













































3
8
腾讯宣布做了一款全网“最丑”的验证码,“顺手帮个忙”能让医疗影像的标注和诊断变得更高效准确
2021-02-05 10:44:13
60点赞
64收藏
0评论
为了识别真人和机器人,如今的验证码越来越花哨,除了基本的数字字母,还出现了滑动、点击、挑选图案等多种验证码。
相信很多人遇到过街景验证码,让我们选中小轿车、路牌或是商店等图片。在费眼又费脑地挑选的同时,你其实是在为谷歌的人工智能免费打工。
今天,腾讯宣布做了一款全网“最丑”的验证码,清一色的黑白灰。
原来,这是腾讯和深圳大学一起搞的医学图像验证码。图像都是来自于临床上真实的脱敏医学图像。
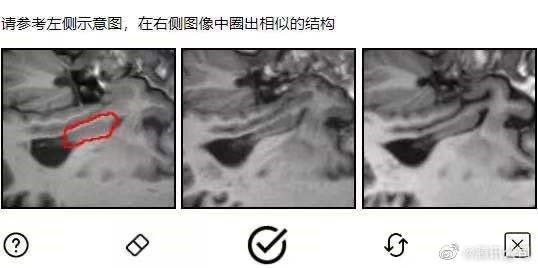
图源:微博@腾讯公司 下同
只要你“顺手帮个忙”,就能让医疗影像的标注和诊断变得更高效准确。
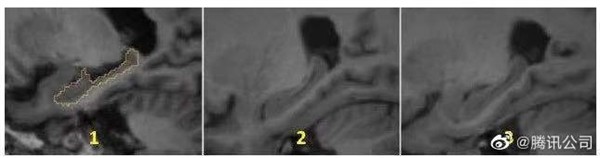
腾讯表示,这些被标注的医学图像,不再是冷冰冰的黑白影像,背后是鲜活涌动的生命力,和大家留下的点滴善意。
值得一的是,腾讯四位创始人马化腾、张志东、陈一丹、许晨晔,都是深圳大学89级学生,他们以腾讯创始人校友团队的名义,在2018年联合向母校深圳大学捐赠3.5亿元人民币,共同发起设立深圳大学人才基金,所捐款项将作为深圳大学人才基金的首笔启动资金。

本文经快科技授权发布,原标题:腾讯做了全网”最丑“验证码:清一色的黑白灰,文章内容仅代表作者观点,与本站立场无关,未经允许请勿转载。
















