































































37
48
A卡偷电,N卡偷U(战术核显卡) 、战未来
2023-02-28 17:23:58
47点赞
87收藏
16评论
额……老铁们,我图吧老捡垃圾的了。最近咱一直在忙活测试国产CPU在4K下的游戏表现,期间用到了面对N卡的时候的一些优化方法。正好上期咱讲了为什么AMD会被称为农企? ,所以这期咱继续,简单讲下隔壁卡吧的梗。
这次的梗其实相比上期语焉不详来源不明的梗明确很多,是可以直接找到出处的。
1.A卡偷电,N卡偷U(偷电部分)
这个梗的来源其实年代比较久远,距今大约有十年甚至后半句应该达到十年以上了。
关于A卡偷电这个梗其实比较容易解释,就是AMD在强拉GCN小架构核心频率的时候错过了最佳能效导致功率表现不佳,显卡实际功耗大于设计功耗的这么一个情况。



具体症状表现为单6PIN供电带不动显卡,需要从主板的PCIe多取电
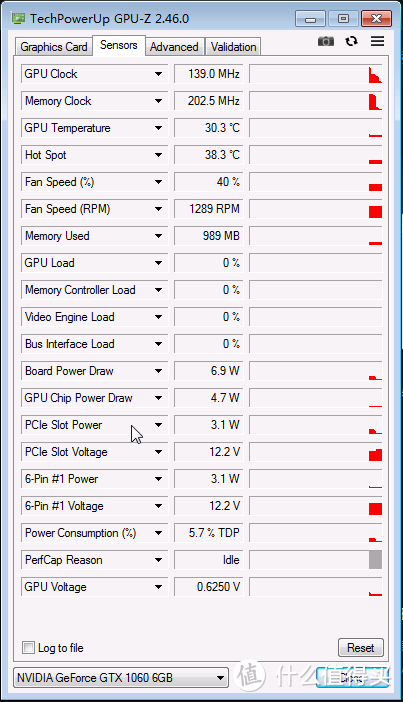
A卡咱不知道,如果是N卡的话用GPUz之类的看统计信息可以发现偷电状态下PCIe SLOT POWER是高于75W的
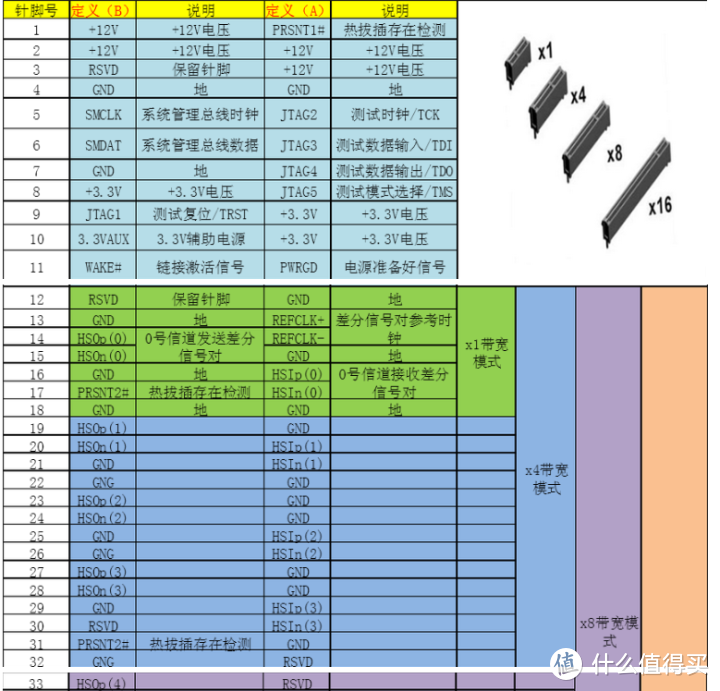
正常来说PCIe无论1.1 2.0 3.0还是以上版本×多少带宽从主板取电的插槽供电能力是固定的75W,一般的主板由于12V供电设计不足通常PCIe供电只能按50W计算,高于这个功耗就要上外接供电(所以垃圾佬的七彩虹750没Ti也有6pin的供电),早期主板甚至由于ATX电源供电能力不足还会特意在显卡的PCIe旁边设计大4D供电口增强供电。
普通消费级显卡本身带宽都是×16 ,少部分低端亮机卡可能会用×8或者更低,然而无论工作在×多少PCIe的供电看定义图就知道供电是一样的。
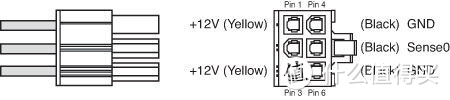
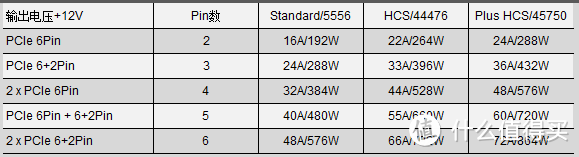
单6PIN是外接供电里面最弱的,理论上只能提供双路12V 8A输入,实际上还会低一些一般只能算75W,有的情况下可以用SATA转6PIN给总功率120W的显卡供电但是到显卡电压会降,转接线如果太细容易出问题总之不是什么好事。所以150W的如果功耗控制压不住,实际功耗大于TDP很容易就导致6PIN没法给出足够供电最后要从主板多取电。
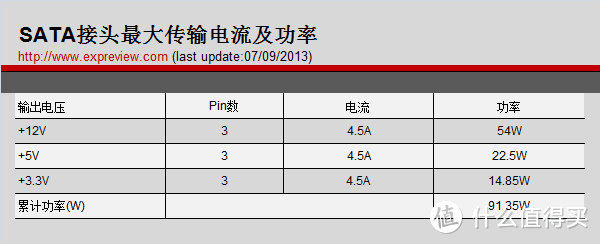
如果显卡的功耗太高外接6PIN 8PIN的供电不足以满足功耗需求显卡就会从主板过量取电作为补偿,这样的话一些做工比较差供电冗余能力不足的低端主板很容易出问题,所以A卡偷电还是挺严重的问题的。

