









































17
22
新王的诞生--ASUS GEFORCE GTX1080公版民用评测
2016-09-02 16:34:51
265点赞
250收藏
67评论
目录
前言
第一章、外观
第二章、拆解
第三章、架构
第一节、GP104构架的GTX1080
第二节、GP100构架的TESLA P100
第三节、GM204构架的GTX980
第四节、架构对比
第四章、TSMC 16nm FinFET +
第五章、GPU BOOST 3.0
第六章、GDDR5X
第七章、测试
第一节、测试平台装机SHOW
第二节、基准测试
1、基础信息
2、解码支持
3、3DMARK
4、烤机测试
5、VR STREAM测试
6、AIDA64 GPGPU通用计算测试
7、显卡杀手级游戏测试
第八章、杂谈公版
总结
新王的诞生--ASUS GEFORCE GTX1080评测
前言

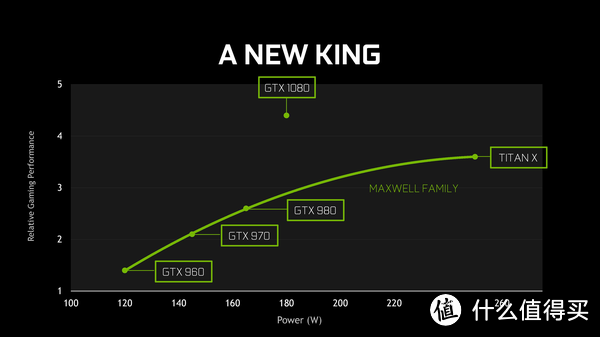
GEFORCE GTX 1080可以说是近三年来比上一代效能提升最大的显卡,NVIDIA三年来终于有一次没有挤牙膏,除了刚刚发布还没有进入国内的新TITAN X,暂时GTX 1080仍然是NVIDIA民用显卡的的新王。
基本信息:
GeForceGTX1080拥有2560个CUDA处理器,核心频率1607MHz,boost频率1733MHz,拥有8GBGDDR5X显存,等效显存频率10GHz。显卡位宽为256bit,带宽320GB/s。采用单8pin供电,TDP180w,单精度浮点运算运算能力是9Teraflops,原生支持8K分辨率。
第一章、外观
拿到ASUS的公版GTX1080真是一个意外,原本可能是每个品牌各一张,随机发货的,结果看来可能我和华硕有缘。



三面观,华硕的公版显卡包装一直很多年保持着同样的风格,我所见到的TITAN如是,GTX980如是,现在1080也如是。

8GB GDDR5X显存是GTX1080一个最大的看点,简单理解GDDR5X就是GDDR5的BOOST。

开始对FOUNDERS EDITION还是比较模糊的,发布之前各种猜测超公版的概念,结果其实就是公版而已。

NVIDIA的GEFORECE GTX VR READY认证,VR READY是一个前瞻趋势。

3年质保,坚若磐石。

显卡一些特性的印刷介绍

内盒

华硕公版卡的内包装真是简单到不能再简单了。

显卡、说明书、光盘、质保卡,没了。

取下PCIE金手指、IO接口、SLI金手指上的塑料套。

泰坦皮升级版,很多人对棱角分明的新泰坦皮褒贬不一,就拍照来说,多边形更有利于细节的勾勒。

这次采用的涡轮风扇应该是酷冷代工,62%转速2400多转几乎没有任何声音。有时候改变都是在沉默之中悄悄的UPDATE了,你不一定知道,但是它客观存在。

GTX信仰LOGO

金手指上方的NVIDIA标志是公版的象征。

涡轮风扇的前置进风口

全金属背板,这次NVIDIA没有在背板螺丝处设计易碎标,看来是可以随便拆散热器也不会影响保修了。

公版血统标签

大大的信仰绿灯

SLI金手指

单8PIN供电

显卡的下侧面

IO接口是一个DVI,3个DP1.4,一个HDMI2.0四接口。
第二章、拆解

首先卸掉IO挡板

两截式背板,里附塑料纸隔离,防止金属背板和PCB接触发生短路

风扇罩上的GTX1080 LOGO说了很久的LED特效呢?

显卡上下部的金属格条

大部分人拆到这里会有点茫然,没事,下掉背板之后,这里的散热片是没有螺丝固定的可以直接取出。


散热片底部采用均热板设计

拆卸风扇罩上的螺丝,需要注意的是别扯坏下面的2PIN线。


全金属风扇罩

一般拆到这里大家就会收手,说反正核心也暴露出来了,看看就行了,其实是因为这里需要特殊的工具才可以直接拆下去,要拆掉PCB上的散热片需要从PCB背面下手。

PCB背面的螺丝是特制的外六角,一般工具无法开启。

我使用南旗的工具套筒直接给下了,


下完背面所有螺丝之后,散热片分离,PCB暴露出来了。

PCB背面

PCB正面

PCB的核心区特写

GPU核心:GP104-400-A1

显存:镁光6HA77 D9XTS GDDR5X显存,单颗1GB容量,32bit位宽,8颗正好组成256bit,8GB的显存阵列。

GTX 1080采用了4+1+1相供电设计,每相都是一个上下桥复合MOS,4相核心供电,1相显存供电,还1相供电做平衡。这个用料只能说中规中矩,并无豪华可言,供电上的空焊点很多,想必是为GTX1080TI预留的。
第三章、架构
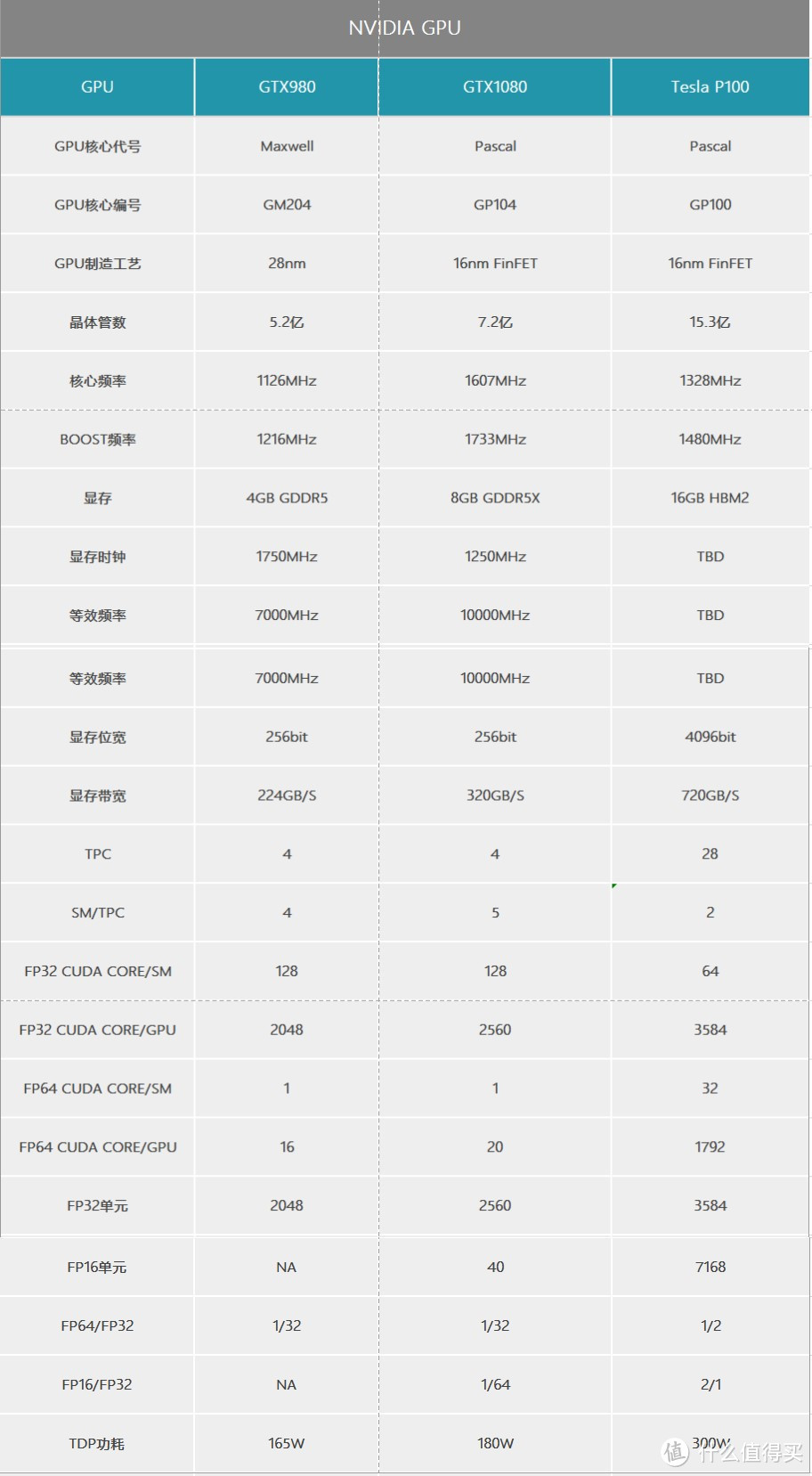
我收集了一下GTX1080/TESLA P100/GTX980的公版数据,汇总成图,其中有很多可能和各大媒体的解读有出入,无碍,技术交流并不存在去伪存真,只存在不停的认知。架构解析的目的是辨识GTX1080究竟是传承自谁的架构。
第一节、GP104构架的GTX1080
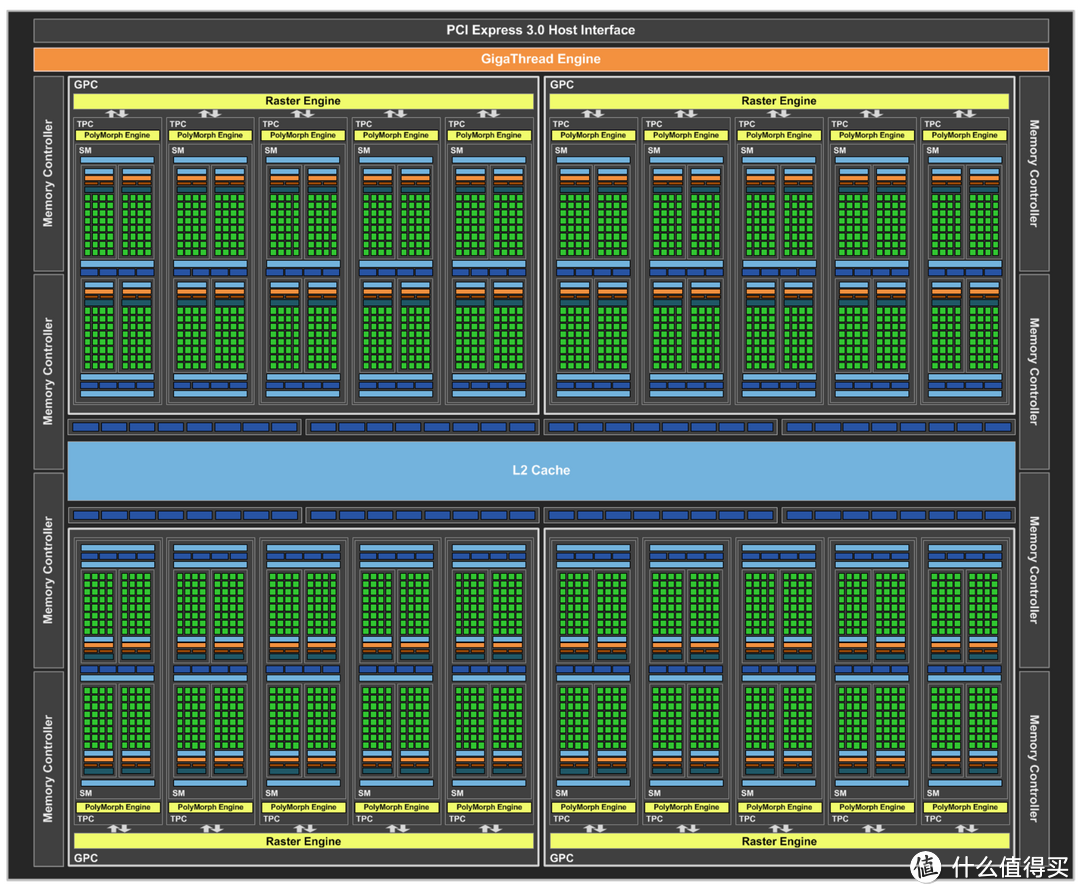
GTX 1080核心代号GP104,上图为GP104的“完整”架构,其实说完整有点过,NVIDIA官方给的图原本就不完整,缺失了双精度计算单元,这个我们后面再说。
GP104包含4组显卡处理器集群(GPC)
每个GPC有5个流处理器组(SM)
每个SM有128个CUDA单元(CUDA CORE)
共计2560个CUDA单元
8组32bit显存控制器,每组连接8个ROP单元和256KB L2缓存。总位宽是256bit,ROP单元64个,L2缓存2048KB。

