































































7
17
老黄抛出2700W功耗真核弹 还有240TB显存的AI超级计算机
2024-03-19 21:00:13
31点赞
48收藏
161评论
时隔5年,全球顶尖AI计算技术盛会、年度NVIDIA GTC大会重磅回归线下,英伟达创始人兼CEO黄仁勋发表长达123分钟的主题演讲,发布AI芯片最新震圈之作——Blackwell GPU架构,以及基于此的B100/B200 GPU芯片、GB200超级芯片、DGX超级计算机,傲视全球。

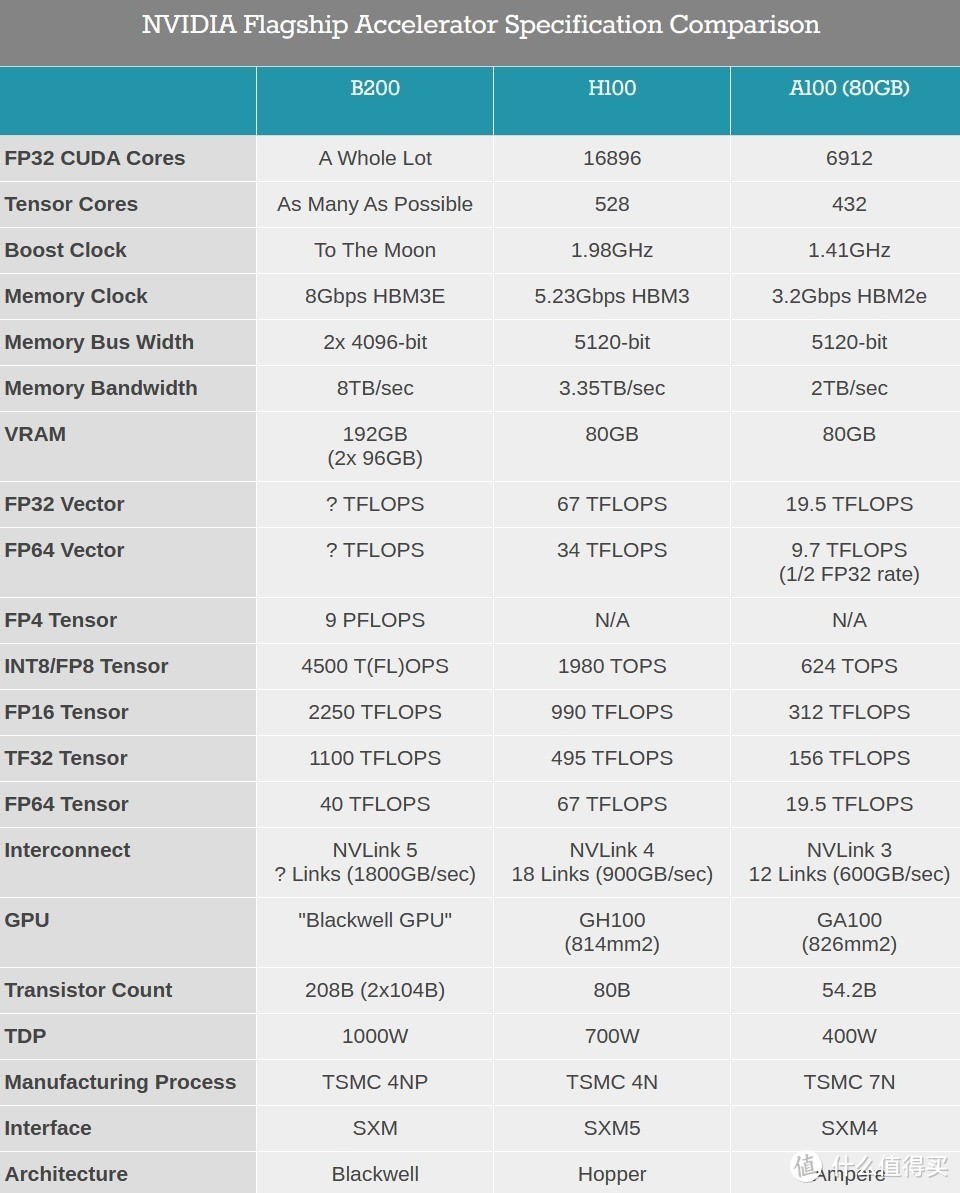
号称是“世界最强大的芯片”:集成2080亿颗晶体管,采用定制台积电4NP工艺,承袭“拼装芯片”的思路,采用统一内存架构+双芯配置,将2个受光刻模板(reticle)限制的GPU die通过10TB/s芯片间NVHyperfuse接口连一个统一GPU,共有192GB HBM3e内存、8TB/s显存带宽,单卡AI训练算力可达20PFLOPS。
跟上一代Hopper相比,Blackwell因为集成了两个die,面积变大,比Hopper GPU足足多了1280亿个晶体管。对比之下,前代H100只有80GB HBM3内存、3.35TB/s带宽,H200有141GB HBM3e内存、4.8TB/s带宽。

第二代Transformer引擎:将新的微张量缩放支持和先进的动态范围管理算法与TensorRT-LLM和NeMo Megatron框架结合,使Blackwell具备在FP4精度的AI推理能力,可支持2倍的计算和模型规模,能在将性能和效率翻倍的同时保持混合专家模型的高精度。
在全新FP4精度下,Blackwell GPU的AI性能达到Hopper的5倍。英伟达并未透露其CUDA核心的性能,有关架构的更多细节还有待揭晓。