后来A卡在RX480的马甲RX580上换了8pin供电解决了A卡偷电的问题。所以现在市面上大批量用RX470 480 570甚至470D刷出来的580通常也都面临同样的问题,别的第三方我不知道公版的话AMD的580肯定是8PIN(6+2)起步的,6PIN只要买到基本都可以按刷BIOS处理。
所以不建议各位入手AMD RX580矿卡的理由又多了一个

风水轮流转,历史是个圈,现在回到N卡功耗差+烧供电接口的时代了。这样的显卡连供电接口都无法保护恐怕从主板偷电也是必然的了。追求极致性能不考虑能效功耗的时代终会过去,历史大浪淘沙只有最好的产品才能历久弥新。
2.核弹显卡(战术核显卡)
核弹卡这个梗其实比较简单了,基本上一句战术核显卡就能解释:




这里我们不能简单看电视台照着百度百科念稿然后整出冥场面的表象,要研究显卡被称为核弹的深层原理。
上期为什么AMD显卡矿卡多? 中我们说过AMD的显卡无论是HD6000以前的VILW还是GCN都是小核心的架构,以提升能效比堆芯片规模提高流处理器数量为思路,而NVIDIA在当时的G80 G92 GT200核心都是大核心面积高功耗高发热的大核心架构所以被用户冠以核弹之名。直到费米和开普勒时代N卡的能效比低核心面积大的问题都没解决,直到后来才慢慢开始精简核心走小核心的数量。这样就导致了后续的很多问题,接下来我们会说。

GK104有35.4亿个晶体管以及294 mm²的核心面积,单核心最大功耗可以轻松达到200W+,双芯显卡(相当于单显卡内部有两个GPU进行SLI或者交火)的GTX690还只能屈居第二作为第二代核弹卡。
顺带说下这卡现在已经没用了,即使是公版的GTX690或者是680 770 780什么的现在也相当便宜,因为它核心已经老了NVIDIA已经放弃驱动更新支持,就连最新的画图AI什么的都跑不了了那个要求CUDA3.7然而KEPLER架构的核心普遍只能支持CUDA3.0,跑画图AI最低要求也得是MAXWELL的GTX750,开普勒的马甲卡都不行。

初代核弹卡GTX590采用了两个40nm的GF110费米核心,芯片尺寸为 520 平方毫米,晶体管数量为 30 亿个,是一个非常大的芯片。至于功耗?好吧,单芯功耗最高可达600W,是个放在今天都非常惊人的水平我敢说40系显卡也没有这么NB的功耗。所以今天的龙芯圈攻击隔壁国产X86 CPU 70W功耗太高烤机的时候整机功耗超过100W在图吧垃圾佬眼里看都不算事,过去和现在比这离谱的功耗有的是,现在的轻薄本卷45W+甚至极限功率65-90W的都有,游戏本更是200-300W都不少见。