这是官方给出的流处理器组(SM)架构图,其实缺失了双精度计算单元(DP UNIT)
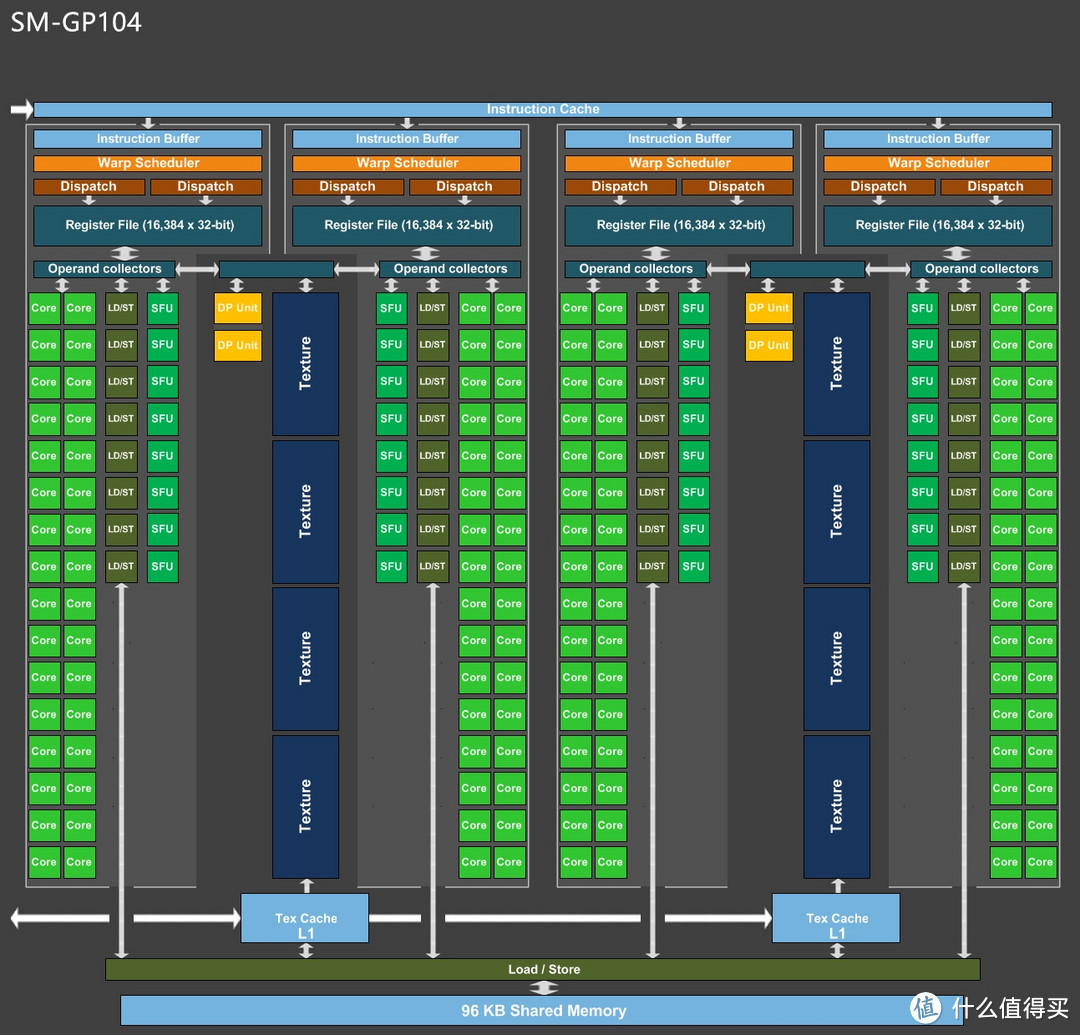
修正后的GP104架构图
SM修正后的架构图里有包含单精度浮点和整数运算单元的CUDA CORE,双精度运算的DP Unit,计算各种特殊函数例如sin/cos的SFU。每个SM含有4个黄色的DP UNIT和128个绿色的CUDA CORE。
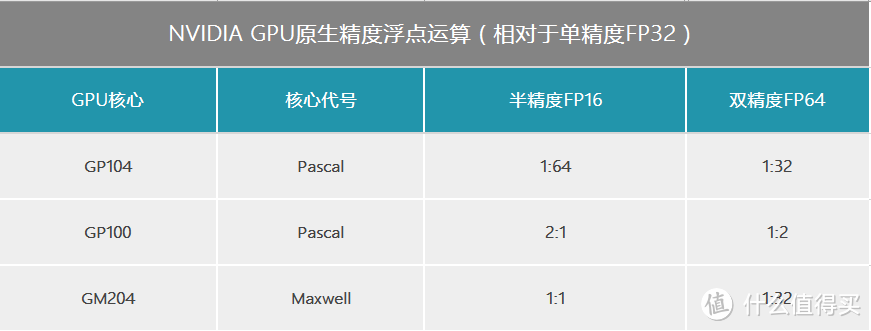
所以运算能力上,FP64(双精度):FP32(单精度)=4:128=1:32
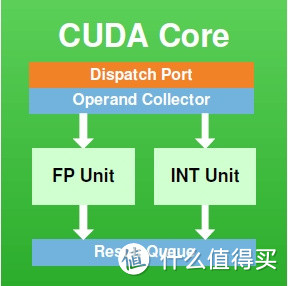
每个CUDA CORE由浮点运算单元(FP Unit)和整数算术逻辑单元(INT Unit)组成。
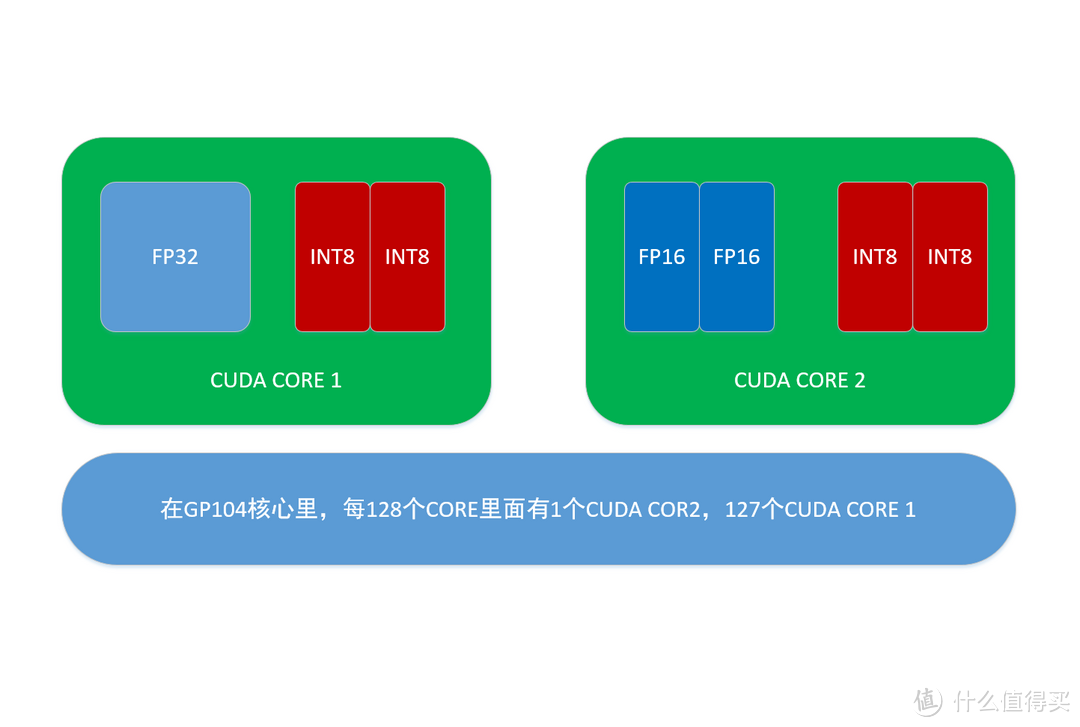
GTX1080的CUDA CORE其实分两种,CORE1和CORE2:
CORE1由一个FP32计算单元和2个INT8的计算单元组成
CORE2由两个FP16计算单元和2个INT8的计算单元组成
FP32单元计算单精度浮点运算。
FP16单元计算半精度浮点运算,也可以两个一起计算FP32的单精度浮点运算。
INT8单元的计算精度等于FP16的一半,FP32的四分之一。
每一个CUDA CORE无论1还是2里都具有2个INT8,所以理论上INT8运算能力是FP32的2倍。
所以运算能力上,INT8:FP32(单精度)=2:1
每128个CUDA CORE里有一个CUDA CORE2具有2个FP16计算单元,这两个FP16计算单元可以合并计算FP32也可以分开计算FP16;剩下的127个CUDA CORE1里面具有127个FP32计算单元。
无论CORE1还是CORE2计算FP32单精度运算的时候,都是一样的。
但是计算FP16半精度运算的时候,只有CORE2有用,
其实MAXWELL就可以1:1的使用FP32模拟运算FP16了,但是GP104的这个FP32模拟FP16被NVIDIA无情的封杀了,可能觉得GP104太强了,习惯性的直接给半精度阉割上了一刀。
所以运算能力上,FP16(半精度):FP32(单精度)=1:64
第二节、GP100构架的TESLA P100

TESLA P100属于PASCAL的GP100架构,但并不是TESLA-PASCAL的完整构架。TESLA P100是以PASCAL架构的首张NVIDIA计算卡的身份出现为GTX1080造势的,但是不可否认在大家为P100的架构震惊的同时,SHUT UP AND TAKE MY MONEY了,但是其实我想说GTX1080和P100真的没啥关系。被P100引诱而去购买GTX1080的同学我只能说你再一次被老黄骗了。

上图为TESLA-PASCAL的完整构架,60组SM单元,TESLA P100只用56组。
GP100包含28组纹理处理器集群(TPC)
每个TPC有2个流处理器组(SM)
每个SM有64个CUDA单元(CUDA CORE)和32个双精度计算单元(DP Unit)
共计3584个CUDA CORE和1792个FP Unit
GP100为了适应高性能计算还大幅增加了缓存及寄存器大小,内置L2缓存从GM200的3072KB增加到了4096KB,每组SM单元的共享寄存器文件大小还是256KB,但总数从6144KB增加到了14336KB,可以以80TB/s的速率传输数据。基准时钟速度为1.3GHz,提升为1.4GHz,TDP为300W。
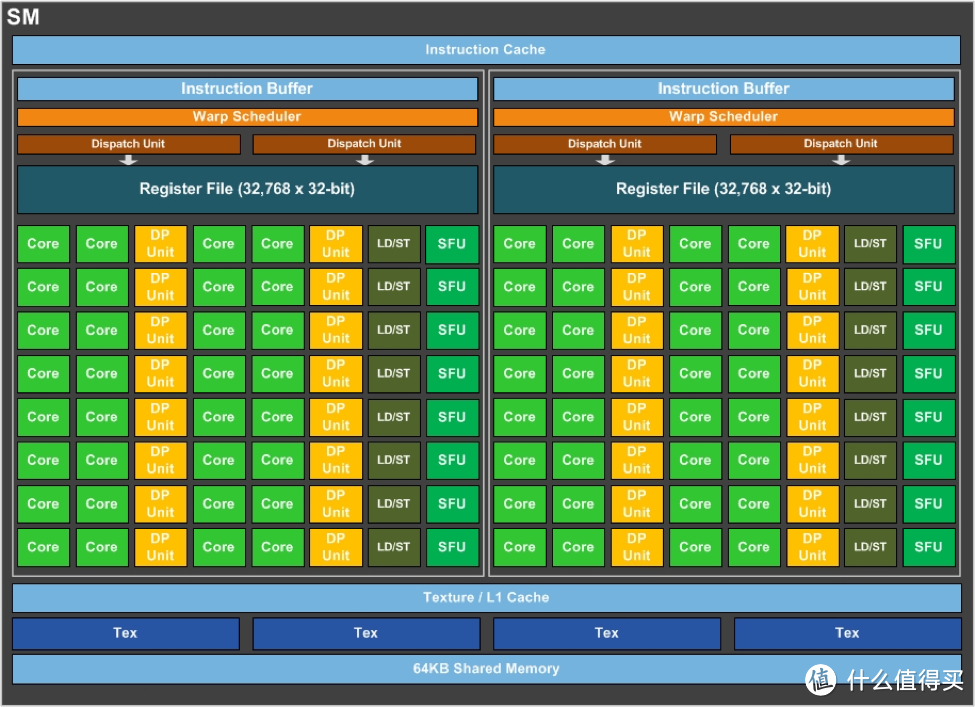
GP100 SM构架图
每组SM单元64个CUDA CORE,还有32个双精度计算单元(DP Unit)
GP100继承了Kepler双精度单元独立式设计。 CUDA 核中的FP unit(浮点单元)具备单精度计算能力,对双精度浮点计算仅开放支持,并不具备实质的双精度浮点能力,必须要在CUDA旁添加双精度浮点单元(DP unit)辅助CUDA核进行双精度浮点计算,才能让CUDA核具备双精度浮点能力。数量众多的DP unit也因此成为计算卡的标志,同时为了降低增加DP unit带来的功耗,Tesla计算卡删去了与计算方面无关的部分。
所以,所以运算能力上,FP64(双精度):FP32(单精度)=32:64=1:2
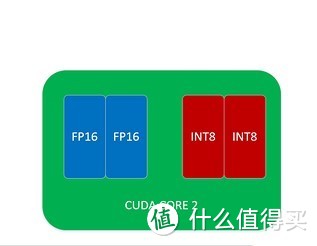
另外,我们前面说过GP104核心的CUDA CORE会有两种,但是GP100的CUDA CORE只有一种,就是双FP16计算单元+双INT8计算单元的组合,所以GP100的CUDA CORE不但具备单精度FP32的浮点运算能力,还具备双倍的半精度FP16的浮点运算能力。
FP32单元计算单精度浮点运算。
FP16单元计算半精度浮点运算,也可以两个一起计算FP32的单精度浮点运算。
所以运算能力上,FP16(半精度):FP32(单精度)=2:1
INT8单元的计算精度等于FP16的一半,FP32的四分之一。
每一个CUDA CORE都具有2个INT8,所以理论上INT8运算能力是FP32的2倍。
所以运算能力上,INT8:FP32(单精度)=2:1
第三节、GM204构架的GTX980

