































































8
16
采用台积电7nm制程的FPGA融入了ASIC机器学习能力,未来发展充满想象
2019-06-06 17:53:05
1点赞
5收藏
1评论
本文经半导体行业观察授权发布,原标题:《采用台积电7nm制程的FPGA融入了ASIC机器学习能力,未来发展充满想象》,文章内容仅代表作者观点,与本站立场无关,未经允许请勿转载。
对于正在发展过程当中的人工智能(AI),根据具体应用需求差异,不同的厂商会有符合其自身技术擅长和发展路径的差异化解决方案。总的来说,在过去几年,以及目前的发展阶段,利用FPGA实现AI功能具有较强的普遍适用性,特别是FPGA的灵活性,对于实现各种AI功能具有先天优势。而未来,各种专用的ASIC芯片也会陆续推出,以实现更强性能、更具针对性的AI应用功能。
那么,在今后几年,是否具有能将FPGA的灵活性与ASIC的高性能融合的AI解决方案呢?答案是肯定的,Achronix就在做这样的工作。
在过去几年,Achronix给我印象最深的就是其嵌入式FPGA方案,即通过为客户提供相应的IP,在SoC当中实现FPGA功能。而随着应用对性能的不断提升,特别是AI的兴起和应用落地,客户对FPGA提出了更多、更高的要求。因此,在提供IP的同时,Achronix也开始向具有大算力、高吞吐能力和高存储带宽的FPGA芯片领域扩军。
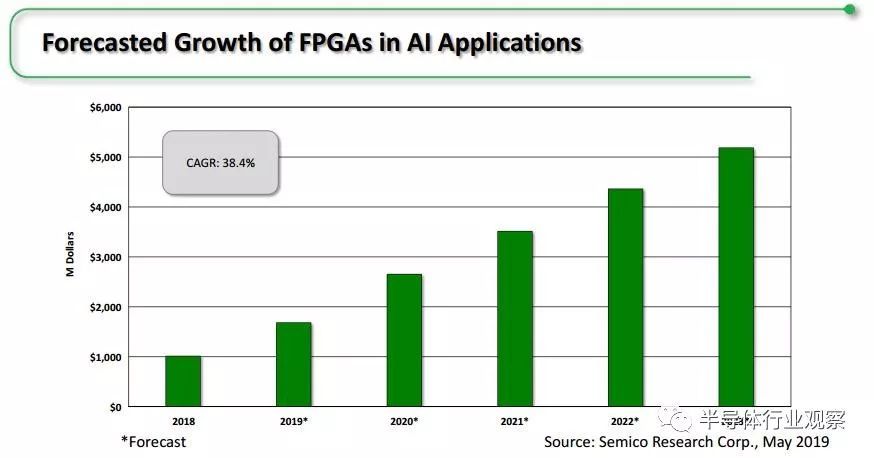
随着人工智能/机器学习的应用场景快速发展演进,新的解决方案都要应对在高性能、灵活和上市时间等方面的不同需求。市场调研公司Semico Research预测,人工智能应用中FPGA的市场规模将在未来4年内增长3倍,达到52亿美元。
前些天,Achronix正式宣布推出Speedster7t系列FPGA,主要针对人工智能/机器学习(AI/ML)和高带宽数据加速应用。据悉,该品基于一种高度优化的全新架构,包括一个全新二维片上网络(2D NoC),以及一个高密度机器学习处理器(MLP)模块阵列。特色就是具有如同ASIC一样的性能,以及可简化设计的FPGA灵活性和增强功能。
据Achronix总裁兼首席执行官Robert Blake先生介绍,在过去3年时间里,该公司的工程师投入了大量的精力,用于第四代FPGA产品Speedster7t的研发。在开发该系列FPGA的过程中,Achronix的工程团队重新构想了整个FPGA架构,以平衡片上处理、互连和外部输入输出接口(I / O),以实现数据密集型应用吞吐量的最大化,这些应用场景可见于那些基于边缘和基于服务器的AI / ML应用、网络处理和存储。

不仅如此,在过去10年内,该公司一直专注于高端FPGA产品的研发和销售。主要针对高性能的数据加速,用于高性能计算机和网络处理。
Speedster7t采用了台积电7nm FinFET制程工艺制造,是专为接收来自多个高速源的大量数据而设计,同时还需要将那些数据分发到可编程片上处理性单元中,然后以尽可能低的延迟来提供结果。Speedster7t系列具有高带宽GDDR6接口、400G以太网端口和PCI Express Gen5等接口,所有这一切单元都互相连接以提供ASIC级带宽,同时保留FPGA的完全可编程性。

