




























































3
3
有问有答:CPU浮点运算和整点运算分别决定其什么性能?
2019-03-05 18:21:10
76点赞
354收藏
45评论
简单来讲在现代计算机环境下的日常使用中,整点运算性能影响如压缩与解压缩,计算机进程调度,编译器语法分析,计算机电路辅助设计,游戏AI处理类型的操作。而浮点运算单元主要影响CPU的科学计算性能,如流体力学,量子力学等,而更贴近我们日常能见到的应用就是多媒体相关的应用,如音视频的编解码,图像处理等操作。
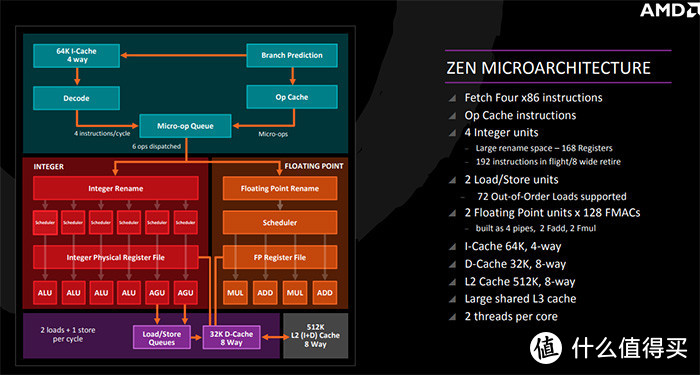 ZEN的核心架构图
ZEN的核心架构图
而我们通常在测试CPU时使用如Sandra 2018,Super Pi,wPrime,Fritz Chess Benchmark,WinRAR,7-zip,x264 FHD Benchmark等软件,这些测试软件就能够体现处理器理论整数运算单元和浮点运算单元性能的。
在具体使用的软件中,如压缩解压软件WinRAR,7-zip,程序员使用的GCC编译器,网络路由的选择,游戏中的AI以及我们日常试用操作系统调度都是整点运算。而我们在使用lightroom等图像处理软件,语音识别,视频的编解码,以及科学家使用Matlab进行科学计算时都用到了浮点运算能力。
对于玩家最关心的就是这些到底对游戏有什么影响。首先CPU承担着整个计算机中的任务进程分配问题,所以如果游戏代码优化不好,进行频繁的Draw Call操作,会非常消耗CPU任务调度资源。同时现在游戏AI做操作行为判断时,也是使用整点运算单元的。而现在很多游戏加入了防盗版机制,在运行游戏时频繁的加解密会消耗浮点运算性能。所以有朋友使用较老的硬件运行新游戏时,会非常影响游戏运行帧率。
所以整点运算性能和浮点运算性能都反映了CPU处理数据的能力。但是整点运算性能还反映了控制程序流的的能力。