GTX980属于MAXWELL的GM204完整架构。
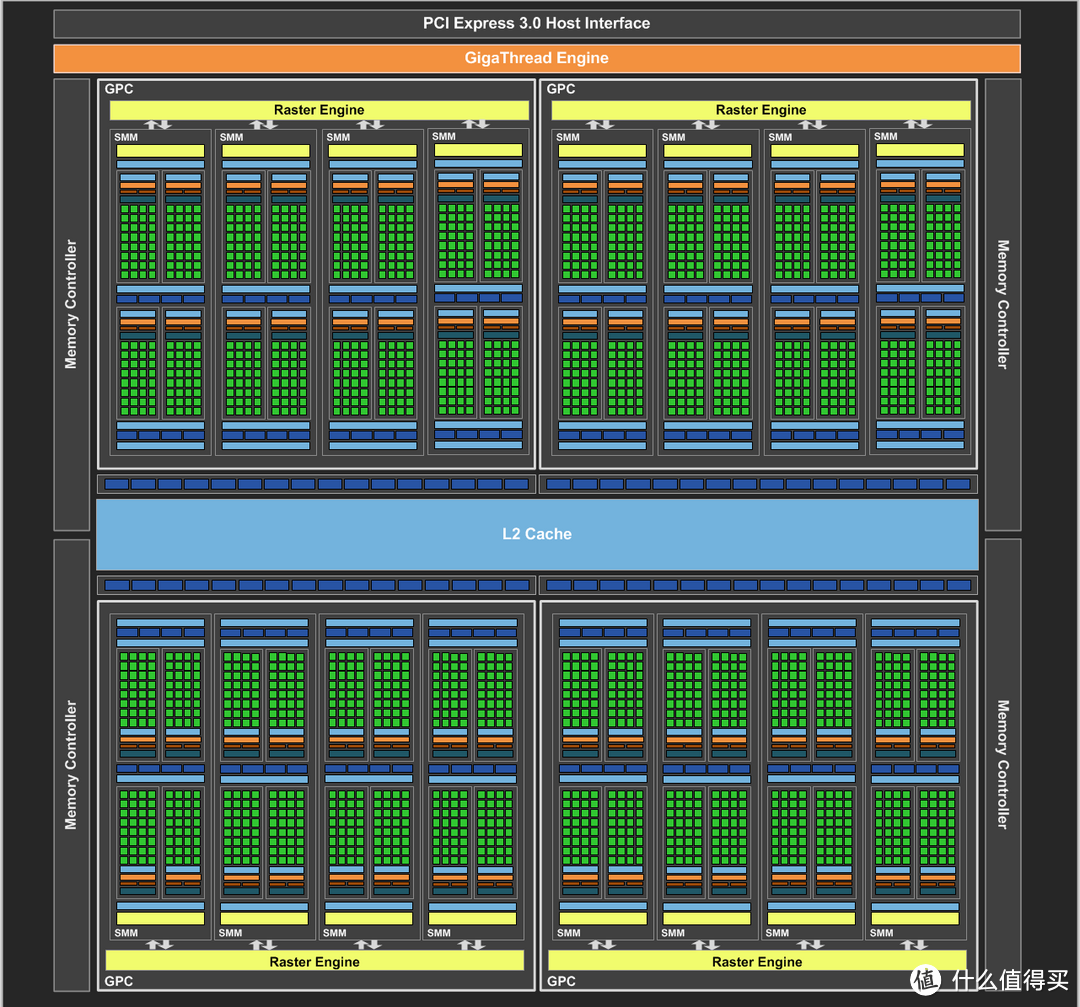
GTX 980核心代号GM204,上图为GM1204的“完整”架构
GM204包含4组显卡处理器集群(GPC)
每个GPC有4个流处理器组(SMM)
每个SM有128个CUDA单元(CUDA CORE)
共计2048个CUDA单元
4组64bit显存控制器,每组连接16个ROP单元和512KB L2缓存。总位宽是256bit,ROP单元64个,L2缓存2048KB。
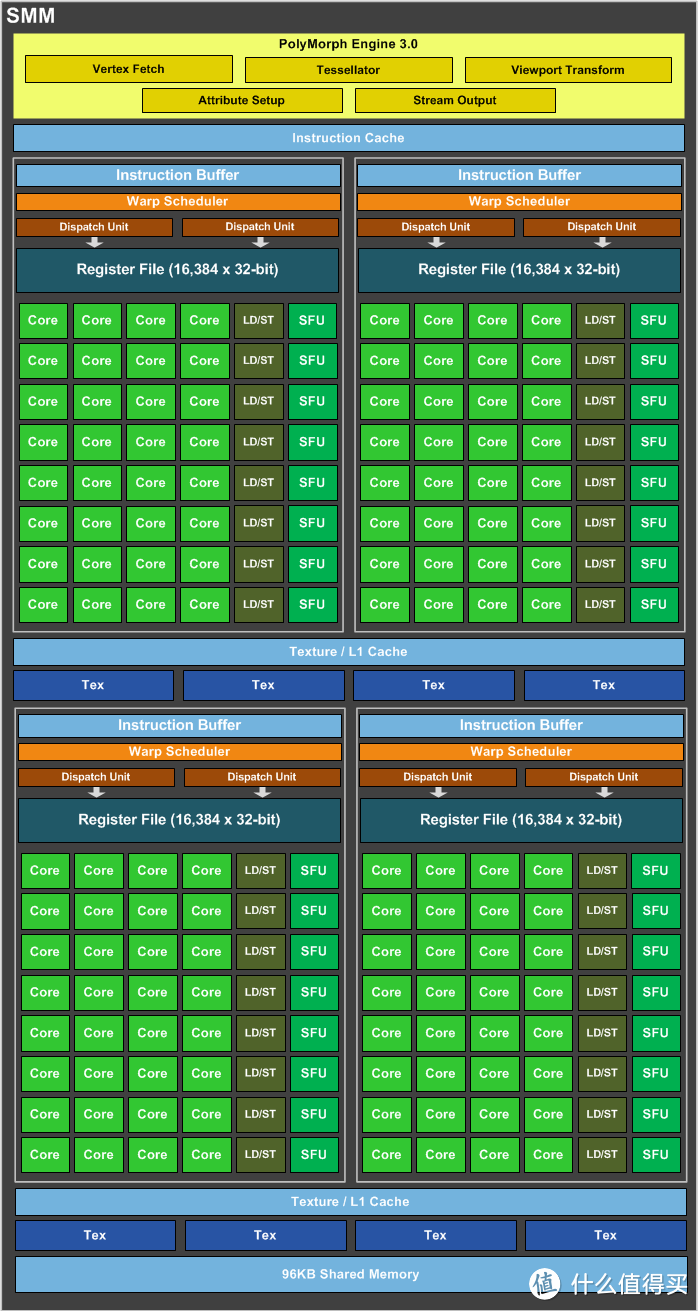
官方的SMM构架图依然丢失了DP Unit的描述。
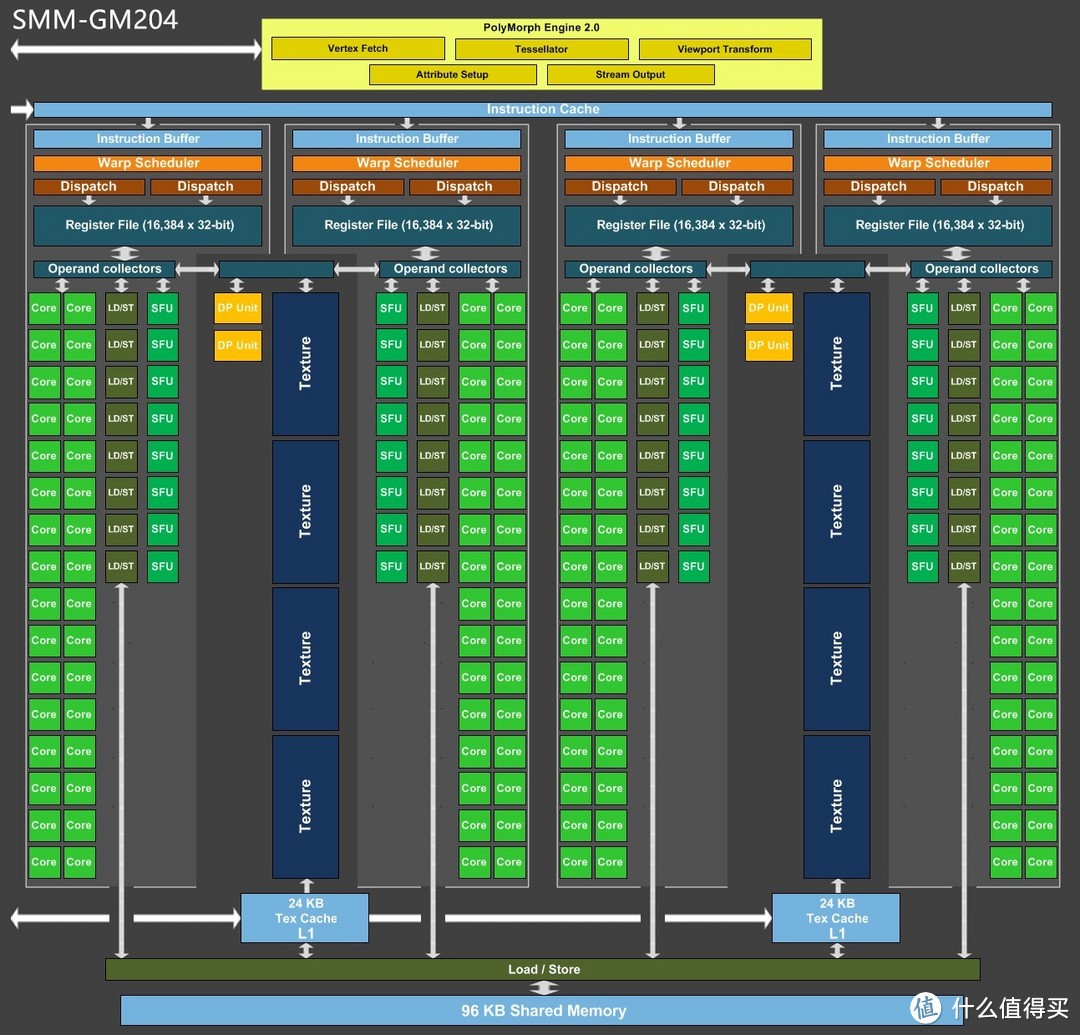
修正后的SMM架构图
在Maxwell中,NVIDIA给每个SMM中添加了4个DP unit,达到128 CUDA:4 DP unit 的单双精度比,且DP单元和CUDA工作在相同频率上,因此Maxwell可以实现1/32 DP运算力。
所以,所以运算能力上,FP64(双精度):FP32(单精度)=1:32
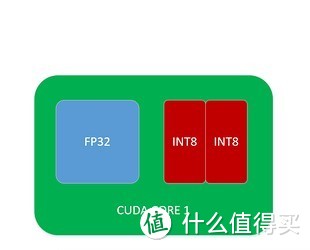
前面说过GP104核心的CUDA CORE会有两种,GM204的CUDA CORE只有一种,就是FP32计算单元+双INT8计算单元的组合,但是GM206的CUDA CORE不但具备单精度FP32的浮点运算能力,还具备相同的的模拟半精度FP16的浮点运算能力。
所以运算能力上,FP16(半精度):FP32(单精度)=1:1
INT8单元的计算精度等于FP16的一半,FP32的四分之一。
每一个CUDA CORE都具有2个INT8,所以理论上INT8运算能力是FP32的2倍。
所以运算能力上,INT8:FP32(单精度)=2:1
第四节、架构对比
可以看出即使同为PASCAL架构的GP100和GP104,完全是两个不同的架构方向,GP100更类似于Kepler架构,拿掉了一切和计算无关的东西,而GP104更类似于MAXWELL架构,拿掉了一切和游戏无关的东西,这一点从架构图中可以看出。所以GP100和GP104其实没多大的传承关系,你可以认为他们是不同的架构。
GP104和GM204的架构是非常类似的:
1、GP104的SM单元和GM204的SMM单元是极其类似的架构。
2、GPC包含的SM单元来说,GP104是5个,GM204是4个。
3、GP104有两种CUDA CORE,一种含有FP32计算单元,一种含有2个FP16计算单元,而GM204只有前者。
4、GM204的FP32单精度计算单元可以模拟半精度FP16的运算,但是GP104这个功能屏蔽了或者说以后看情况考虑开放驱动支持。
5、GP104是TSMC 16nm FinFET+工艺制造,GM204是TSMC 28nm HPM工艺制造。从漏电率来说GP104好很多,所以无论是相同功耗下所可以达到的主频还是相同性能下所需要的功耗以及发热量来说,GP104都具备压倒性的优势。
当然GP104相对GM204而言还有一些小的不同点和技术升级的,但是大部分是相同的,所以要一句话简单总结GP104和MAXWELL的关系就是:16nm FinFET+工艺制造的MAXWELL VR升级版。
当然GP104相比GM204除了物理架构细微区别之外还有一些技术实现上的区别:
1、支持指令级别的多任务抢占。
假设GPU正在渲染多边形模型,或者执行大数据计算,GM204只能在当前着色程序完全执行完成之后才能进行任务切换,而GP104可以在着色程序执行三分之一的时候暂停让车,GPU计算资源会自动分配给具有更高优先级的任务。
2、VR渲染的均匀采样
GP104有两项技术:快速几何着色器和多视口投影,使用这两项技术GP104可以实现VR渲染的均匀采样,以往的VR渲染之中,每个单位角度的像素密度非常接近,而GP104达到的效果是离透镜中心越远采样密度越高,这个小改动让VR渲染在不影响结果正确性的前提下节约接近一半的像素计算。
第四章、TSMC 16nm FinFET +

FinFET( Fin Field-Effect Transistor , 鳍式场效电晶体)是新型的多重闸道3D电晶体,是曾任台积电技术长的柏克莱电机系教授胡正明所发明。 FinFET是源自于目前传统标准的晶体管—场效晶体管(Field-effecttransistor;FET)的一项创新设计。

按照TSMC的PPT爆料,16NM FinFET比28nm HPM工艺的产品,相同功耗性能提升38%,相同性能节能54%。
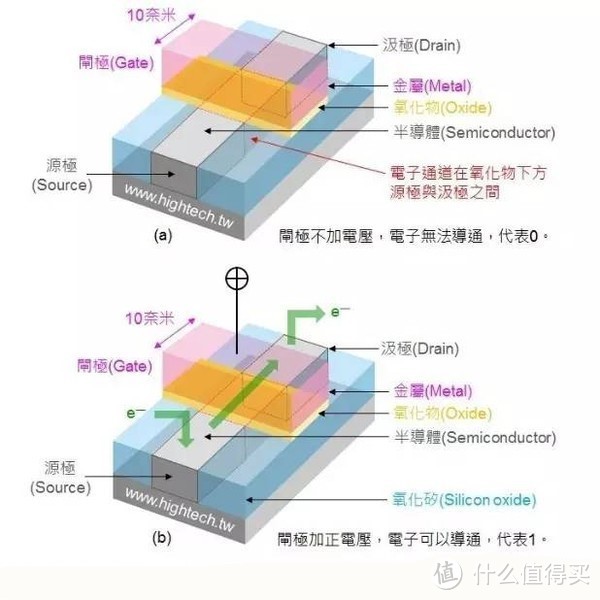
在传统晶体管结构中,控制电流通过的闸门,只能在闸门的一侧控制电路的接通与断开,属于平面的架构。
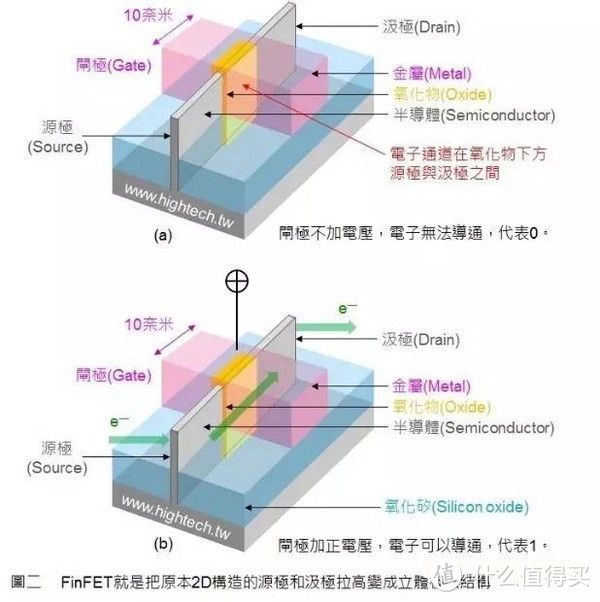
在FinFET的架构中,闸门成类似鱼鳍的叉状3D架构,可于电路的两侧控制电路的接通与断开。 这种设计可以大幅改善电路控制并减少漏电流(leakage),也可以大幅缩短晶体管的闸长。
GP104使用的台积电新工艺16nm FinFET+,内部命名CLN16FF+,沿用20nm工艺的后端互连架构,并加入FinFET立体晶体管技术,这种设计可以大幅改善电路控制并减少漏电率,也可以大幅缩短晶体管的闸长,减少漏电率的同时提高了性能降低了功耗。
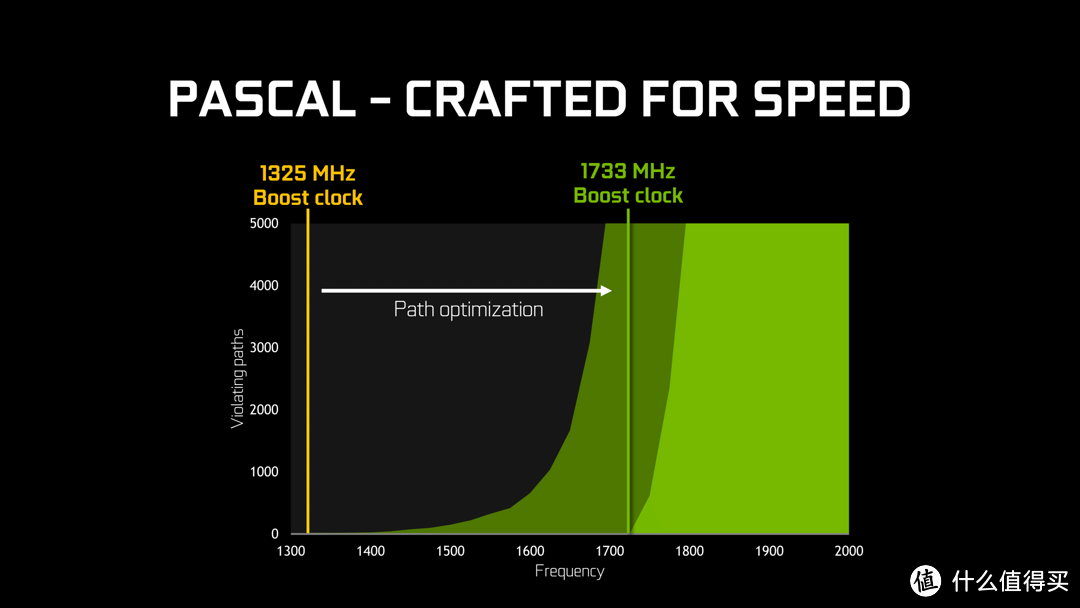
上一代MAXWELL最高的BOOST频率也才1325MHz,这一代PASCAL GTX1080核心主频就高达1607MHz,通过BOOST 3.0直接拉到1733MHz,性能提升幅度如此巨大,源于TSMC 16nm FinFET+制程对漏电率的控制做到了很高的水平,这才是NV敢把GTX1080频率拉到这么高的主要原因。
第五章、GPU BOOST 3.0
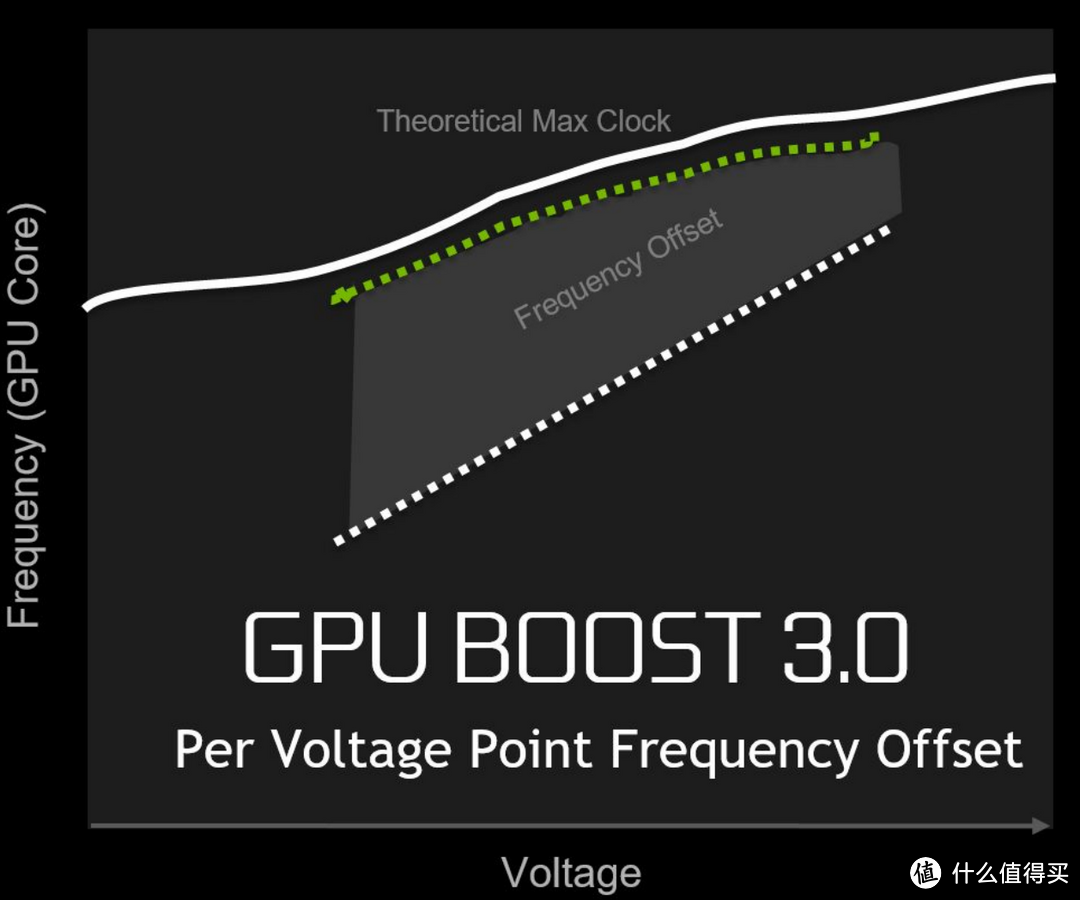
GPU Boost可以根据负载和温度自动调整GPU频率和电压。
GPU Boost 1.0加速技术,影响频率提升的主要因素就是显卡TDP功耗,GPU会根据显卡当前的状态来管理频率加速状态。
GPU Boost 2.0技术,考虑的因素不光是功耗,还有显卡的温度,也就是说GPU加速频率要照顾到功耗及温度两方面,不会为了性能而让温度超标,这样可以不仅可以提高性能,也不会导致温度失控进而导致风扇转速飙升,带来额外的噪音。
无论GPU Boost 1.0还是GPU Boost 2.0,GPU频率增加的步进都是固定的,大约是13MHz一个GPU Offset,而在GTX 1080显卡上,NVIDIA又带来了GPU Boost 3.0技术,它的一个关键改变就是Offset频率不再固定,每个电压点都有对应的频率Offset,这样做的一个好处就是GPU实际加速频率可以更接近理论值,只要温度允许,频率可以往上跳一个较大幅度,随着温度升高,再慢慢降低频率。这样可以充分利用GPU的功率空间。
第六章、GDDR5X

