





























































































7
8
OpenAI ChatGPT上线图像库功能:多模态协同升级AI生成管理
2025-04-16 12:12:55
0点赞
0收藏
0评论
根据 OpenAI 公司于 4 月 16 日在社交平台发布的官方消息,其旗下人工智能产品 ChatGPT 正式上线了名为 Image Library 的图库功能。这项新功能旨在帮助用户更便捷地管理和浏览通过 AI 生成的图像。目前该功能已向所有免费用户以及 Plus、Pro 订阅用户开放,优先上线 iOS 移动端应用,网页版预计将在短期内完成部署。
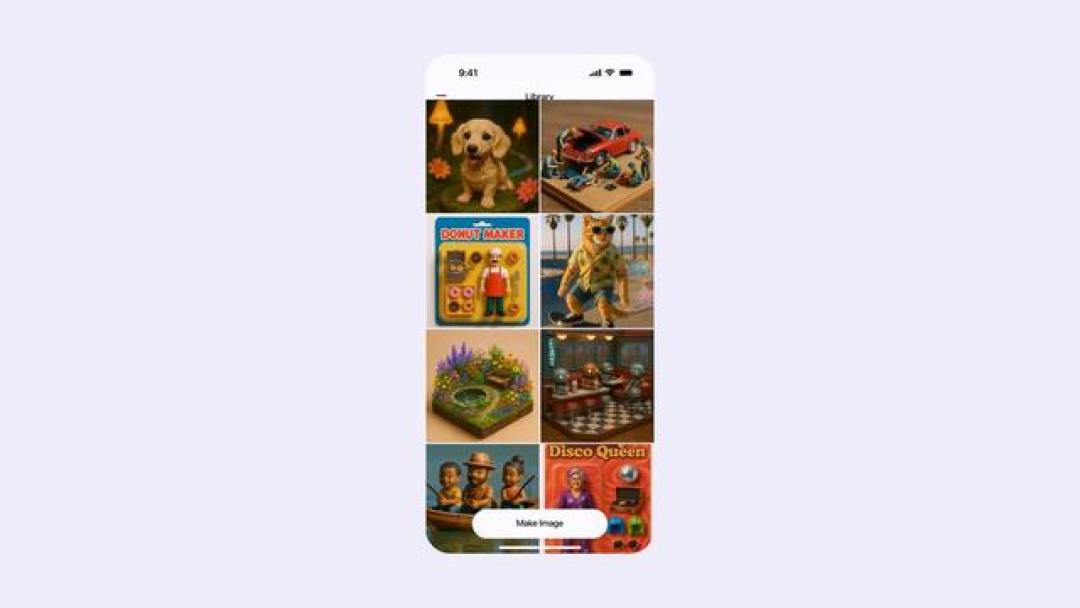
从实际体验来看,用户点击 ChatGPT 侧边栏的“Library”入口后,可以直接进入一个以网格形式展示的图片库界面。所有通过 AI 生成的图像会按时间顺序自动归类,屏幕底部还设置了悬浮按钮供用户随时创建新图像。对于需要高频生成设计素材、艺术创作或个性化内容的用户,这项功能解决了过往生成图片分散难寻的痛点,例如用户可快速回溯此前创作的吉卜力风格作品或特定主题的视觉内容。
值得注意的是,本次更新与 OpenAI 近期对 GPT-4o 模型的升级形成协同效应。该多模态模型不仅支持原生图像生成,还能通过对话持续优化输出结果。例如在生成菜单设计或游戏界面时,用户可通过自然语言指令调整细节,而系统能保持角色形象和画风的一致性。相较于前代模型 DALL-E 3,新版本在文字渲染精度、复杂场景还原方面均有提升,但也存在生成速度较慢、部分非拉丁语文字易出错等技术局限。

在版权保护方面,OpenAI 表示已设置策略防止生成直接模仿在世艺术家风格的图像,同时提供了创作者申请作品退出训练集的渠道。不过从用户实测反馈看,系统对部分受版权保护元素(如辛普森家族角色)的识别仍存在滞后性,需在生成完成后触发限制提示。
此次更新正值谷歌 Gemini 等竞品强化图像生成能力之际。根据官方披露,ChatGPT 的周活跃用户数在近期呈现爆发式增长,图像类功能的普及可能进一步加速这一趋势。不过随着生成式 AI 工具引发的版权争议增多,如何在技术创新与内容合规之间取得平衡,仍是行业面临的共同挑战。
















