
















































































259
225
AI最前线 篇五十三:从基础到创新:深入解析2023年大型语言模型的推理优化技术
2023-11-25 09:42:09
3点赞
7收藏
3评论
文章《掌握大型语言模型(LLM)技术:推理优化》由Shashank Verma和Neal Vaidya于2023年11月17日撰写,对大型语言模型(LLM)推理过程中的挑战和解决方案进行了深入分析。文章涵盖了一系列技术和策略,旨在优化LLM的推理阶段,这对有效部署和利用这些模型至关重要。(原文链接:https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/)
文章要点
理解LLM推理:
LLM(如GPT-3)使用一系列令牌来自回归地生成后续令牌。
推理过程包括两个阶段:预填充阶段(处理输入令牌)和解码阶段(生成输出令牌)。解码阶段是内存受限的,对优化GPU计算能力提出了挑战。
批处理:
批处理可提高GPU利用率和吞吐量,但批大小有限制,受内存约束。传统批处理由于批内不同请求的执行时间不同而显得次优化。
键值(KV)缓存:
在解码阶段使用KV缓存,以避免在每个时间步重新计算所有令牌的张量。有效管理KV缓存至关重要,因为它具有显著的内存占用。
LLM内存需求:
LLM在GPU上的主要内存需求是模型权重和KV缓存。有效管理这些是实现有效推理的关键。
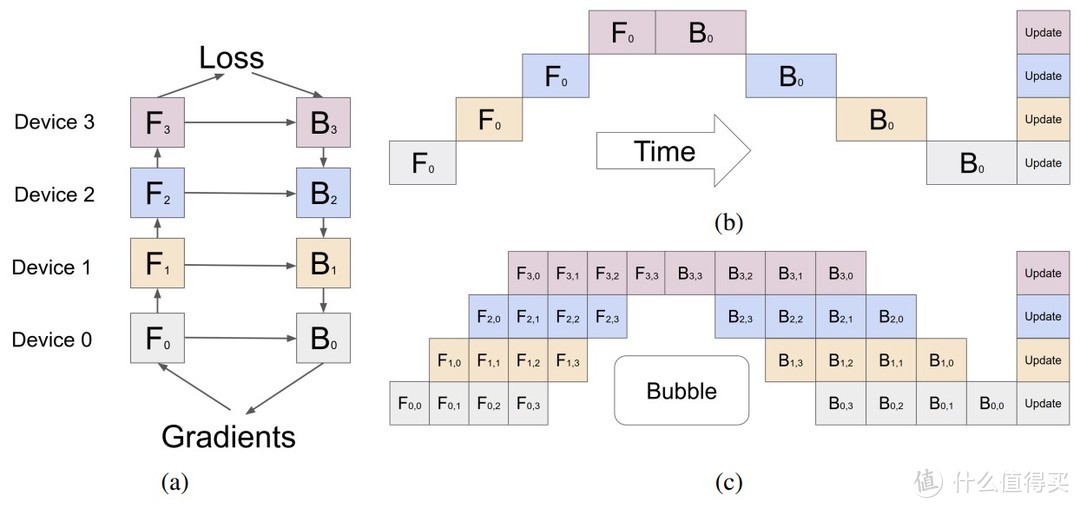
模型并行化:
在多个GPU上分布模型权重可以减少每个设备的内存占用。技术如管道并行化、张量并行化和序列并行化被用于优化跨多设备的模型性能。
优化注意力机制:
多头注意力(MHA)、多查询注意力(MQA)和分组查询注意力(GQA)等技术被用于优化LLM中的注意力机制。
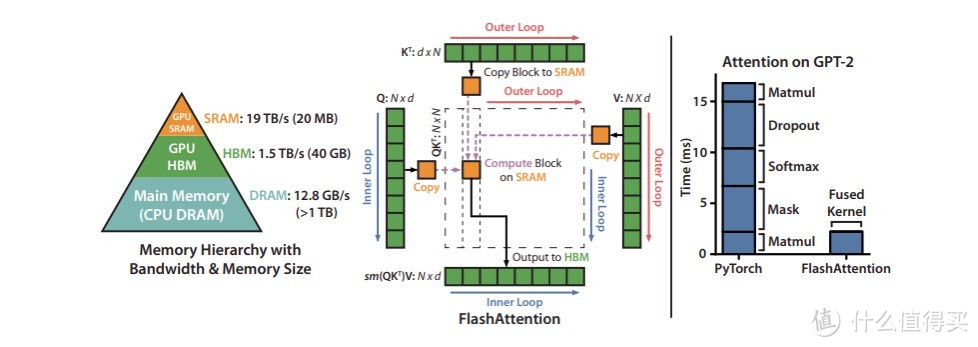
Flash注意力:
Flash注意力通过重新排序计算来优化,以更好地利用GPU内存层次结构,减少对内存的读/写操作。
高效管理KV缓存的分页技术:
PagedAttention算法解决了KV缓存管理中的内存浪费和碎片化问题,通过块表在注意力计算中按需获取块。
模型优化技术:
使用量化(降低权重和激活的精度)、稀疏性(使用稀疏矩阵)和蒸馏(将知识转移到较小的模型)等技术来减少每个GPU上的内存使用,并加速操作。
模型服务技术:
采用飞行中批处理和推测性推理等方法来提高LLM服务的效率,以应对这些模型的动态负载和执行特性。
NVIDIA TensorRT-LLM:
许多这些技术通过NVIDIA TensorRT-LLM提供,这是一个用于优化NVIDIA GPU上LLM推理的开源库。它由NVIDIA Triton推理服务器支持,使企业能够同时在不同的AI框架、硬件加速器和部署模型上服务多个AI模型。
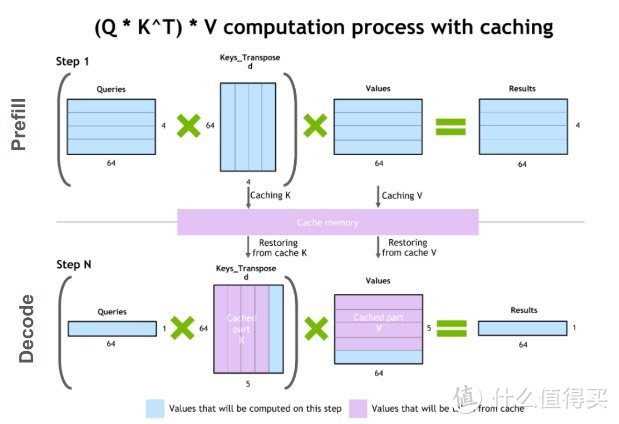
文章中关于大型语言模型(LLM)显存占用的细节主要涉及以下几个方面:
显存占用的主要因素:
模型权重:模型参数占据的内存。例如,一个7亿参数的模型(如Llama 2 7B)在16位精度(FP16或BF16)下大约占用14GB内存。
键值(KV)缓存:为避免重复计算自注意力张量而占据的内存。KV缓存用于存储每个时间步长生成的键和值张量。
KV缓存的大小计算:
KV缓存每个令牌的大小:计算公式为:
每个令牌的KV缓存大小(字节)= 2 * (层数) * (头数 * 头维度) * 精度所占字节数。这里的“2”代表键和值矩阵。总KV缓存大小:计算公式为:
总KV缓存大小(字节)= (批处理大小) * (序列长度) * 2 * (层数) * (隐藏层大小) * sizeof(FP16)。以Llama 2 7B模型为例,16位精度下,批处理大小为1时,KV缓存的大小大约为2GB。
显存占用的挑战:
KV缓存的大小随批处理大小和序列长度线性增长,迅速增加内存需求。
为最大可能输入量静态过度分配KV缓存,导致内存浪费或碎片化。例如,若模型支持的最大序列长度为2048,无论输入和输出的实际大小如何,都会预留2048大小的内存。
KV缓存的高效管理:
PagedAttention算法:灵感来自操作系统中的分页技术。它将每个请求的KV缓存划分为代表固定数量令牌的块,这些块可以非连续地存储在内存中。这种方法有效减少了内存浪费,从而允许更大的批处理大小和提高吞吐量。
综上所述,LLM的显存占用主要由模型权重和KV缓存构成,其中KV缓存管理是一个关键挑战,需要精细的策略来优化内存使用,从而提高模型的效率和性能。
结论
文章提供了当前LLM推理优化的全面概述。它强调了有效管理内存和计算资源、利用并行性以及采用先进的注意力机制优化和模型服务策略的重要性。这些进步对于LLM在各种应用中的实际部署和可扩展性至关重要。
















太平洋的水
校验提示文案
飞机大炮机关枪
校验提示文案
飞机大炮机关枪
校验提示文案
太平洋的水
校验提示文案