顺带说下作为40系Fermi架构的原名现实中的恩里科·费米真的是核物理学家,参加过曼哈顿计划,完成了首次人工自持续链式反应。可能这也是第一代核弹卡会在N卡发展到费米架构才得名的原因吧。也可能在更早的时候N卡就有核弹的名号但是没有具体被绑定在某一个固定的显卡型号上。
3.N卡偷U
关于A卡偷电的资料其实非常多,毕竟这个事情非常简单三言两语就能说明白,但是对于N卡偷U来说资料就很少了。具体的科普视频现在现存其实非常少,只有这两个视频有具体涉及原理的讲解,各位有兴趣可以看看:
【显卡】科普:CPU不能选太差,小心“N卡偷U” BV12i4y1P7nF
【科普】【Dataland】N卡偷U?A卡战未来? BV1zW411B7rz
之前我们在上文以及前作为什么AMD显卡矿卡多? 中说过,N卡的费米核心作为同时兼顾游戏和运算功能的计算卡核心,它拥有相当高的双精度运算的性能(虽然流处理器数量相比特斯拉架构大幅提升但是每个流处理器的性能却大幅降低了),而当时N卡拥有相当复杂的硬件调度器,这可以让CPU节省更多的资源却增大了显卡的负载,客观上恶化了费米显卡功耗高芯片面积大的问题。所以在开普勒时代N卡就开始将调度器精简,并把GPU硬件资源调度的工作甩给CPU,具体就是把GPU指令调度转移到CPU(通过驱动层面编译器),所以N卡在DX11上有相当强的优势以及在DX12和VULKAN存在劣势。这也是NVIDIA看准了DX12短时间内不会普及做出的决定。从今天来看这个眼光相当之准,直到今天原神之类的游戏还在用DX11,DX12和VULKAN并没有大范围推广。
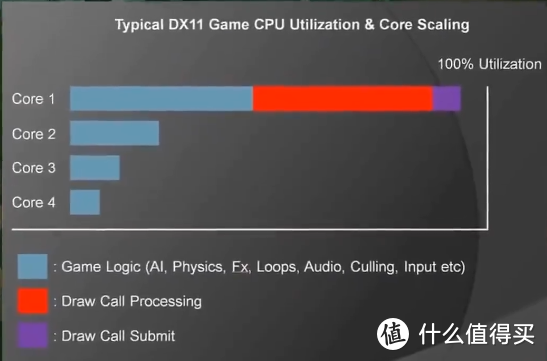
而对于CPU来说,N卡相比A卡占用了更多的CPU资源是一定的,因为CPU要负责GPU的指令调度,所以驱动程序会占用更多的CPU资源,这样对于单核性能不强或者核心数量不高的CPU来说就更加明显了。
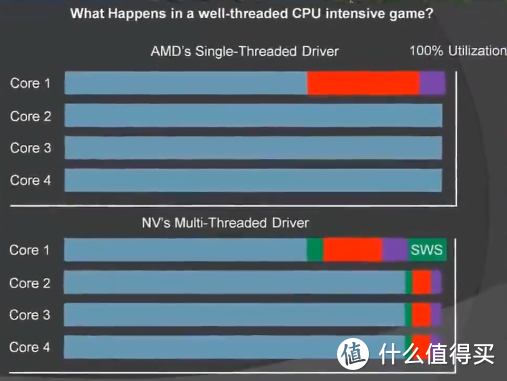
无论驱动是否能把调度GPU指令占用的CPU负载均摊,一般来说对于CORE 0主线程的负载都更高。所以对于垃圾佬来说的实际影响就是对于兆芯KX6000这种单核性能不够核心数来凑的小核心架构CPU来说如果全核性能够用单核性能不足的前提下,在任务管理器中可以有效避免CPU0跑满的问题优化CPU调度。
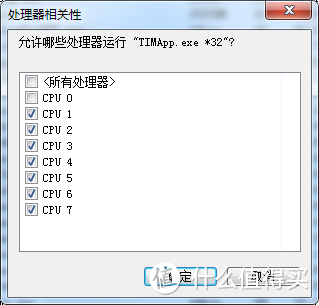
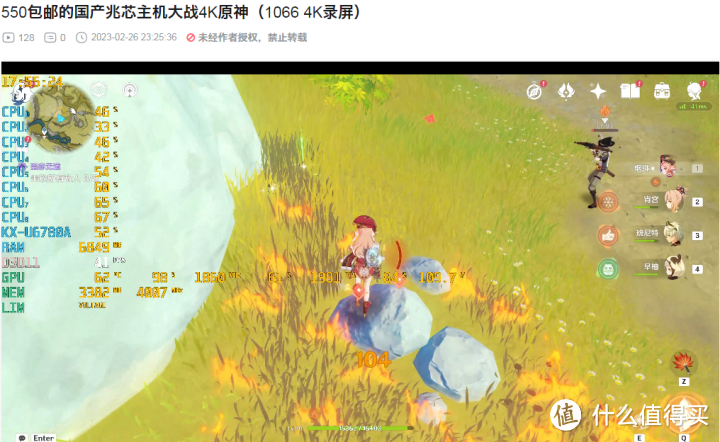
即使解除了游戏进程CPU0的进程相关性,CPU0进程或者说图上显示的CPU1依然有挺高的负载,这也就是N卡驱动使用CPU调度GPU指令的开销了,过去这个开销和游戏进程一起压在CPU0上就容易造成游戏的卡顿,现在知道N卡偷U的原理之后就可以把CPU0进程让出来给显卡驱动用剩下的核心在均摊游戏进程负载就好了。
解决了这个问题之后,垃圾佬可以拿550包邮的国产CPU主机配1066大战3A甚至开4K,这也是比较意外同时又在意料之中的一点。
意外的是国产CPU的性能居然能拉得动4K游戏,这个水平确实让人非常意外,但是意料之中的又是垃圾佬捡垃圾多年,早就知道CPU性能其实已经走到了显卡的前面。无论是AMD羿龙2六核还是英特尔X58,CPU的多核性能水平其实到现在早就能满足日常使用需求甚至十年以上的硬件都绰绰有余。真正的性能瓶颈主要还是在显卡,无论是运行AI还是图形处理,CPU的时代早就落寞了。真正成为瓶颈的其实是国产显卡。不知道国产显卡未来会是什么设计,无论购买IP核还是自行设计,驱动对CPU的硬件占用都是相当有意思的参数,无论偏向硬件调度器还是软件调度器,都需要配合软件优化才能实现最佳表现。
总之解决N卡偷U的问题其实从根本上是无解的,取决于核心设计。至于任务管理器手动调节游戏的进程相关性这个方法只能缓解问题,对于所有费米以上的N卡来说都有效,当核心数量多单核性能偏弱的时候都可以让出CPU0的进程给N卡驱动使用。
4.AMD战未来(鸡血驱动)
经过上面的故事我们已经知道了AMD的显卡在GCN时代之后越来越像费米时代的设计思路,保留了计算卡的特性。当然大小核心的区别还是有的。而且AMD保留显卡的双精度浮点之类的运算性能的原因也是比较明确的:服务于HSA异构计算的APU,即AMD推土机打桩机压路机挖掘机架构时代的设计思路,削减CPU浮点性能,将浮点运算交由GPU进行,这个思路放在今天是相当不错的,ARM就继承了这个思想,在移动端大量应用。然而AMD本身却拉了很长时间最后放弃或者说搁置了HSA异构计算的设计,但是直到现在依然保留了显卡的双精度浮点性能并没有像N卡一样直接砍了,计算卡游戏卡分家。
AMD GCN的故事我们就比较熟悉了,祖传架构,多年不换。