GDDR5X一些特性大家都度娘很多次了,我想这里可以说的更简单一些就是:
GDDR5 1.25GHz下可以达到的数据吞吐量是5Gb/s
GDDR5X 1.25GHz下可以达到的数据吞吐量是10Gb/s
这就是最简单的差别。
第七章、测试
第一节、测试平台装机SHOW

主板:超微C7Z170

CPU:INTEL I7 6700K

内存:英睿达DDR4 2666 8GBX2


SSD:金士顿UV400 240GBX2

电源:酷冷至尊V850

首先搭建好平台,散热是酷冷至尊T400S
对比测试显卡采用上一代的GM204核心的同定位产品GTX980

平台装入机箱

装载好SSD


装好GTX1080显卡


装载ASUS PCE-AC88 WIFI网卡




主机四面观


连续装上2层机箱面板


光污染特效

显示器使用4K 32寸专业级AOC LV323HUPX





内置DP1.2版本和HDMI2.0版本均支持4K 60HZ刷新率输出
第二节、基准测试
1、基础信息
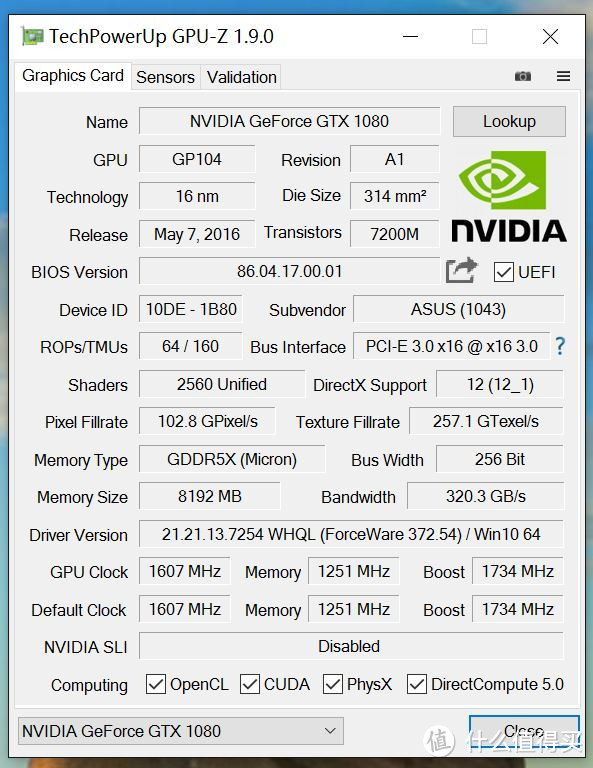
驱动版本372.54,操作系统WIN10 X64专业版,
基本信息:
GeForceGTX1080拥有2560个CUDA处理器,核心频率1607MHz,boost频率1733MHz,拥有8GBGDDR5X显存,等效显存频率10GHz。显卡位宽为256bit,带宽320GB/s。采用单8pin供电,TDP180w,单精度浮点运算运算能力是9Teraflops。
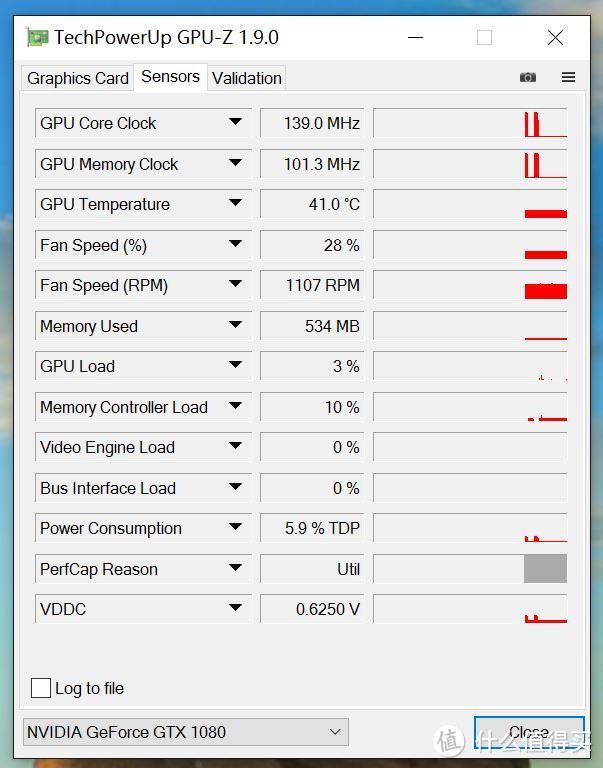
待机温度41度,
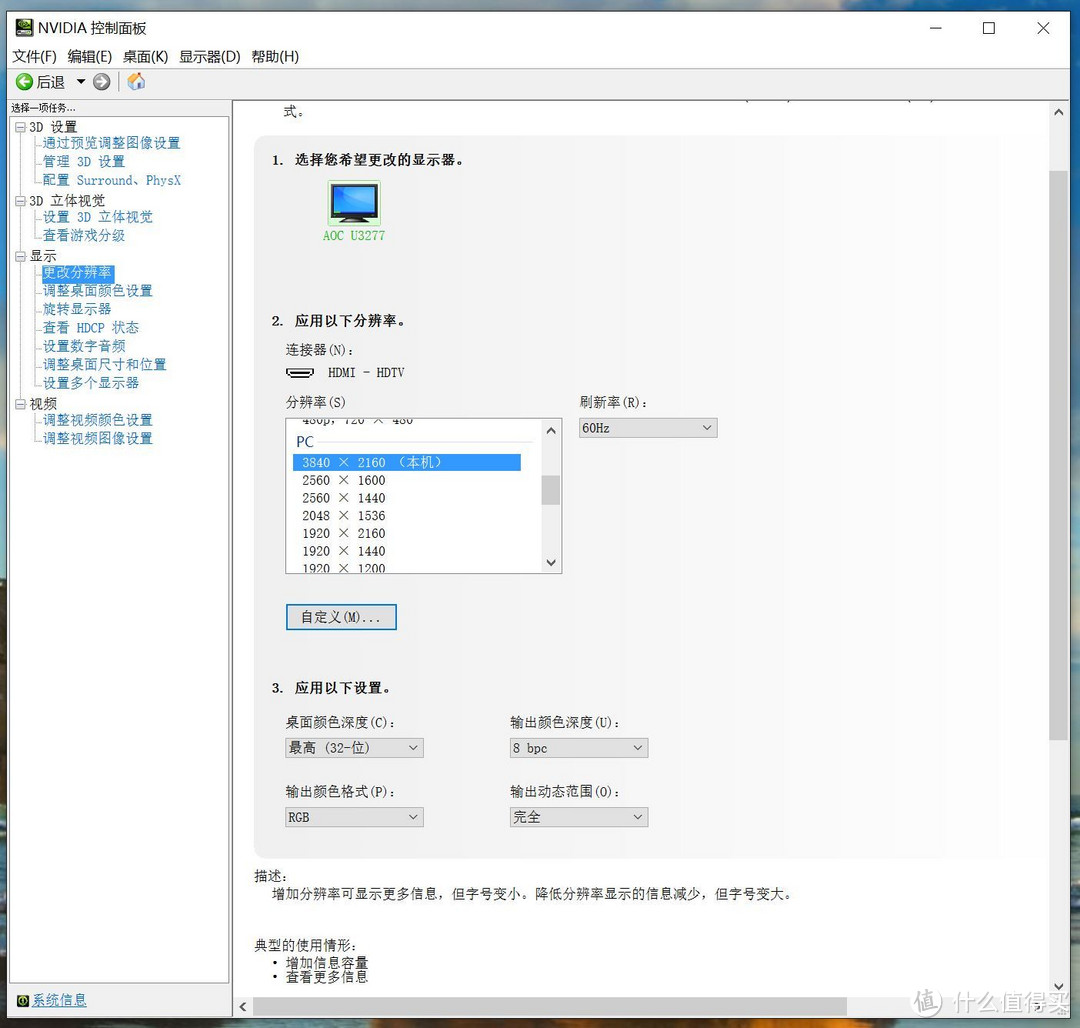
HDMI2.0完美支持4K 60HZ
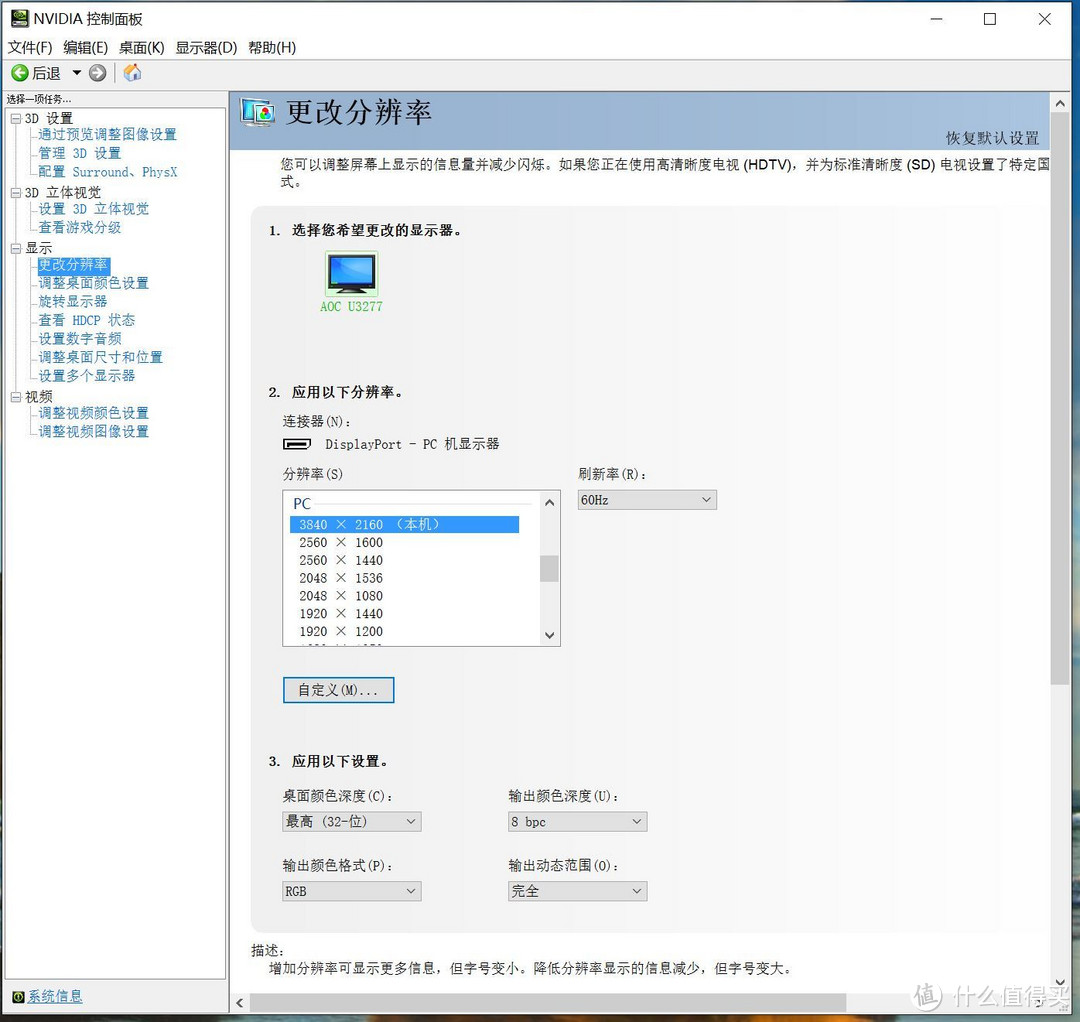
DP1.2完美支持4K 60HZ
2、解码支持
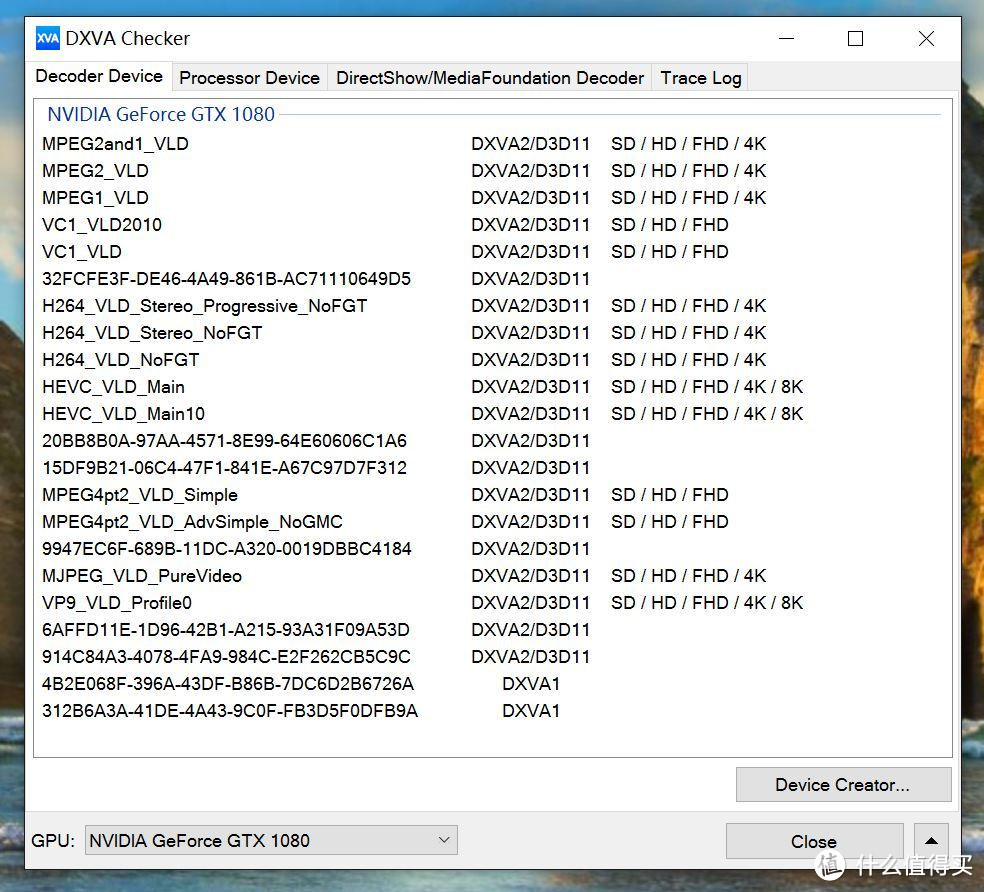
最新的DXVA CHECKER显示GTX1080已经支持8K视频硬解,不过也正常对于一张8K分辨率支持的显卡来说,不支持8K高清解码就太搞笑了。
下面测试8K高清能力,测试视频为[TIMESTORM.8K.视频] 挪威NORWAY 8K VP9,测试软件为K-Lite Mega Codec Pack 12.3.0
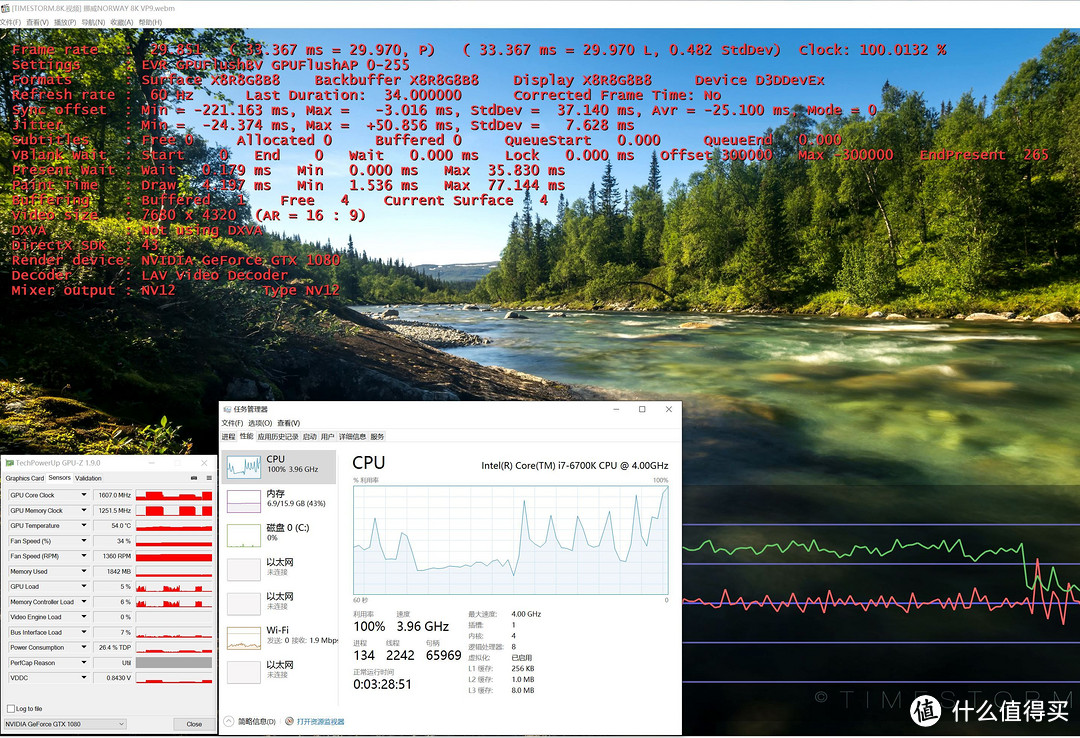
关闭DXVA硬件加速,负载:CPU100%,GPU6%,基本流畅略有卡顿
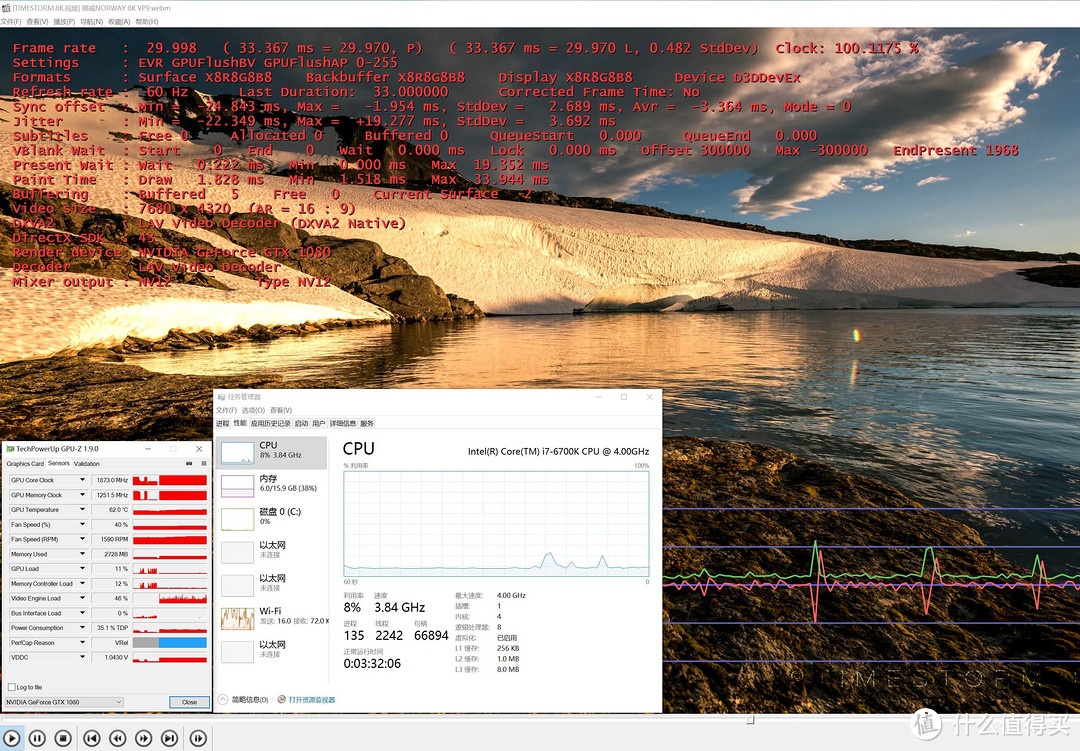
开启DXVA硬件加速,负载:CPU 8%,GP U11%,流畅无卡顿。
3、3DMARK