在计算机中,定点数不一定是整数,而浮点数也不一定是小数。在计算机中,定点数是指小数点固定的数,而浮点数是指小数点不固定的数。在计算机中采用IEEE 754标准进行浮点数的存储的,他可以精确的的表示某一个数据。
在早期浮点运算单元并没有一开始就加入到CPU设计中的。但是在计算机中,运算单元都是逻辑电路,由浮点数的定义我们可以知道,在早期仅有整点数运算单元而不带有浮点数处理单元的 处理器上,处理浮点数的阶码、尾数的计算以及规格化就成为了很困难的事情,导致早期CPU在科学计算中依旧非常的缓慢。所以Intel就设计了独立于8086和8088处理器外的8087数学辅助处理器。到后来随着计算机不再是科学家的工具,也逐渐进入了公众视野,Intel在80486DX处理器核心内首次集成了浮点运算单元。
 Intel 8087协处理器
Intel 8087协处理器
 Intel Core i7 7700k处理器的CPU-Z信息
Intel Core i7 7700k处理器的CPU-Z信息
早期的Intel x87系列数学运算辅助处理器只是作为一个提高浮点运算速度的处理器,而在现代处理器中,浮点计算功能会通过SIMD(Single Instruction Multiple Data,单指令多数据流)的技术实现并行计算能力。在打开CPU-Z后,开支持指令集一栏可以看到,现代处理器带有的SSE指令集就有处理浮点运算的能力。而在之后的发展中,也逐渐引入了SSE2,SSE3,SSE4,AVX,FMA等更加适用于现代软件开发的拥有强大浮点运算能力的指令集。
那接下来就有问题了,现代处理器加入了很多高度并行化的浮点运算单元,相较以往单纯CPU的浮点运算能力有了非常大的飞跃,但是相对于现代的图形处理器来说,这么些浮点运算能力是不够看的,那为什么不像几十年前一样不在CPU中集成浮点运算单元呢??
 Nvidia Geforce 256核心照片
Nvidia Geforce 256核心照片
对于这个问题,首先大家要了解为什么会独立出来图形处理器这种专有硬件的。在20世纪90年代,计算机多媒体逐渐开始兴盛起来,在1998年到1999年间,Intel和AMD的CPU中已经拥有了SSE或3DNow!这样的SIMD浮点运算指令集。但是随着电子游戏的发展,计算机的使用者对于计算机的图形性能有了更高的要求,但是此时的CPU内浮点运算性能并不满足需求,所以在此后图形处理器开始负担更多的浮点运算工作。
 Nvidia CUDA核心工作流程
Nvidia CUDA核心工作流程
但图形处理器的使用者看到如此高效能的浮点运算处理器的时候就在思考如何能让这类设备承担除了图形计算之外的浮点计算性能。乘着GPGPU(General-purpose GPU)概念的逐渐兴起,显卡上的统一渲染架构的出现,也让这种计算方式真正成为现实。Nvidia在2007年正式发布了CUDA并行计算平台。之后也出现了如openCL的通用计算API(应用程序编程接口)。
到此我们突然发现,GPU都来抢CPU的浮点运算饭碗了,但为什么CPU非但没有取消浮点运算单元,反而其浮点运算性能越来越强??
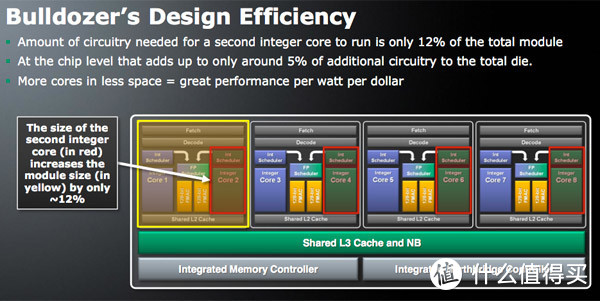 AMD推土机架构示意图
AMD推土机架构示意图
其实并不是没有人想到这样的情况,而是已经与产品这么做了,就是AMD的推土机架构。这个架构放弃了之前的一个核心就由一套整数运算单元和浮点运算单元的组合,而是让两个核心共享一个浮点运算单元组成一个簇,而AMD将这种架构叫做CMT,又称为群集多线程技术,之后又将相对与Intel有优势的GPU核心集成进CPU中,产生了APU处理器。AMD当时还为此成立了HSA基金会,为解决CPU和GPU的内存统一寻址问题,也提出了hUMA技术并用在了Sony的PS4游戏机上。
 Sony Playstation 4主机,CPU和GPU共享8GB GDDR5内存
Sony Playstation 4主机,CPU和GPU共享8GB GDDR5内存
那为什么厂商做了这么多还是做不到用大规模的GPU取代CPU中的浮点运算单元呢?运算精度才是重点。CPU中的浮点运算单元是为了更高精度浮点运算准备的。如在最新Intel处理器中的AVX指令集可以处理512位扩展数据,这样大大提升了计算精度和速度。而GPU中的处理器都是为高度并行计算而设计的结构相对简单的核心,这些核心每一个都是SIMD处理器,但是能够处理的数据精度是有限的,在Nvidia以及AMD图形处理器上支持的数据精度大多是单精度和双精度浮点计算(FP32和FP64),甚至随着机器学习,深度学习,神经网络的流行,最新的图形处理器甚至支持了半精度浮点运算(FP16)。其次,由于在计算精度上相较于CPU中的浮点运算单元不高,所以在这些处理器中也没有内置数据校验和数据补偿处理的运算单元。所以对于使用GPU进行科学计算的人,需要在编程阶段就避免这样的问题。同时CPU和GPU在设计上就是非常不同的,CPU的浮点单元个数很少,但是单个浮点运算单元所提供的性能是很强的。而GPU中是用过海量的SIMD单元堆砌出来的浮点运算能力。在CPU设计时,还需要设计大量的多级缓存来提高CPU的运算速度。而GPU中通常只为这些SIMD处理单元内置不多的缓存,而提供大量的内存(显存)。
所以综合上面的分析,我们可以得出的结论是虽然GPU拥有更强大的浮点运算性能,但是限于其计算单元的设计,统一内存架构的设计,其还是不能完全取代CPU中的浮点运算核心。CPU中的整点运算单元在肩负着如压缩解压,编译器编译程序,网络路由,控制程序流等任务同时,其浮点运算核心也依旧在处理着图像处理,科学计算等需要更高精度计算的任务。

















一叶月光
校验提示文案
wqzxhpx
校验提示文案
打不死的小强666
需求:有限元科学计算,此类计算依赖主频,对线程数不敏感
您觉得对于此类科学计算而言,以下两款CPU哪一款更合适,暂不考虑价格
I9-9900K 5GHZ (无AUX512指令集)
I9-9900X 4.4GHZ (有AUX512指令集)
校验提示文案
Klairy
校验提示文案
zysun
校验提示文案
斑马苏怡
校验提示文案
lookingliudi
校验提示文案
nfsnfs
校验提示文案
新忘情水
校验提示文案
普罗米修平房顶漏雨
校验提示文案
samurai
校验提示文案
Reneiw
校验提示文案
永远亲爱的你
校验提示文案
浪子1510
校验提示文案
jacyjay
校验提示文案
贝格菲斯
校验提示文案
jmaska
校验提示文案
矮脚长颈鹿
校验提示文案
矮脚长颈鹿
校验提示文案
jmaska
校验提示文案
贝格菲斯
校验提示文案
jacyjay
校验提示文案
浪子1510
校验提示文案
永远亲爱的你
校验提示文案
Reneiw
校验提示文案
samurai
校验提示文案
普罗米修平房顶漏雨
校验提示文案
wqzxhpx
校验提示文案
新忘情水
校验提示文案
nfsnfs
校验提示文案
Klairy
校验提示文案
lookingliudi
校验提示文案
斑马苏怡
校验提示文案
打不死的小强666
需求:有限元科学计算,此类计算依赖主频,对线程数不敏感
您觉得对于此类科学计算而言,以下两款CPU哪一款更合适,暂不考虑价格
I9-9900K 5GHZ (无AUX512指令集)
I9-9900X 4.4GHZ (有AUX512指令集)
校验提示文案
zysun
校验提示文案
一叶月光
校验提示文案