












































































15
20
一分钟学会爬取网页文本内容
2021-08-27 23:50:22
310点赞
945收藏
19评论
创作立场声明:看到一款好软件,简单的操作可以替代繁杂的工作,推荐给大家。我也是刚刚接触,正在学习中,希望能够抛砖引玉。无利益相关。

今天再来看下怎么得到的网页上的信息。
操作过程
1.绑定浏览器
第一步还是绑定带有插件的浏览器。

2.获得网址
我们还是以某电影网站为例,获得最近电影的网址和名称。具体步骤看上一篇内容。

3.遍历arrayData
也就是逐个打开网页。使用自带的遍历。遍历字典和遍历数组都可以,使用略微有点不同,我这里使用略微麻烦点的字典。
 使用遍历字典,将字典名称改为arrayData。字典含键和值。
使用遍历字典,将字典名称改为arrayData。字典含键和值。
3.1在遍历的程序内打开网址
到这里就可以逐个打开网址了。
![注意将右边的加载链接替换为value[1]。](https://qnam.smzdm.com/202108/27/6128af5668c9d9648.jpg_e1080.jpg) 注意将右边的加载链接替换为value[1]。
注意将右边的加载链接替换为value[1]。
3.2创建电影同名文件夹
![注意将右侧的路径设置成你电脑想放的地方,后面的& value[0],是用电影的名字命名这个文件夹。value[0]是value里的第一个元素,也就是我们抓取到的电影名字。](https://qnam.smzdm.com/202108/27/6128b016a242d9627.jpg_e1080.jpg) 注意将右侧的路径设置成你电脑想放的地方,后面的& value[0],是用电影的名字命名这个文件夹。value[0]是value里的第一个元素,也就是我们抓取到的电影名字。
注意将右侧的路径设置成你电脑想放的地方,后面的& value[0],是用电影的名字命名这个文件夹。value[0]是value里的第一个元素,也就是我们抓取到的电影名字。
3.3获取文本信息
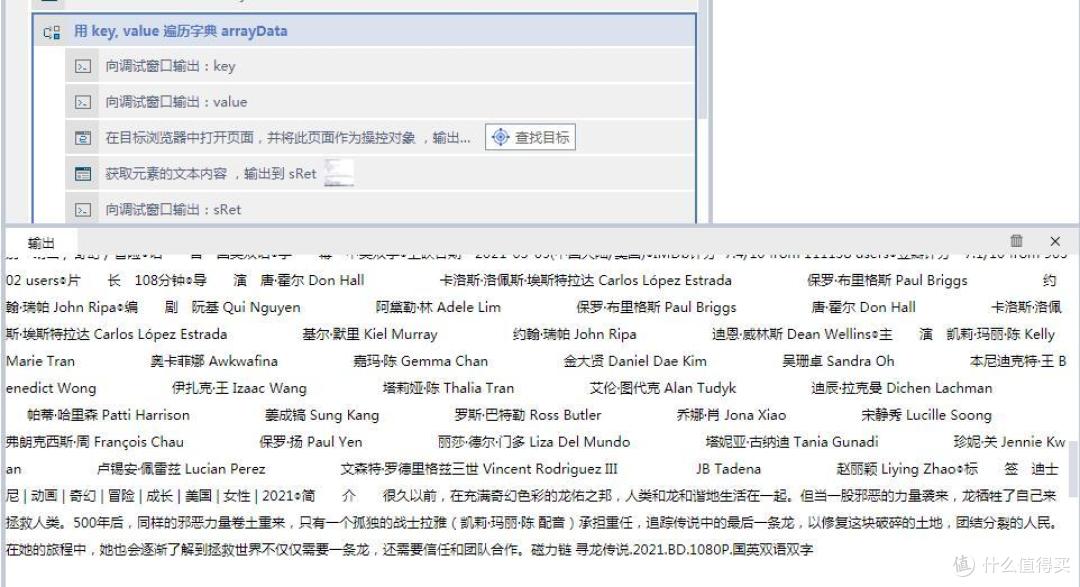
我们先看下网页中文本内容都有神马。
先使用获取元素文本内容,获取文字。点击红框中的部分,会出现一个箭头,将箭头指向需要获取的文本然后再点击。

就可以获得文字信息了。
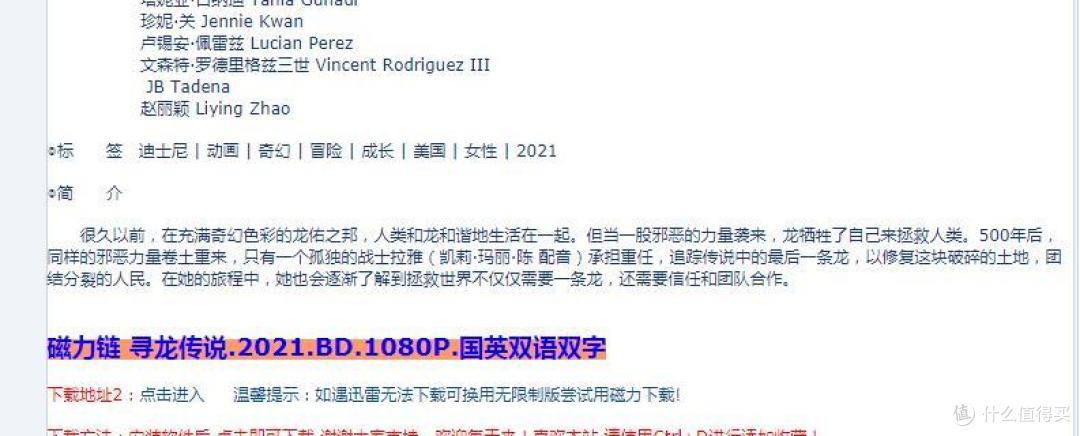
获取文本后,用打开文档(指向你想要打开的)--写入文档--另存为文档(存到新建文件夹里)--关闭文档,这几步就可以保存文字内容了。

是不是非常的简单?可以愉快的下载想看的文档和小说啦。

















耀哥哥的小理想
校验提示文案
值友1657774224
校验提示文案
值友9161565587
校验提示文案
啥也不是l
校验提示文案
考尼
校验提示文案
值友2800411101
校验提示文案
值友2757761994
校验提示文案
landswimmer
校验提示文案
shuffe
校验提示文案
思明
校验提示文案
shuffe
校验提示文案
landswimmer
校验提示文案
值友2757761994
校验提示文案
值友2800411101
校验提示文案
考尼
校验提示文案
啥也不是l
校验提示文案
思明
校验提示文案
值友9161565587
校验提示文案
值友1657774224
校验提示文案
耀哥哥的小理想
校验提示文案