3DMark根据设备的不同等级而分成三种不同的测试场景:Ice Storm针对移动设备,或者性能入门的电脑;Cloud Gate针对笔记本电脑和家用平台;而Fire Strike则针对高性能平台。
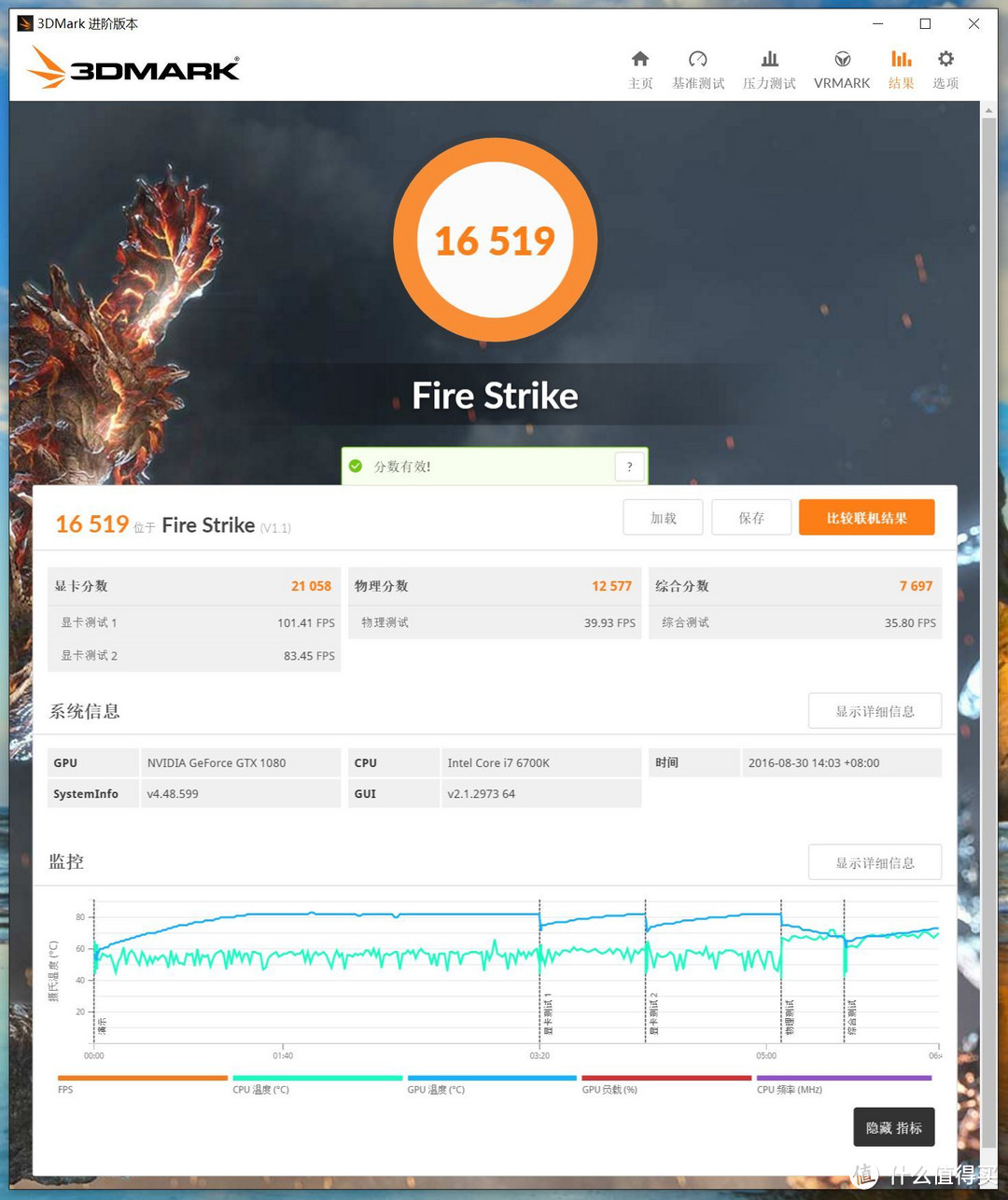
Fire Strike是测试专用游戏电脑和高端计算机组件性能。Fire Strike使用限制为Direct3D 11级的DirectX 11引擎,适用于检测DirectX 11的硬件,分辨率是1920x1080。Fire Strike场景完全支持DX11,专为高性能游戏PC打造,是有史以来最复杂、技术最丰富的测试场景,画面渲染细节度远远超过了其它任何基准测试工具。
3DMARK FIRE STRIKE:16519
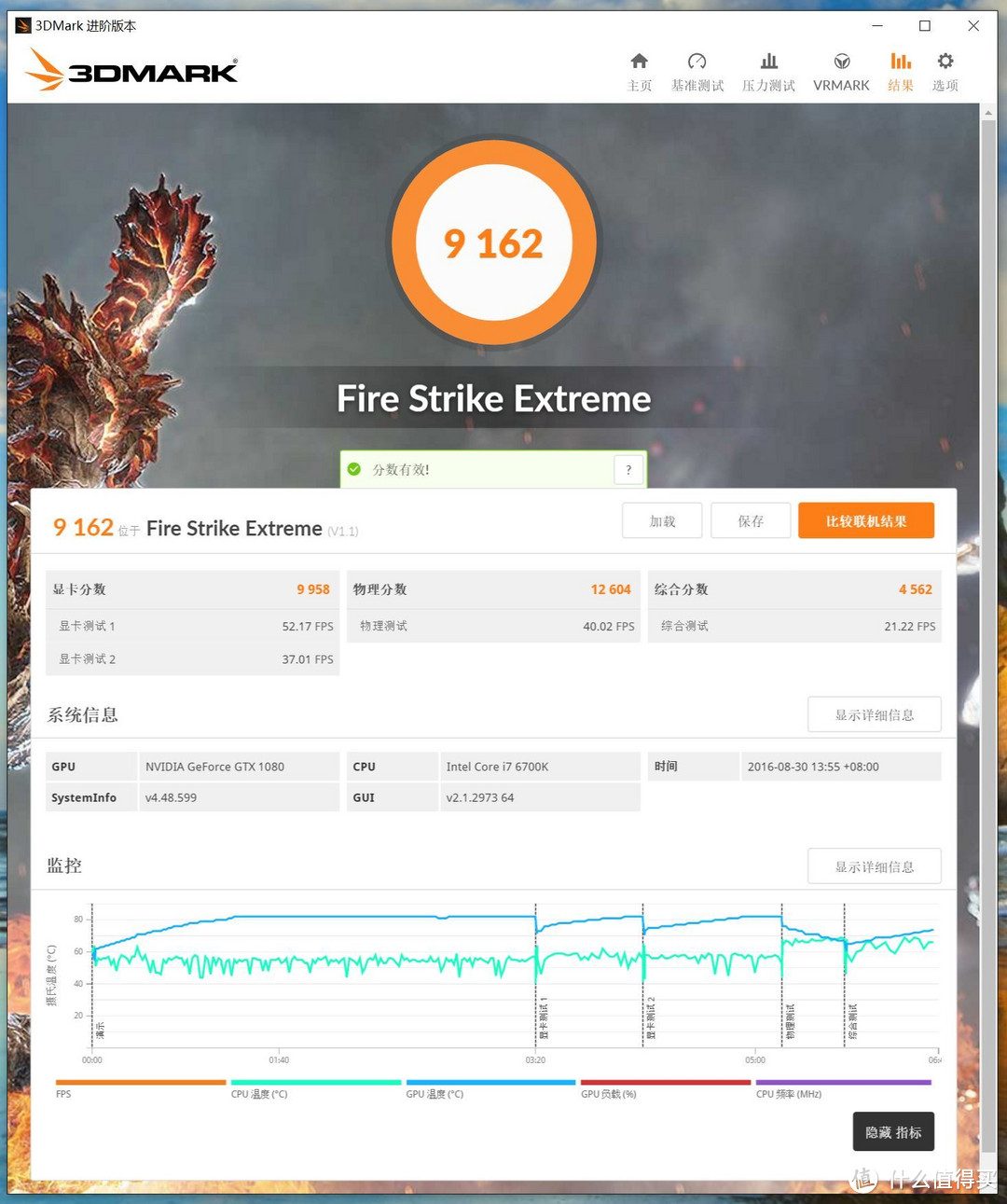
Fire Strike EXTREME使用限制为Direct3D 11级的DirectX 11引擎,适用于检测DirectX 11的硬件,分辨率是2560x1440。
3DMARK FIRE STRIKE EXTREME:9162
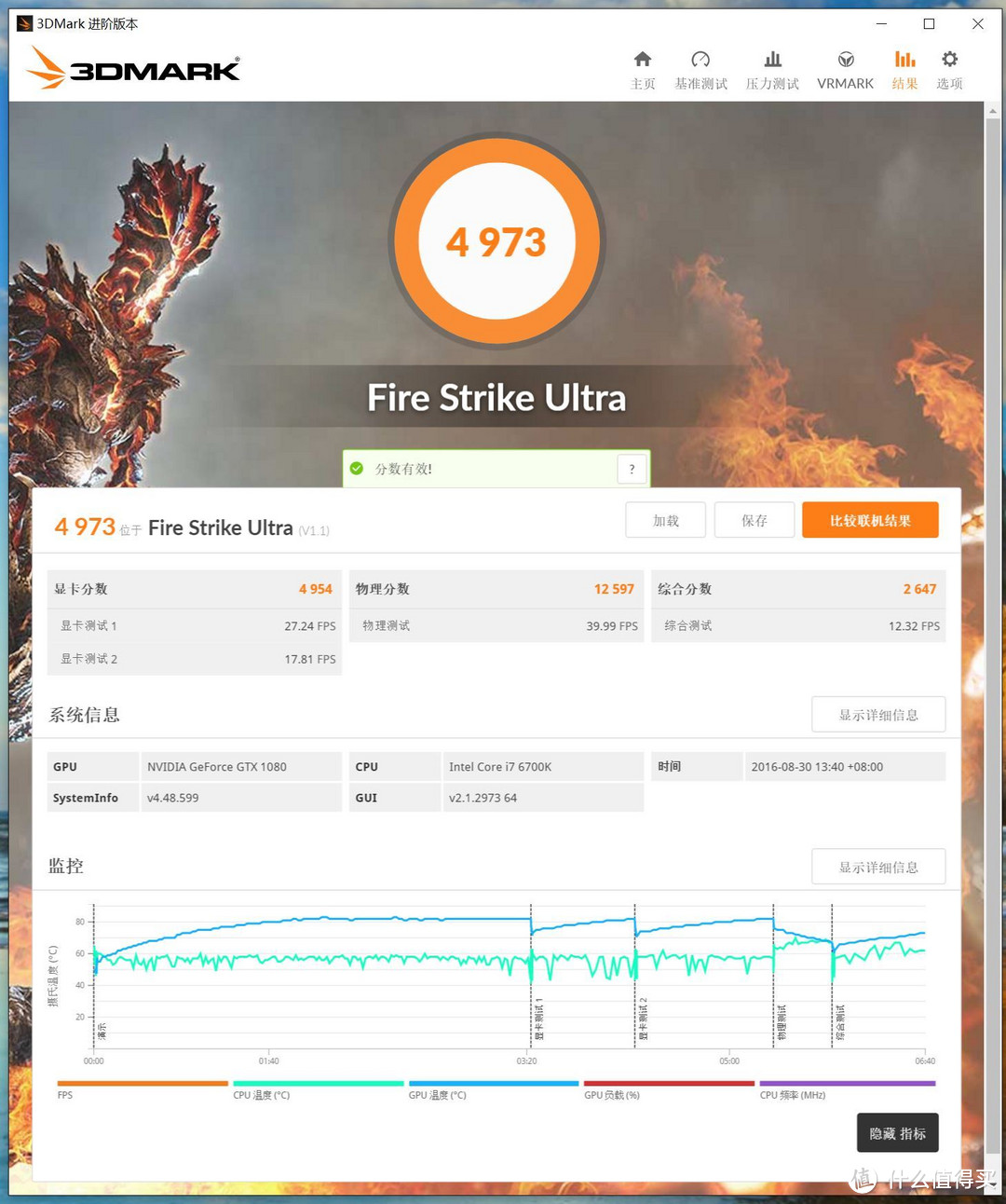
FIRE STRIKE ULTRA使用限制为Direct3D 11级的DirectX 11引擎,适用于检测DirectX 11的硬件,分辨率是3840X2160,是首个面向4K分辨率的基准测试。
3DMARK FIRE STRIKE ULTRA:198
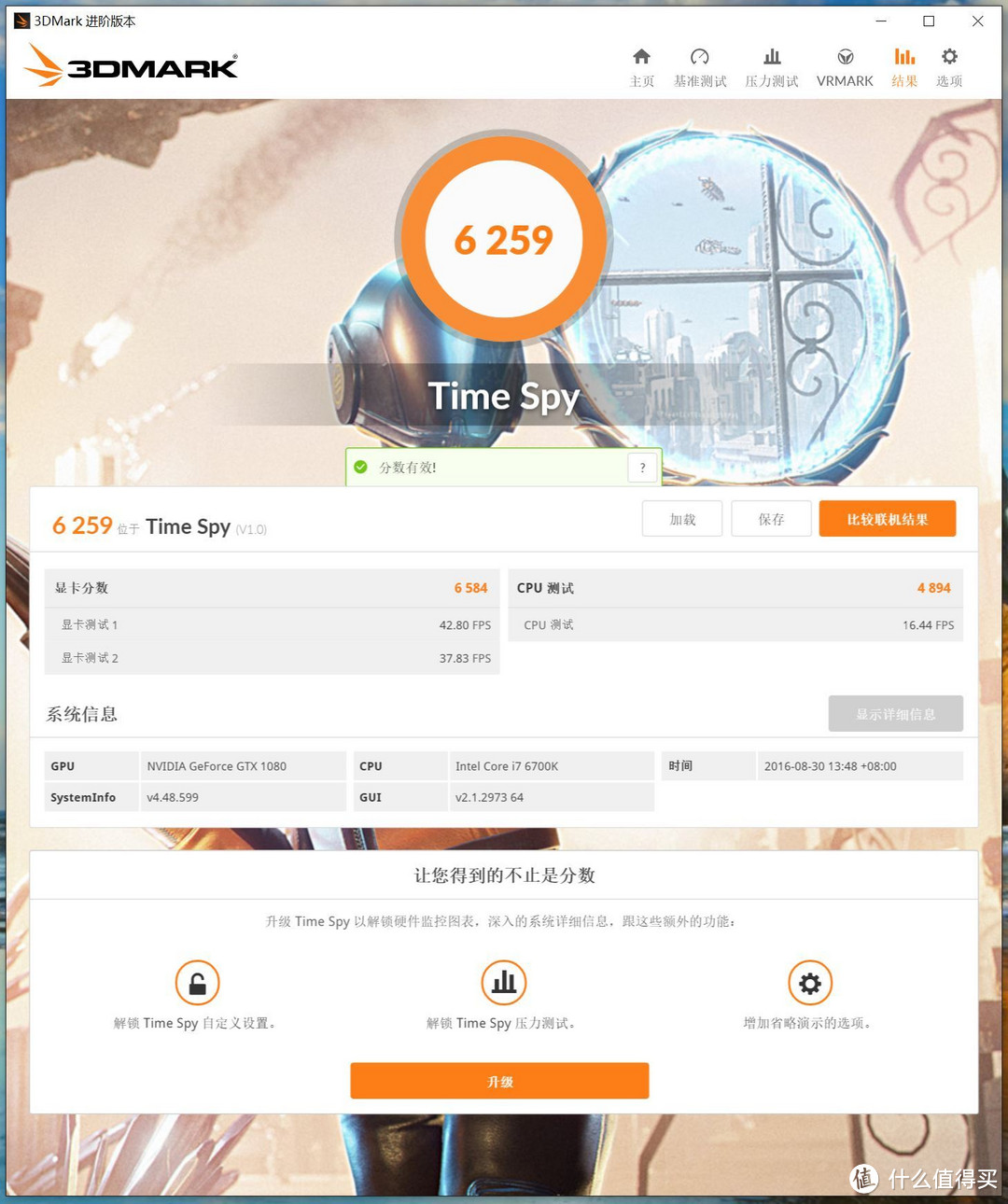
2016年7月15日,3DMark开发商Furmark正式推出了全新的测试组件:Time Spy。
Time Spy,充分融入了DX12的相关革新技术,严格考核显卡和CPU的DX12性能。一座太空博物馆内无数藏品,每个场景都有丰富的细节和阴影,堪称是目前画面最为复杂的性能测试场景。,图形测试渲染分辨率为2560X1440。
3DMARK Time Spy:6259
3DMARK整体测试的结果说明GTX1080是一张能流畅运行4K大型游戏的显示卡。
4、烤机测试

