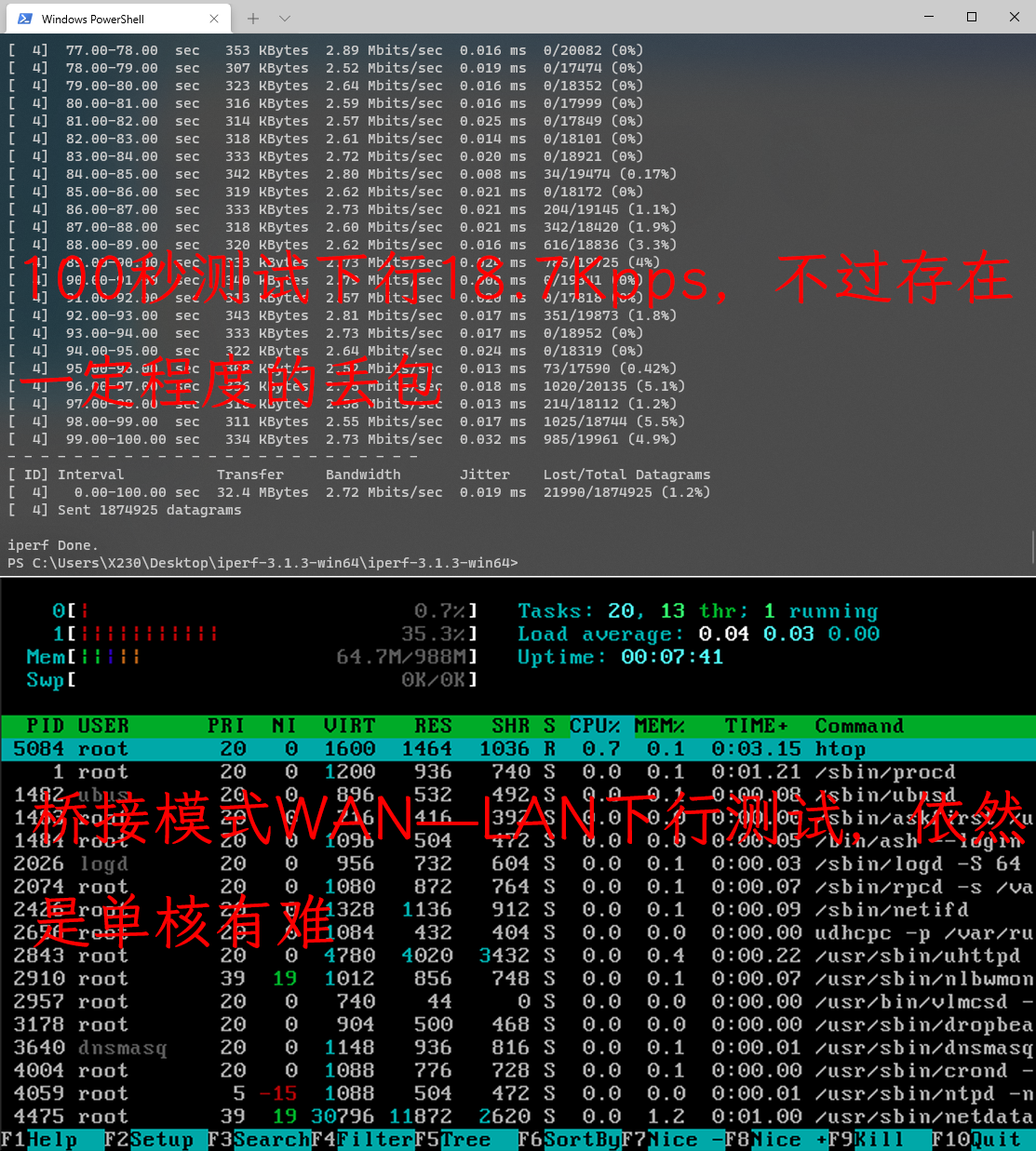 wan-lan
wan-lan
LAN-WAN 上行测试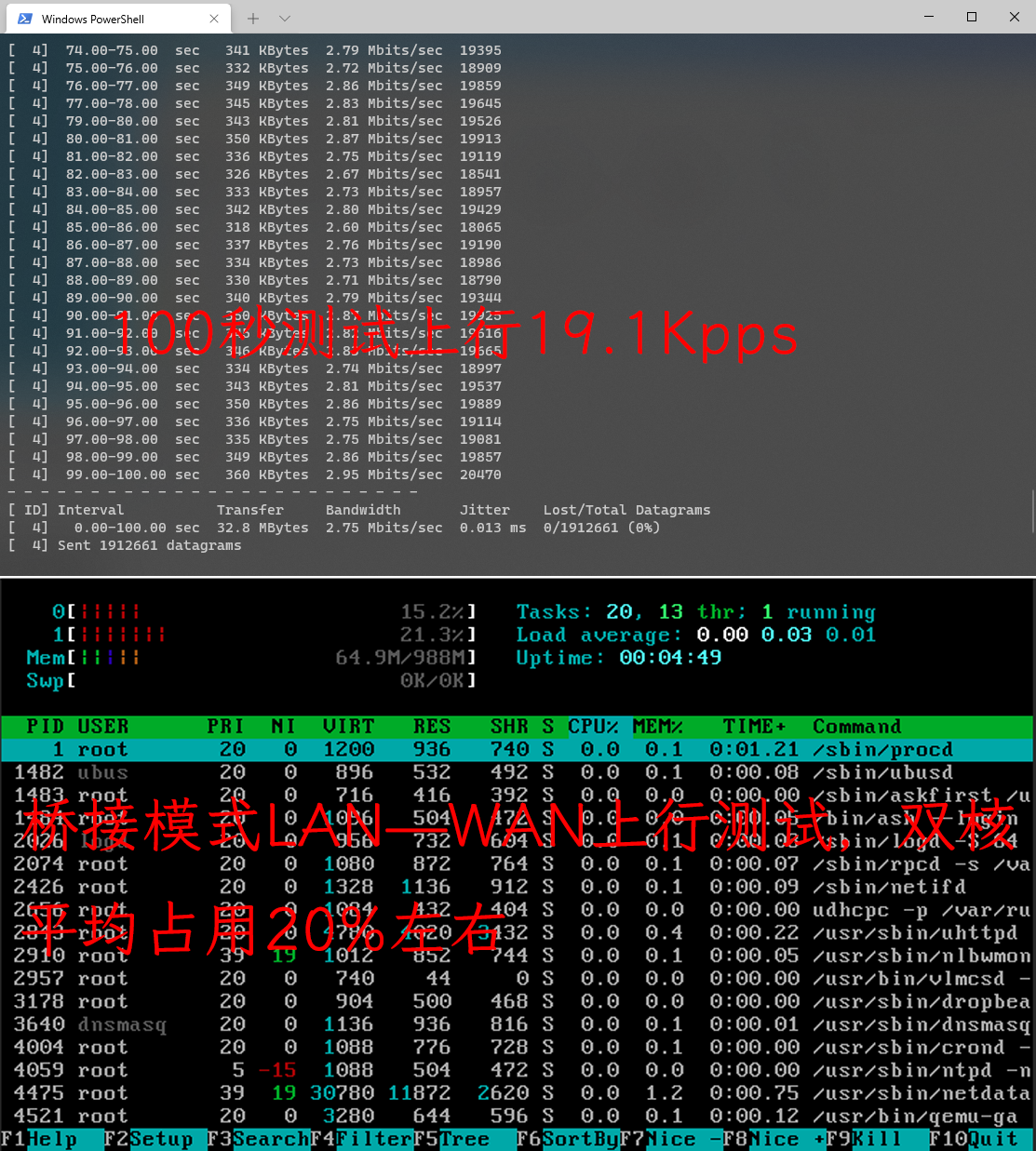 lan-wan
lan-wanmacvtap + virtio:
WAN-LAN 下行测试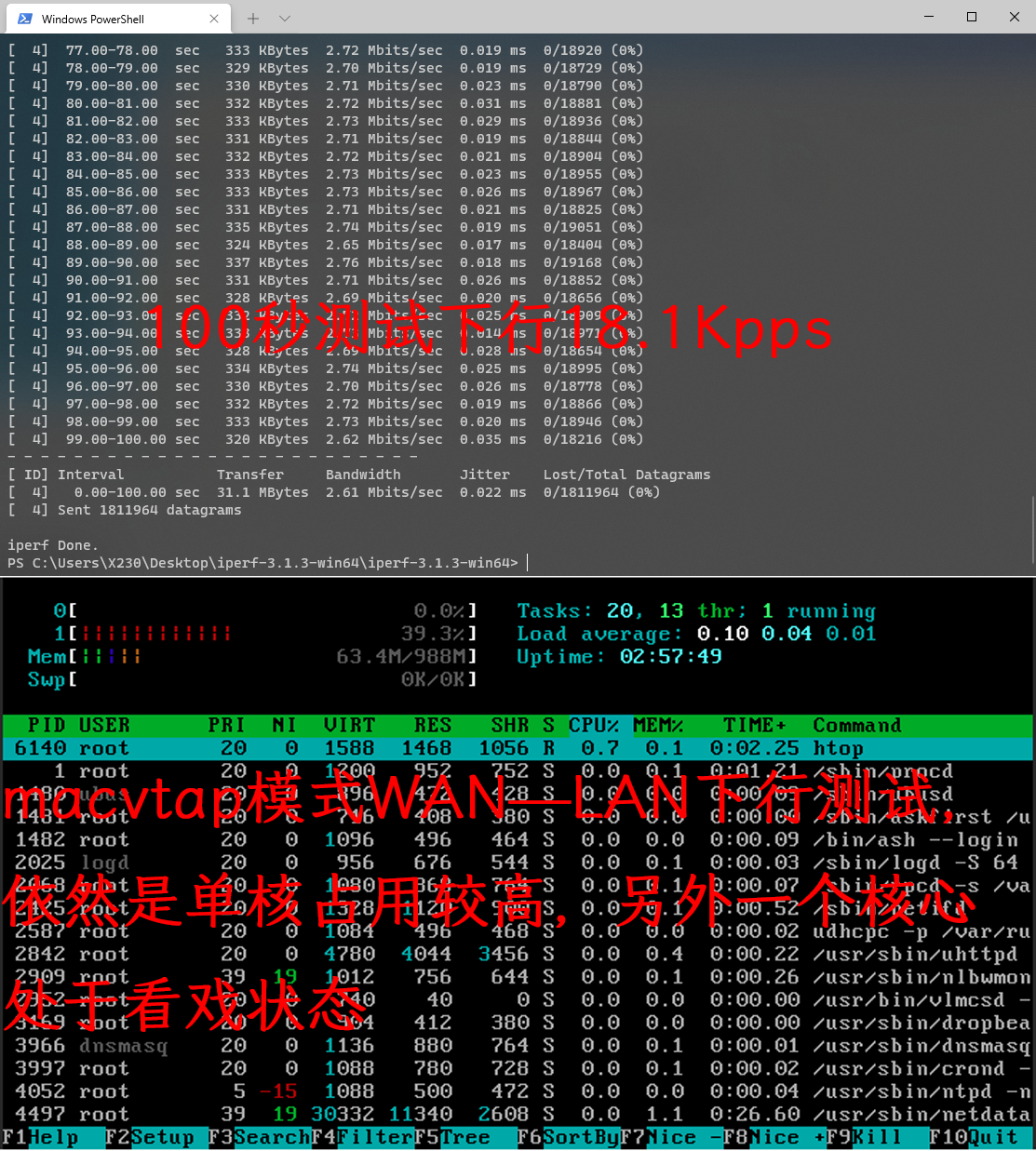 wan-lan
wan-lan
LAN-WAN 上行测试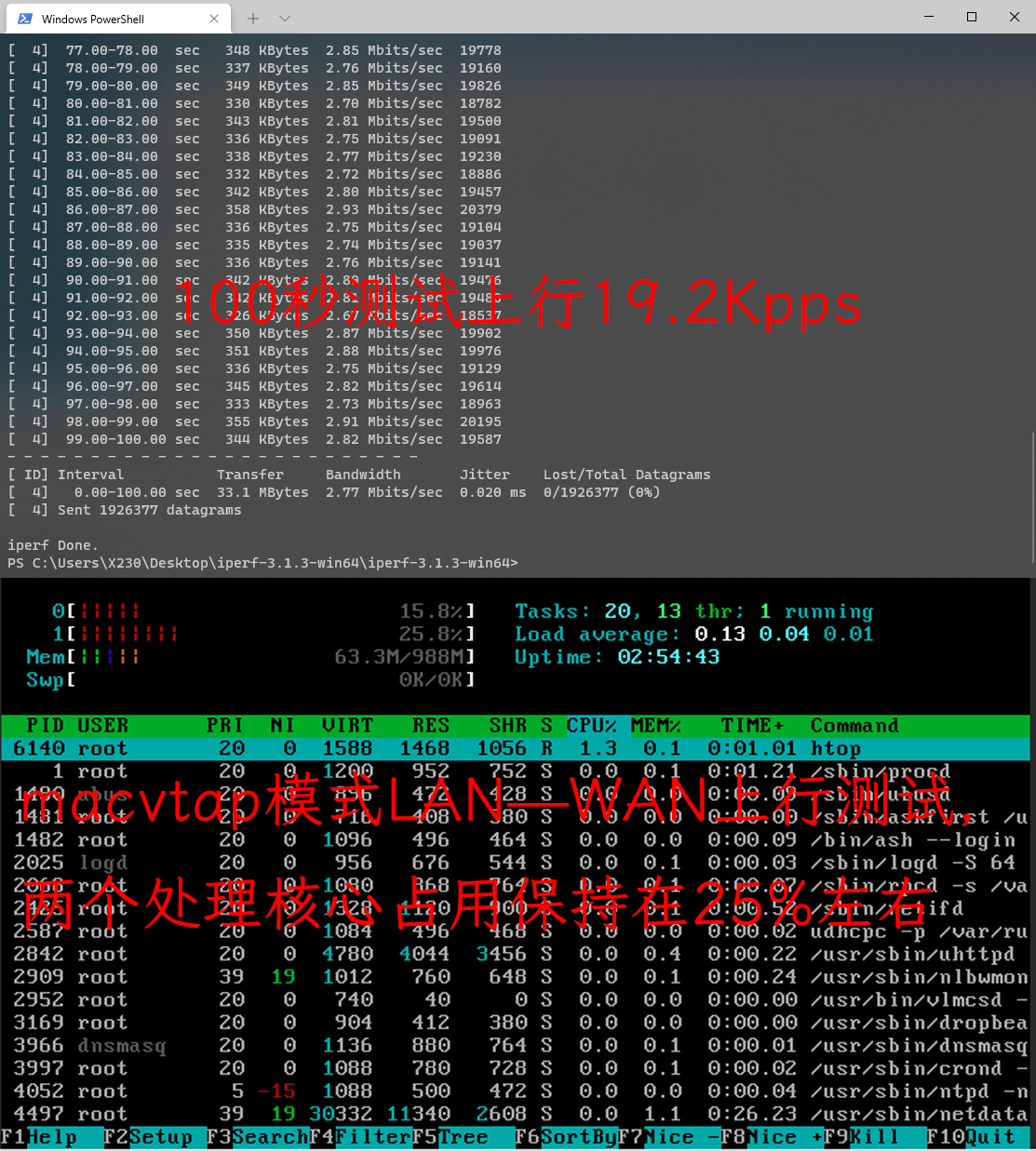 lan-wan