第五代NVLink:为了加速万亿参数和混合专家模型的性能,新一代NVLink为每个GPU提供1.8TB/s双向带宽,支持多达576个GPU间的无缝高速通信,适用于复杂大语言模型。
单颗NVLink Switch芯片有500亿颗晶体管,采用台积电4NP工艺,以1.8TB/s连接4个NVLink。

RAS引擎:Blackwell GPU包括一个确保可靠性、可用性、可维护性的专用引擎,还增加了芯片级功能,可利用基于AI的预防性维护来进行诊断和预测可靠性问题,最大限度延长系统的正常运行时间,提高大规模AI部署的弹性,一次可不间断地运行数周甚至数月,并降低运营成本。
至于功耗,B100控制在700W,和上代H100完全一致,B200则首次达到了1000W。英伟达宣称,Blackwell GPU能够在10万亿参数的大模型上实现AI训练和实时大语言模型推理。
GB200 Grace Blackwell是继Grace Hopper之后的新一代超级芯片(Superchip),从单颗GPU+单颗CPU升级为两颗GPU加一颗CPU,其中GPU部分就是B200,CPU部分不变还是Grace,彼此通过900GB/s的带宽实现超低功耗片间互联。
在大语言模型推理工作负载方面,GB200超级芯片的性能对比H100提升了多达30倍。不过代价也很大,GB200的功耗最高可达2700W,可以使用风冷,更推荐使用液冷。

基于GB200超级芯片,英伟达打造了新一代的AI超级计算机“DGX SuperPOD”,配备36块超级芯片,也就是包含36颗Grace CPU、72颗B200 GPU,彼此通过NVLink 5组合在一起,还有多达240TB HBM3E。
这台AI超级计算机可以处理万亿参数的大模型,能保证超大规模生成式AI训练和推理工作负载的持续运行,FP4精度下的性能高达11.5EFlops(每秒1150亿亿次)。
DGX SuperPOD还具有极强的扩展性,可通过Quantum-X800 InfiniBand网络连接,扩展到数万颗GB200超级芯片,并加入BlueField-3 DPU数据处理单元,而每颗GPU都能获得1.8TB/s的高带宽。
第四代可扩展分层聚合和规约协议(SHARP)技术,可提供14.4TFlops的网络计算能力,比上代提升4倍。

英伟达还发布了第六代通用AI超级计算平台“DGX B200”,包含两颗Intel五代至强处理器、八颗B200 GPU,具备1.4TB HBM3E、64TB/s带宽,FP4精度性能144PFlops(每秒14亿亿次),万亿参数模型实时推理速度提升15倍。
DGX B200系统还集成八个英伟达ConnectX-7网卡、两个BlueField-3 DPU高性能网络,每个连接带宽高达400Gb/s,可通过Quantum-2 InfiniBand、Spectrum-X以太网网络平台,扩展支持更高的AI性能。

基于Blackwell GPU的产品将在今年晚些时候陆续上市,亚马逊云、戴尔、谷歌、Meta、微软、OpenAI、甲骨文、特斯拉、xAI等都会采纳。

















钱又不用自己印
校验提示文案
sss668800
校验提示文案
爱优V
校验提示文案
aktoooo
校验提示文案
Jacky君
校验提示文案
值友7947477860
校验提示文案
Adanserver
现在的ai路线完全是数据库+搜索引擎的升级版,哪怕sora本质上也是把数据库里用游戏引擎渲染出来的影音模块组起来,仅此而已。
你说这东西能提升生产力,它也就只能降低文娱影音搜索行业。
工业上根本不需要这种所谓ai,因为那些工业仿真软件等等本身就是类似这种ai的数据库仿真软件和辅助软件。
迄今为止ChatGPT也出现挺久了,到现在还只能通过卖会员变现点,想走工业路线根本没它位置。
校验提示文案
nkyzhxxfx
校验提示文案
AMC陶
校验提示文案
锦衣卫
校验提示文案
该已经被注册
校验提示文案
Gintak233
校验提示文案
值友1135033755
校验提示文案
大叔的话要听听
校验提示文案
sobe
校验提示文案
值友8135917901
校验提示文案
originoore
校验提示文案
沉思的阳光
校验提示文案
值友8847674082
校验提示文案
尼古拉斯-刘二
校验提示文案
天天逛大妈是种病
校验提示文案
coolyizong
校验提示文案
一只猫123
校验提示文案
亩大小的
校验提示文案
苹果大爷
校验提示文案
morok2008
校验提示文案
黑风山老妖
校验提示文案
machcat999
校验提示文案
双重幻想
校验提示文案
16年的煤球
校验提示文案
sobe
校验提示文案
好好的2023
校验提示文案
西京雪
校验提示文案
叔本华是俺偶像
校验提示文案
Adanserver
现在的ai路线完全是数据库+搜索引擎的升级版,哪怕sora本质上也是把数据库里用游戏引擎渲染出来的影音模块组起来,仅此而已。
你说这东西能提升生产力,它也就只能降低文娱影音搜索行业。
工业上根本不需要这种所谓ai,因为那些工业仿真软件等等本身就是类似这种ai的数据库仿真软件和辅助软件。
迄今为止ChatGPT也出现挺久了,到现在还只能通过卖会员变现点,想走工业路线根本没它位置。
校验提示文案
大叔的话要听听
校验提示文案
值友1097715730
校验提示文案
圆圆的重光
校验提示文案
aktoooo
校验提示文案
迪迦老祖
校验提示文案