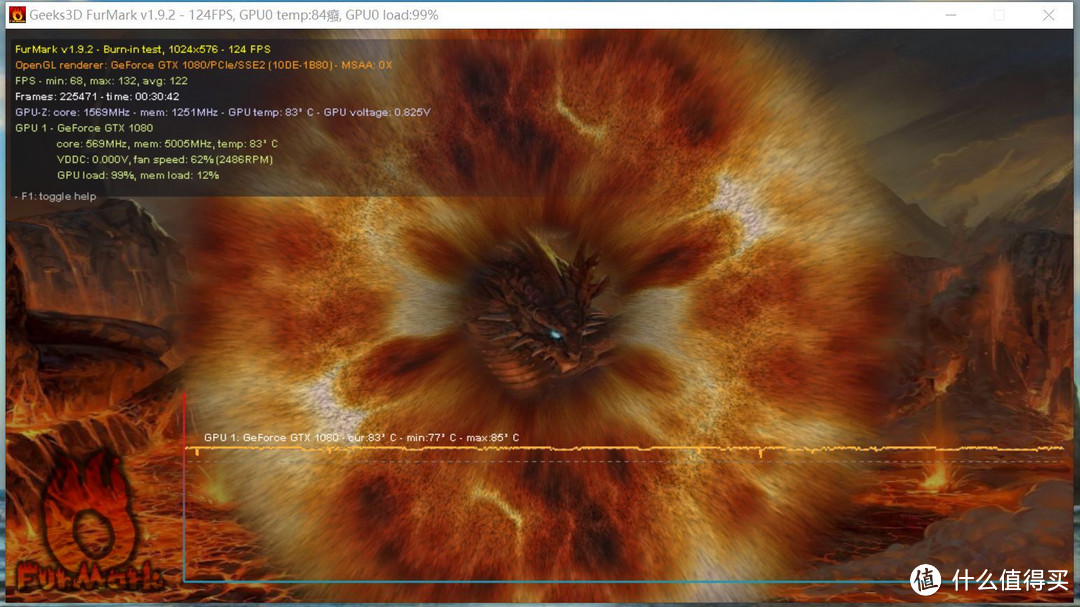
软件使用FURMARK满载烤机30分钟,平均温度83度。风扇一直在62% 2486转,完全没有噪音。
5、VR STREAM测试

在VR测试部分使用SteamVR Performance Test进行测试,该程序可以全面检测用户的PC性能,考验PC是否能够支持VR设备稳定流畅运行。


SteamVR效能测试会透过一段2分钟由Valve制作的《光圈科技机械人维修VR展示》来评估玩家电脑的渲染力。
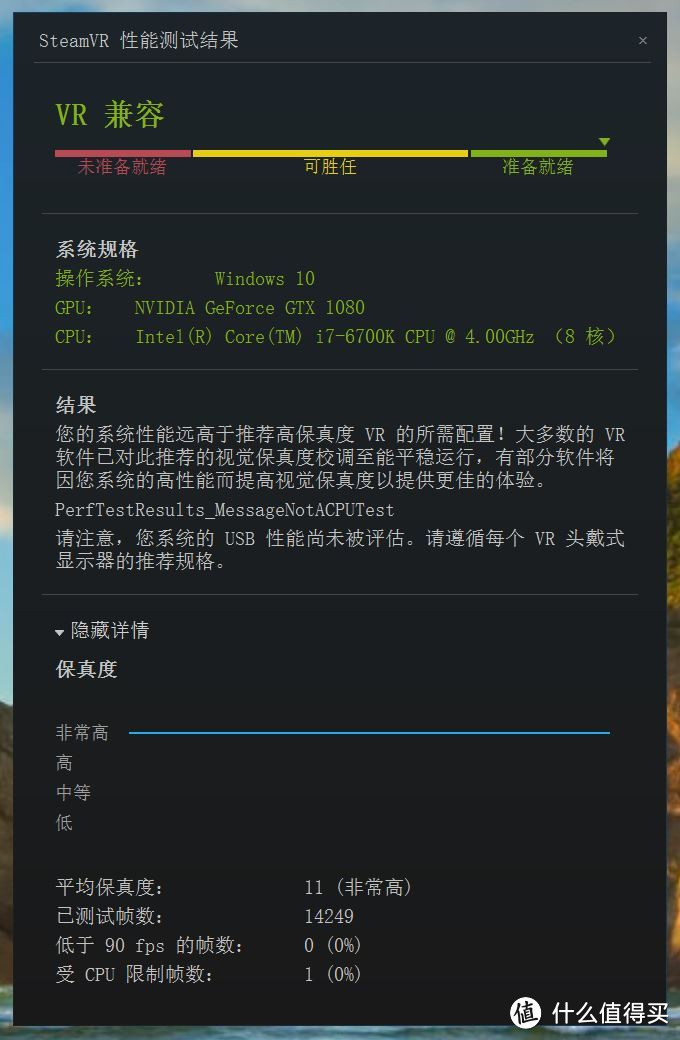
在收集相关数据后,它将判断玩家所使用的系统能否维持在90fps的帧率运作以及VR内容的视觉保真能否够校调至建议的水平标准。GTX1080显示保真度非常高,14249帧每一帧均高于90fps,而且完全是一条直线没有任何波动,系统给出的评价是远高于推荐高保真VR的配置。
Pascal可以同时进行VR渲染的左右眼投影,这个和以往的多视口投影有本质不同,因为左右眼的投影矩阵不同。结果就是场景几何体只需要在顶点着色器里处理一遍,而不是以往的两遍。在几何量是瓶颈的时候,性能可以大幅提升。
6、CINEBENCH R15

CineBench R15 64BIT加强了着色器、抗锯齿、阴影、灯光以及反射模糊等的考察,使用针对电影电视行业开发的Cinema 4D特效软件引擎,可以测试显卡的OpenGL性能。
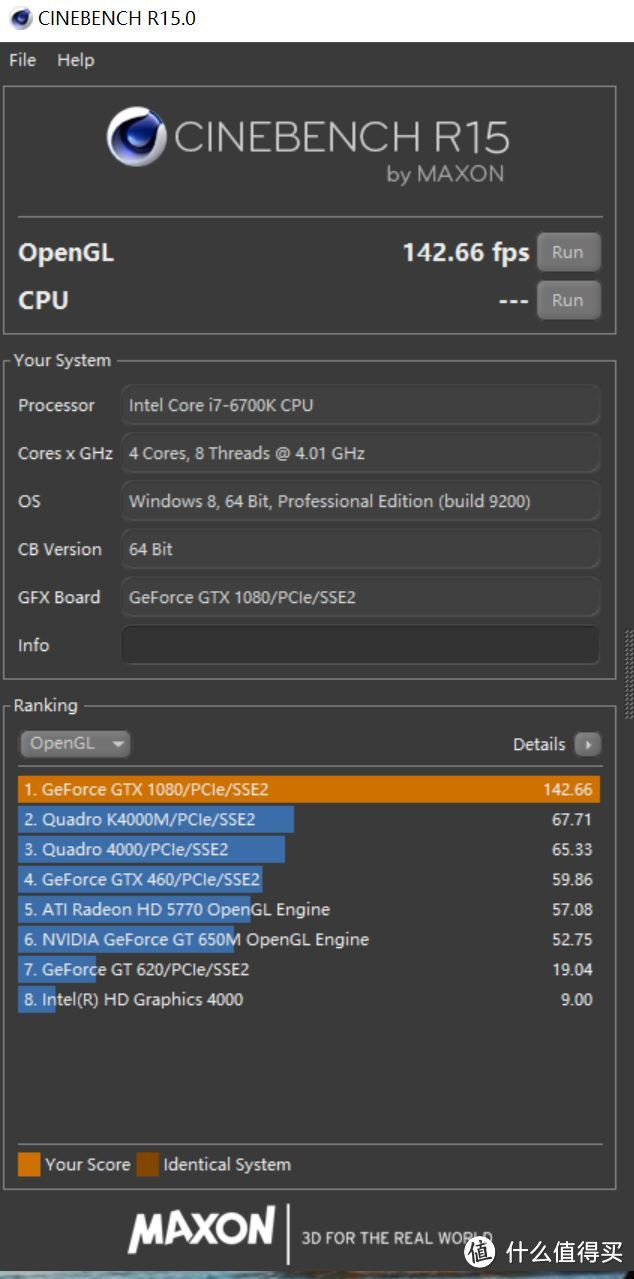
GTX1080的成绩142.66cb,已经超越了专业显卡QUADRO K4000M的OPENCL性能的双倍有余。
6、AIDA64 GPGPU通用计算测试

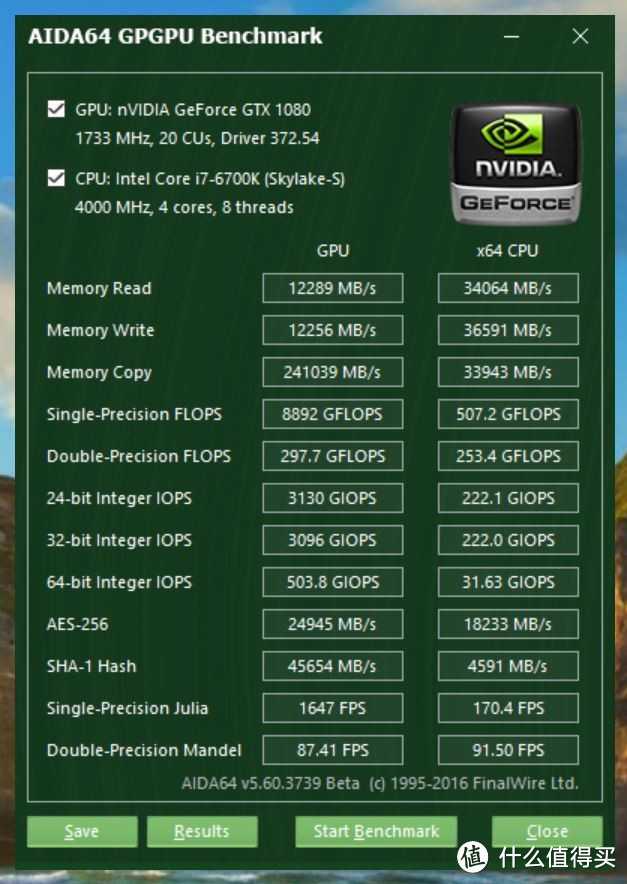
AIDA64 GPGPU套件是OpenCL GPGPU基准测试套件,考察显卡的通用计算能力,并且可以计算单精度和双经典浮点运算能力,已经INT24、INT32、INT64的计算效能。
7、显卡杀手级游戏测试