lan-wan
测试结果
| 网卡直通 | bridge + virtio | macvtap + virtio | |
|---|---|---|---|
| 下行 | 18.4Kpps | 18.7Kpps | 18.1Kpps |
| CPU占用 | 单核占用最高20% | 单核占用最高36% | 单核占用最高40% |
| 上行 | 19.4Kpps | 19.1Kpps | 19.2Kpps |
| CPU占用 | 双核占用不超过8% | 双核占用20%左右 | 双核占用25%左右 |
总结
通过这次测试,发现了以下问题:
桥接模式下会出现一定程度的丢包,不过它实际的带宽表现还不错,不是游戏玩家的话应该感受不出差别;
macvtap 模式与直通和桥接模式性能类似,但处理器占用相对而言最高;
直通模式下 CPU 占用率是最低的,其它两种模式虽然占用稍高,但和直通的差距并不算大;
下行测试普遍出现只有一个核心占用高,另一个核心基本没啥占用,很好奇再多点核心会不会出现一核有难,多核围观的情况?上行测试的时候没有出现上述的状况;
短包想要跑慢千兆线速,还是有点困难的,最起码 J4125 暂时是做不到的。
整体上还是直通的性能比较稳,能直通的话还是直通吧。
感觉自己瞎折腾一番最后还是回到了原点

















无货买个屁
不同虚拟机下直通会有差距嘛?
校验提示文案
bbsingao
你测这个不说拿个smartbit,至少要会dpdk吧,要还是太难,内核的pktgen总很简单嘛
校验提示文案
独孤HRU侠
校验提示文案
忍不住想剁手
校验提示文案
忍不住想剁手
校验提示文案
独孤HRU侠
校验提示文案
bbsingao
你测这个不说拿个smartbit,至少要会dpdk吧,要还是太难,内核的pktgen总很简单嘛
校验提示文案
无货买个屁
不同虚拟机下直通会有差距嘛?
校验提示文案