该产品应用很广泛,特别是AI,以及5G的网络处理,还有一些传统应用,如安防等,都可以用这款芯片实现。
除了硬件,软件也非常重要,特别是对于FPGA来说更是如此,能与硬件紧密配合越来越重要。Robert Blake表示,我们的软件已经准备好,客户现在就可以使用,而相应的硬件会在今年第四季度交到客户手里。
当今,AI算法越来越多样化,各种应用需要更多针对性强的算法,功耗和成本也很敏感,因此,要想满足各种需求,芯片当中的定点和浮点应用选择和权衡很重要。
Robert Blake表示:“我们的芯片主要考虑三方面要素:一是算力;二是高效的数据传输能力,这里,高带宽很重要;三是高效的存储和缓存能力。而这三点综合考虑和设计是难点,也是我们的优势所在。我们的硬件和软件工程师做了大量的研究工作,以使产品同时具有FPGA的灵活性,以及ASIC的性能,我们称之为FPGA+。”
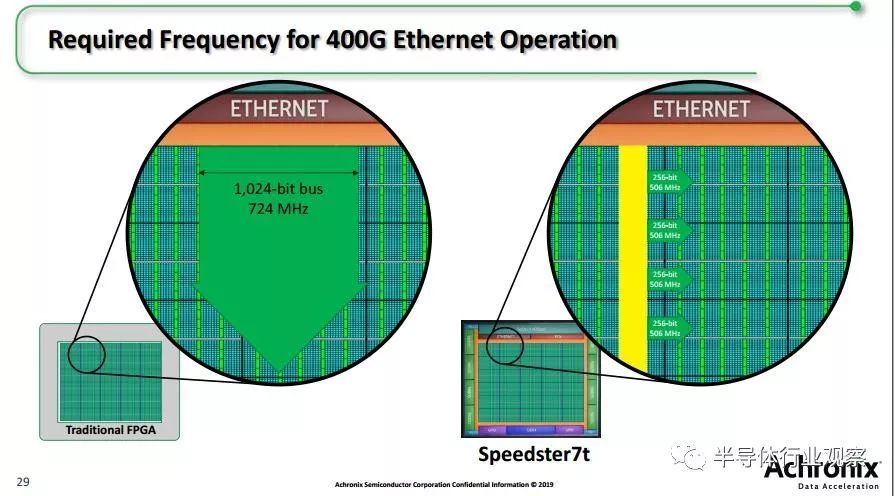
片上网络NoC产品speedster7t当中,具有片上网络NoC,其建立了高速的片内通路,可以使信号和数据在芯片内部快速传输。它们就像是叠加在FPGA互连城市街道系统上的空中高速公路网络一样,Speedster7t的NoC支持片上处理引擎之间所需的高带宽通信。NoC中的每一行或每一列都可作为两个256位实现,单向的、行业标准的AXI通道,工作频率为2GHz,同时可为每个方向提供512 Gbps的数据流量。

最重要的是,NoC消除了传统FPGA使用可编程路由和逻辑查找表资源在整个FPGA中移动数据流中出现的拥塞和性能瓶颈。这种高性能网络不仅可以提高Speedster7t的总带宽容量,还可以在降低功耗的同时提高有效LUT容量。
总之,NoC可以简化硬件工程师的工作,更智能,更灵活。
MLPspeedster7t的另一个特色就是具有机器学习计算单元MLP,可以提升网络处理的算力。
MLP是高度可配置的、计算密集型的单元模块,可支持4~24位的定点格式和高效的浮点模式,包括对TensorFlow的16位格式的支持,以及可使每个MLP的计算引擎加倍的增压块浮点格式的直接支持。
MLP与嵌入式存储器模块紧密相邻,通过消除传统设计中与FPGA布线相关的延迟,来确保以750 MHz的高性能将数据传送到MLP。这种高密度计算和高性能数据传输的结合,使得处理器逻辑阵列能够提供基于FPGA的最高可用计算能力以每秒万亿次运算数量为单位(TOPS,Tera-Operations Per Second)。
简单来讲,MLP对应传统FPGA的DSP,据称,其平均处理能力是DSP的5倍。
高性价比的GDDR6
高速存储接口也重要,以使数据可以快速进出芯片,这方面,speedster7t一个亮点就是采用了美光公司的GDDR6方案,这也是FPGA业界第一个采用该外挂式存储方案的产品。目前,业界更多的是采用集成封装式的HBM存储方案,与之相比,外挂式的GDDR6方案,在性能方面与前者基本相当,但总体系统成本却可降低50%。HBM由于需要采用特殊的衬底材料,以及先进的InFO封装,使得成本在短期内难以降下来。
据Robert Blake介绍,每个GDDR6存储控制器都能够支持512 Gbps的带宽,Speedster7t器件中有多达8个GDDR6控制器,可以支持4 Tbps的GDDR6累加带宽,以很小的成本就可提供与基于HBM的FPGA等效存储带宽。

另外,Speedster7t还具有72个高性能SerDes接口,可以达到1~112 Gbps的速度。还有带有前向纠错(FEC)的硬件400G以太网MAC,支持4x 100G和8x 50G的配置,每个控制器有8个或16个通道的硬件PCI Express Gen5控制器。
400G以太网方面,由于以太网包的大小各不相同,FPGA片内的功能块和逻辑单元大小也不同,如何匹配应用需求呢?传统FPGA处理这些,需要很多条件和限制,Achronix的IP产品则有办法应对,其可以根据实际数据和运算量需求,使运算资源灵活应对,如NoC可以将400G分成4个100G去处理。
 应用
应用
谈到Speedster7t的应用时,Robert Blake表示,图像处理是其应用之一。另外,该FPGA新品不止用于云端,在边缘侧的某些应用也可以使用,如5G的某些应用场景。实际上,边缘侧也是个广义的概念,并不只是那些绝对低功耗和低成本的边缘侧,在数据中心侧也有相对其为边缘的计算应用需求,这里对性能要求也很高。
目前,Speedster7t的相关基础软件已经供货,如ACE设计工具,在即将到来的第三季度,一些高层的应用工具也将推出,可以支持Caffe2等开放的AI平台。年底,相应的硬件和开发板将会正式发售给客户。
在FPGA方案综合供给能力方面,Achronix也颇具特色,因为其即可以提供芯片硬件,还可以提供IP,另外,该公司还能提供用于chiplets的裸片die,比业界其它几家FPGA企业提供的产品更全面。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第1956期内容,欢迎关注。

















值友3423906600
校验提示文案
值友3423906600
校验提示文案