巫师3:狂猎
巫师3:狂猎是一款得到公认的DX11下的显卡杀手级游戏,让你痛苦让你忧,画质纠结党的噩梦。
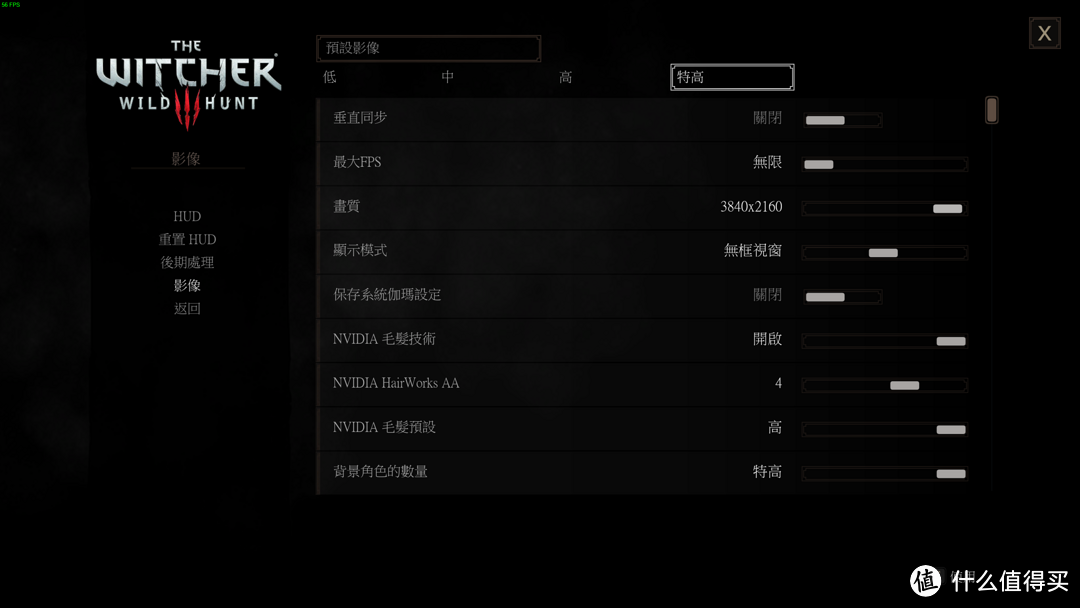
4K分辨率下,特高画质设置,特效全开
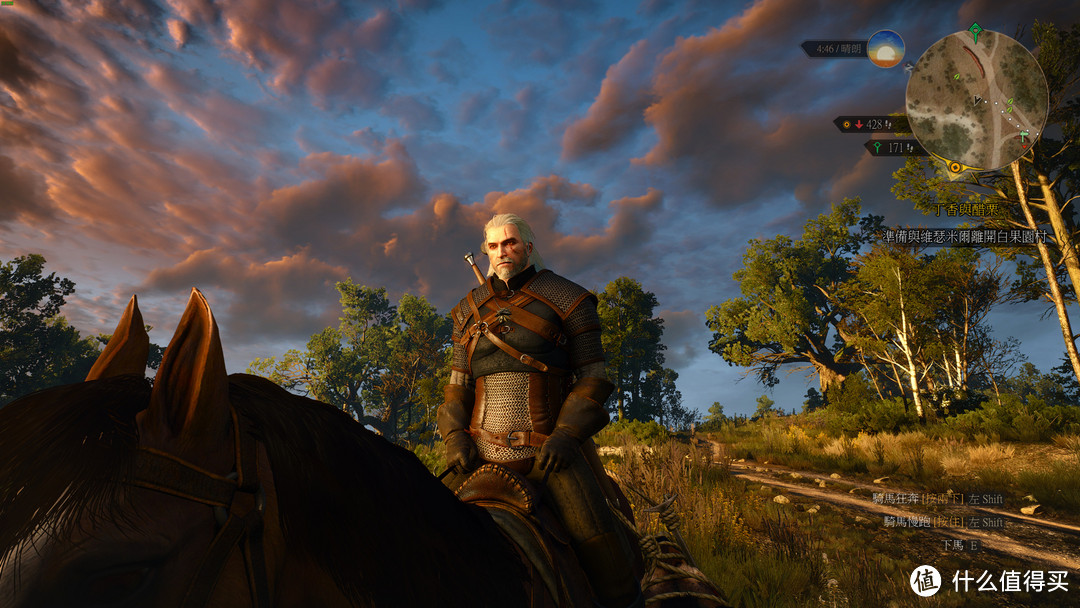
在人物的移动和跑动中大约平均在35帧左右,REDengine 3引擎搭配Gameworks、Hair Works以及HBAO+等技术是明显的NV控的显卡杀手级游戏,GTX1080渲染后的游戏细节真是绝美。

奇点灰烬
首款DX12显卡杀手的游戏
DX12版本
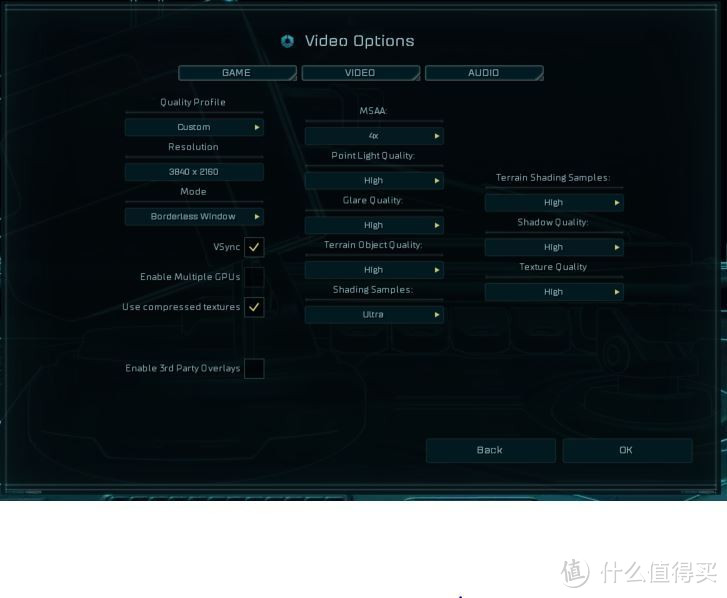 设置为4K最高画质运行自带BENCHMARK
设置为4K最高画质运行自带BENCHMARK




作为首款DX12显卡杀手的游戏来说,这画面太震撼不敢看。
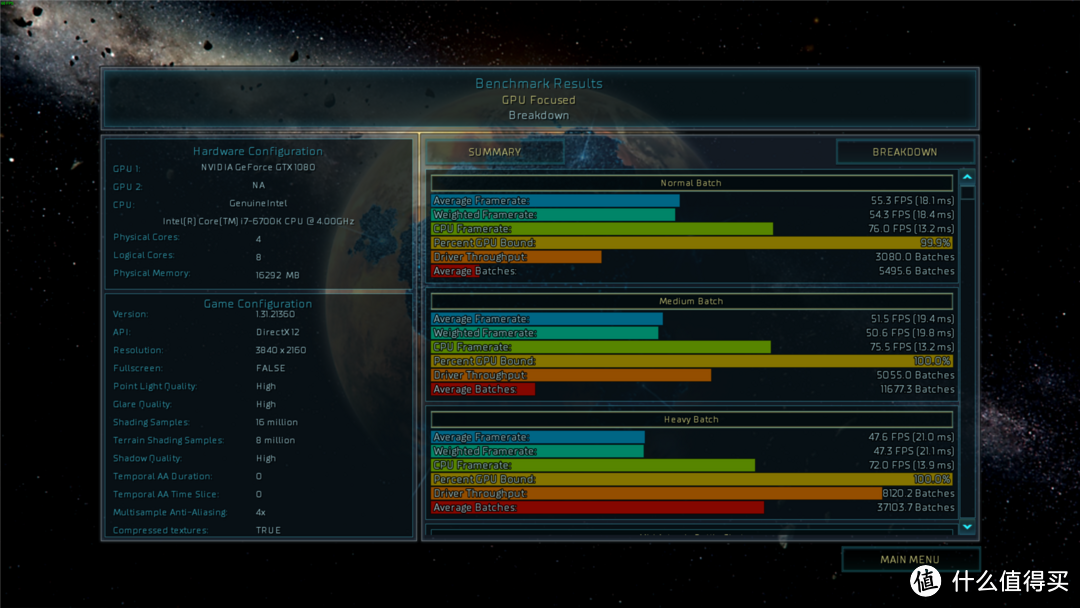
重度画面模型比较多的情况下的测试结果,47.6帧。
GTA5

经常朋友说:要判断自己的硬件配置是否需要更新换代你应该去试着跑一跑《GTA5》的“全画质全帧数”模式(特效全开之下将某项数字调到60)。我都是用这句话来作为游戏性能评估的标杆的。
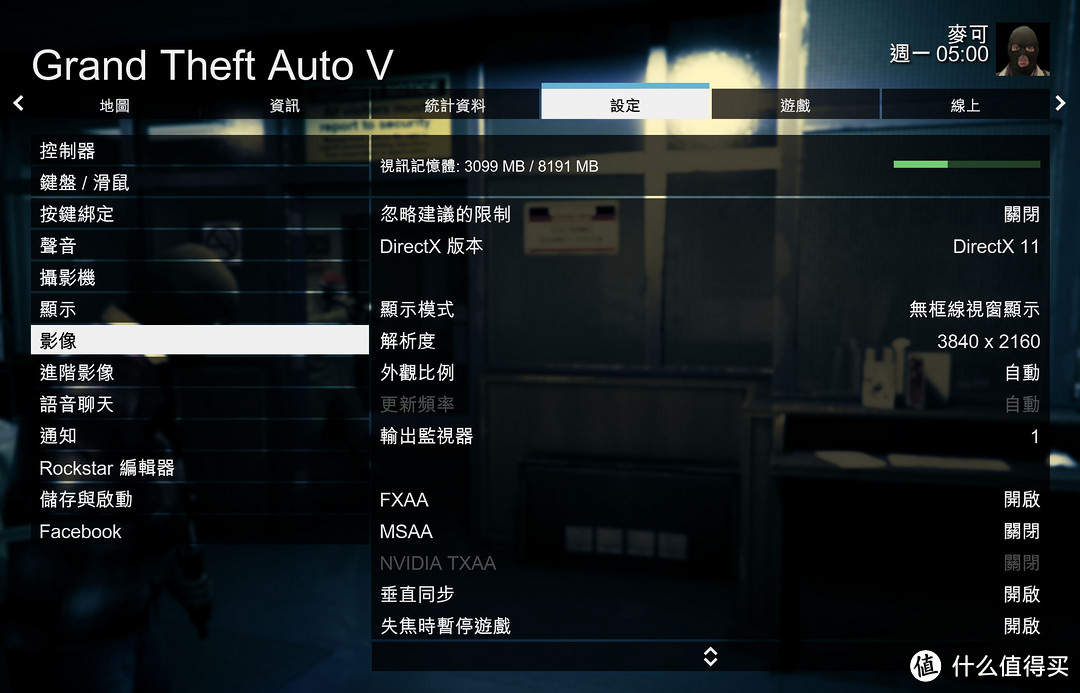
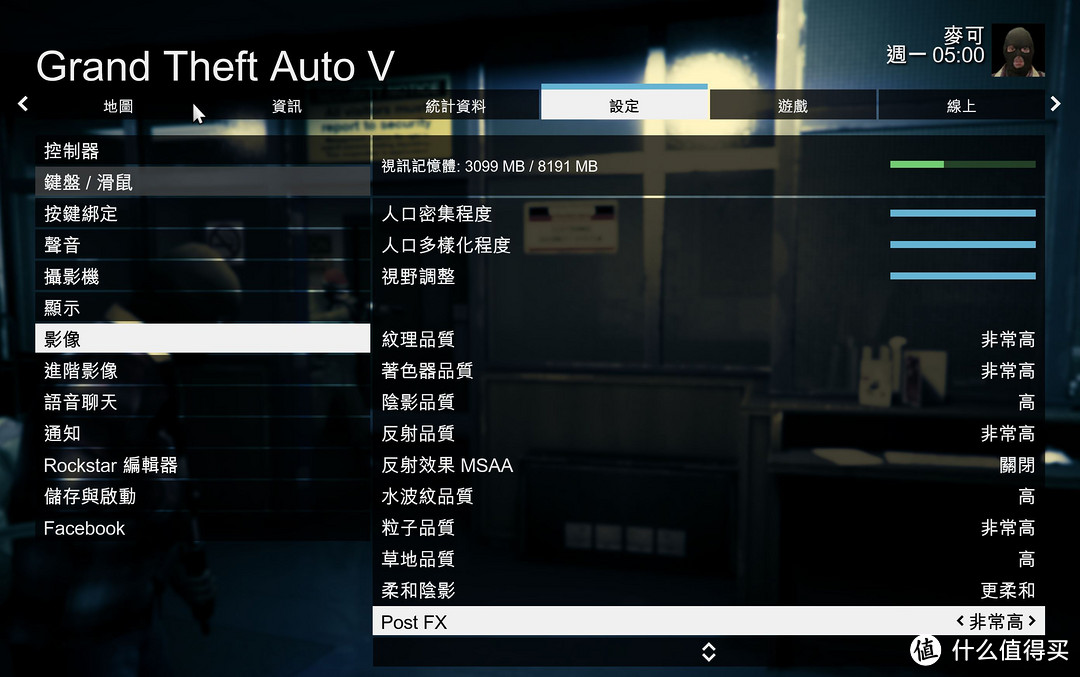
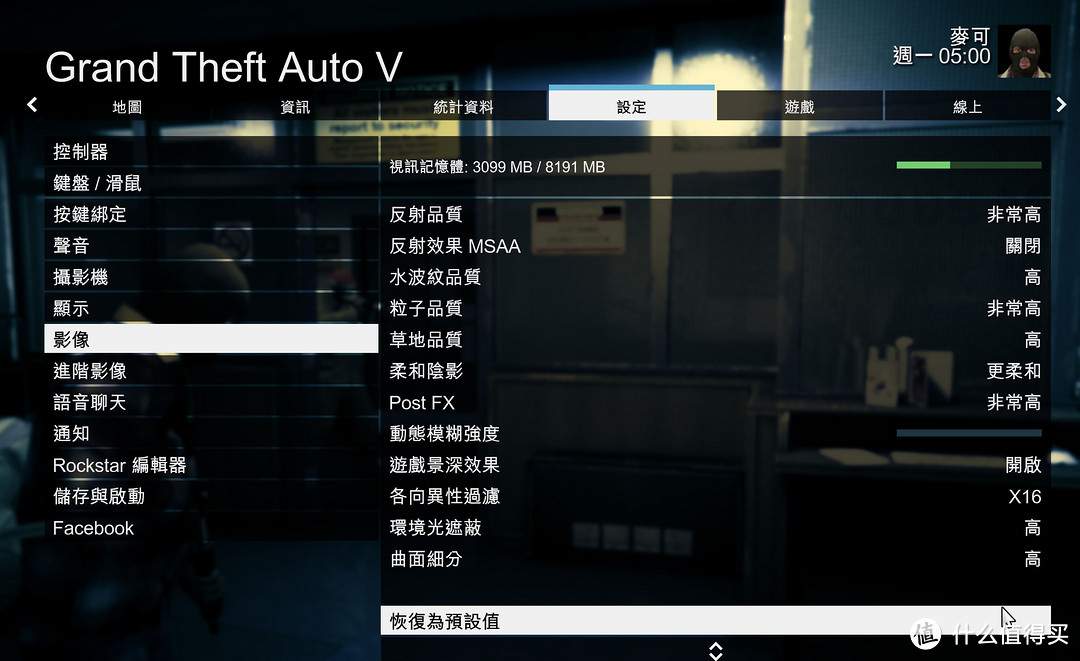
4K分辨率不开启AA和进阶影像的情况下

随便跑都有50帧以上,平均帧数在56
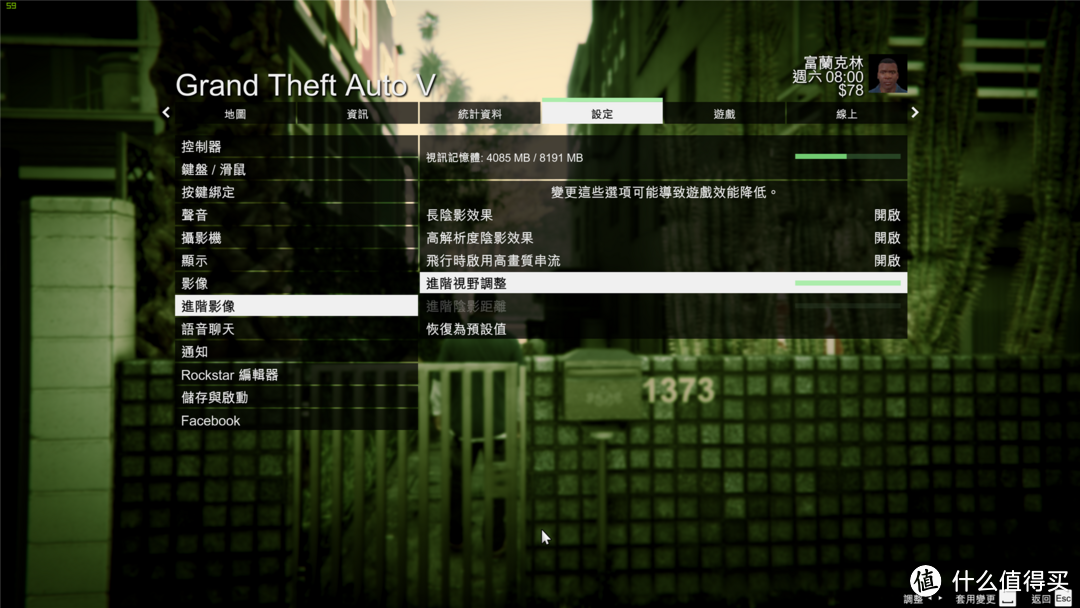
开启进阶影像最高之后
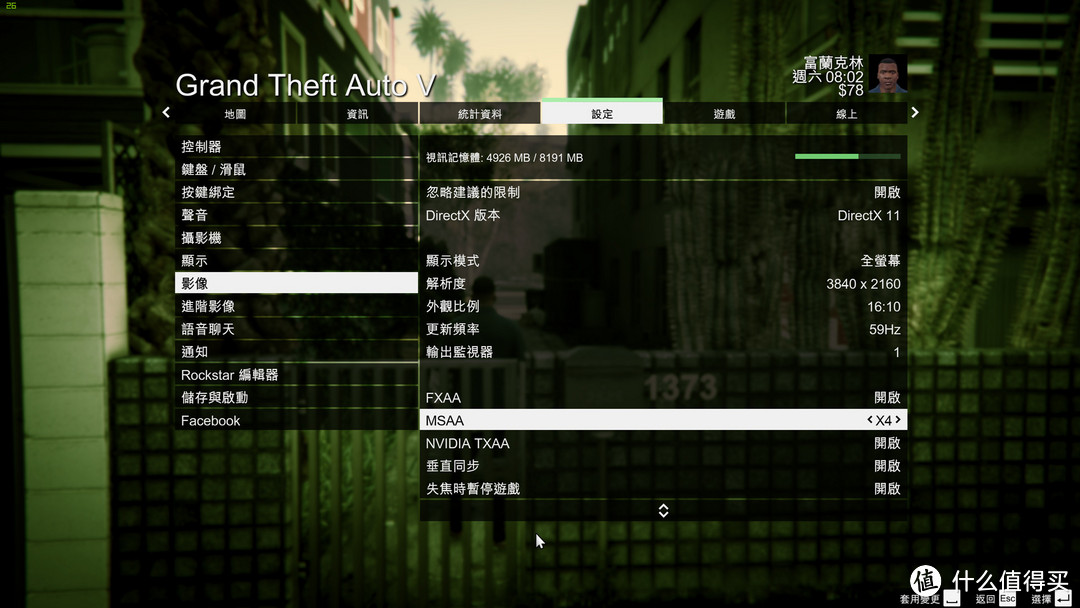
继续开启全屏60HZ刷新率,MSAA开启X4,NVIDIA TXAA开启。其余保持不变

马上FPS掉在40,平均FPS在37


这个游戏即使4K到顶的画质的解析力仍属一般,但是游戏可玩性确实强大。

古墓丽影 崛起
《古墓丽影:崛起》已支持DX12,成为继《杀手6》之后另外一款支持DX12的3A大作,由于一开始是根据DX11开发的因此并不能有效利用DX12的新特性,所以DX12表现的帧数会明显低于DX11的。
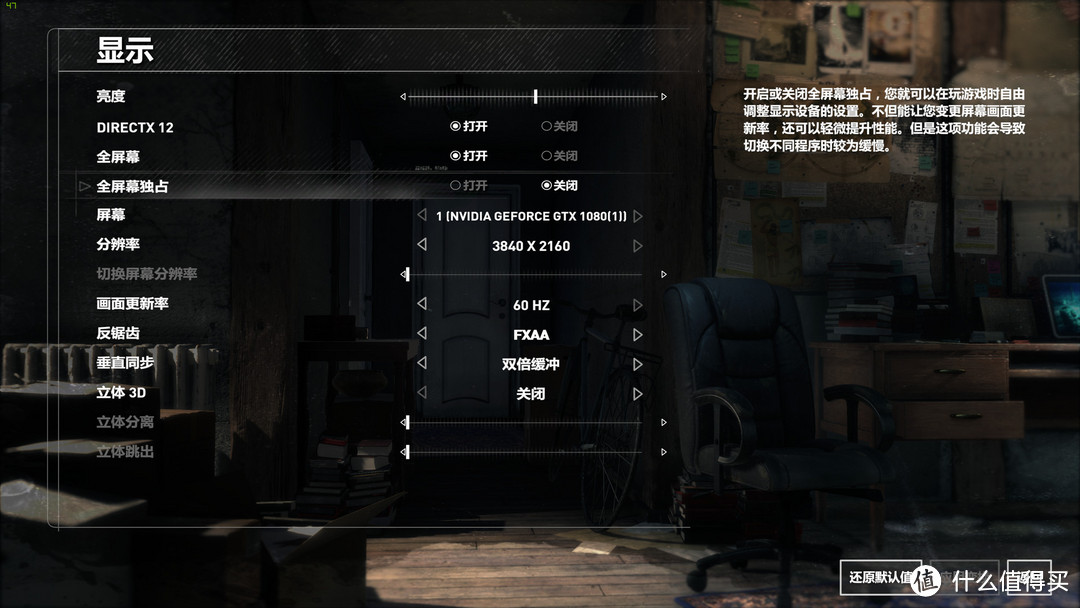
我使用DX12进行测试

全部4K最高画质,进行BENCHMARK测试

BENCHMARK测试第一关是山顶,

第二关是叙利亚

第三关是丛林

得到的整体分数即平均的FPS在44.60。
第八章、杂谈公版
我对显卡有着严重的公版情节,无论A卡N卡,我在选卡的时候都会尽量选择公版卡。
公版显卡:公版显卡就是设计与生产完全按照显卡芯片厂商(NVIDIA、AMD)提供的板卡PCB、散热设计方案的显卡。
非公版的显卡:PCB设计与公版显卡方案不一致,不采用官方建议设计的显卡,注意,所有对公版设计方案稍作改动的显卡依然属于非公版显卡。非公版显卡还要细分为普通版、超频版、缩水版(阉割版),顾名思义,非公版显卡对比规格质量一致的公版显卡具有有好有坏特性。
----来自伟大的度娘
我的看法和度娘的区别在于:
我认为公版显卡是一个完整的工业设计品,包括电路,PCB,IC,芯片,显存,散热都经过原常实验室的考量和测试后发布的用于解释GPU特性的一个SAMPLE。
那么为什么会有非公版的产生?
1、非公缩水版
因为CUT DOWN会产生巨大的利润,节约成本,面对市场巨大的竞争压力,只有阉割才能有效降低成本。
2、非公普通版和高频版
其实我们见到市场大部分的显卡都是普通版或者高频版非公版,华硕的鹰骑士、微星的GAMING、HIS的ICEQ都是此类产品,这类非公版的设计目的不是为了阉割,而是因为各大厂的生产线的存在是需要一些方案去唯度的,比如说,HIS的ICEQ或者MSI的GAMING显卡方案,这个系列的PCB和IC包括散热器的配套采购是固定下来的,供货商签订了长期供货的合同,那么这个产品系列的所有生产供给都是完善的,不会因为缺IC或者PCB而供不上货,只要下单,即可快速生产成型。
但是公版卡不是这样,每一个版本的公版卡都不会提前告知下游厂家,我准备用哪些IC我准备设计哪种规格的PCB,我定制了哪一款散热器,比如GTX980和GTX1080公版,区别就很大,从散热器到物料区别也很大,假如哪一家厂商试图去生产公版的GTX980,那么他再去生产公版的GTX1080的时候,生产线就得重新布局,采购物料得重新签订供给合同,从显卡的发布时效占领市场布局造成的损失到其中过度耗费的人力物力都是巨大的,对于显卡厂商来说得不偿失,一般都是显卡的核心既定下来之后,下游厂家就开始针对自己系列产品的设计了,这样能保证最高的发布时效性和最快的生产效率,生产线小幅改动下,物料不变或者微调即可大批量量产显卡。
但是非公普通版和高频版能否达到公版显卡的稳定性呢?看怎么解读这个问题
1、如果你只是随便玩玩游戏,非公版显卡也许更适合配色,外观更绚丽,风扇更静音,频率也许还略高于公版显卡。那么确实区别不大的。
2、如果你要做一些专业性用途,CUDA计算应用类任务,半精度单精度双精度浮点运算这类,公版显卡的稳定性和兼容性就显露出来了。
3、运行稳定性:设计理念不同,公版卡的设计不止是针对民用游戏市场,同时公版卡设计也兼顾到了专业卡市场比如FIRL GL、QUADRO、TESLA等专业显卡市场,所以他们原厂的产品设计是同时兼顾到各方面需求的而且通过内部LAB的严格测试,你会看到一个散热器和PCB原型基本几乎用完对应的GEFORCE、QUADRO、TESLA三条生产线,而且确保最大的安全可靠。
总结:
我的评测还很浅薄还有很多技术方面的没有涉及,但是就短期的使用对GTX1080有了很直观的感受:
1、GTX1080确实在核心和显存频率上大幅提升了,前所唯有的在两代产品之间实现最大的提升幅度。
2、GTX1080的3DMARK稳定性测试我测了2次都是95%无法通过,过高频率的提升在一定程度上是否会造成稳定性的下降,这个仍未可知。
3、GTX1080的发热量和噪音控制的相当的出色,看不见的改进,让这块显卡在满载下也就83度而已,而且风扇转速才62%不超过2500转,几乎没有噪音。
4、单8PIN 180W的TDP功耗降低了GTX1080的周边配套硬件环境的成本,几乎任何一台具有350w-400W电源的台式电脑只要购买此款显卡都可以方便的安装和正常使用。
5、就单精度浮点运算这点而言,GTX1080 1070系列无疑是性价比最高的产品。
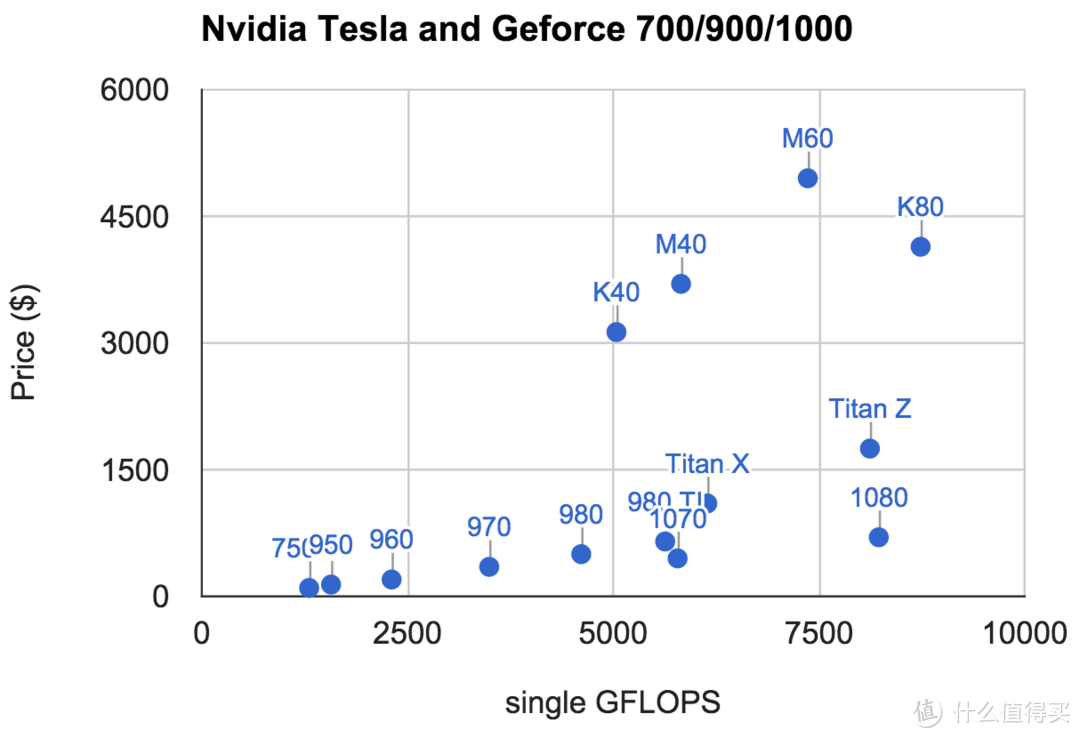
从单精度浮点运算的能耗比而言,GTX的1080的能耗比胜过GTX1070而且是几乎最好的选择。
1/32的双精度浮点运算和MAXWELL的GM204相同,1/64的半精度浮点运算就如同帕斯卡的一个笑话一样存在,人为的驱动限制硬生生的阉割,不过可以理解,因为GP104为了达到最高的频率必须放弃一些游戏不太涉及到的运算,这样保证高频下的稳定性。
本文商品由什么值得买提供,并邀请用户撰写评测报告。更多新奇好物请关注众测活动~

















Darkhucx
校验提示文案
tomx2h
校验提示文案
青春的良民
校验提示文案
pc4649
校验提示文案
LiamX
校验提示文案
浩渺星尘
校验提示文案
阿兔奔奔
这年头一言不合就晒这么多,我是彻底放弃众测晒单的想法了。
校验提示文案
rsdyz1234
校验提示文案
左搂右抱
校验提示文案
qwased
校验提示文案
杲子
校验提示文案
oxxxo
因为CUT DOWN会产生巨大的利润,节约成本,面对市场巨大的竞争压力,只有阉割才能有效降低成本。
这里是cost down 。不是cut down 。
校验提示文案
Babesun
校验提示文案
Danny_橙子控
校验提示文案
建榕欧巴
校验提示文案
xmdt
校验提示文案
Dkfeng
校验提示文案
值友6294904587
校验提示文案
对方-正在输入
校验提示文案
低能患者
校验提示文案
唯酱与梓喵
校验提示文案
yingshengwo
校验提示文案
gaojie20
校验提示文案
沉溺99
校验提示文案
蚊子大大
校验提示文案
oxxxo
因为CUT DOWN会产生巨大的利润,节约成本,面对市场巨大的竞争压力,只有阉割才能有效降低成本。
这里是cost down 。不是cut down 。
校验提示文案
情忆無庸
校验提示文案
汤墨客
校验提示文案
wolflife
校验提示文案
rainbowmoon
校验提示文案
值友7281668910
校验提示文案
亲我叫尼古丁
校验提示文案
会跑的葡萄糖
校验提示文案
杲子
校验提示文案
浩渺星尘
校验提示文案
Darkhucx
校验提示文案
Babesun
校验提示文案
LiamX
校验提示文案
pc4649
校验提示文案
青春的良民
校验提示文案