结果就是AMD的显卡早期在刚出现的时候首版驱动表现不佳,性能发挥相当感人,当时AMD的HD7850甚至打不过750,而N卡的驱动优化一直很好,即使后期在偷U整体表现也比AMD强。但是AMD后来由于多年一直打磨GCN架构多少年不换,就导致每当有驱动更新老卡都能享受优化性能表现就有提升,像7850的性能直到22年还能凹,每次都有新感觉。这个提升幅度还是相当大的。所以到今天19年卖100的7850还卖100,19年200的GTX670却卖不到200了,已经结束类放弃驱动支持了。
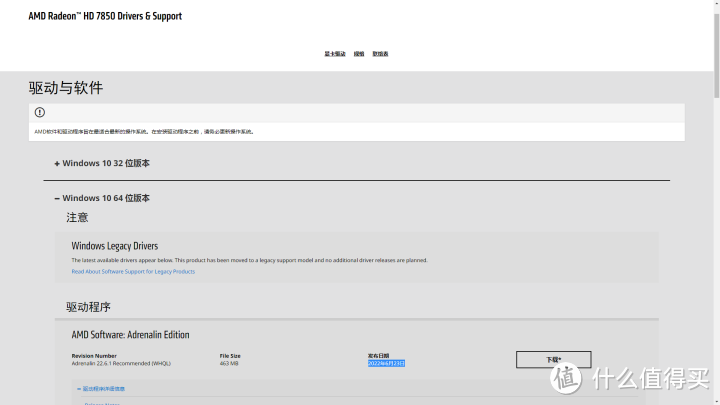
A卡已经启用RDNA架构多年却还在更新GCN1.0显卡驱动,他真的我哭死。
所以之前我们说AMD矿卡为什么多还只是一个模糊概念,A卡更适合计算挖矿更强之类的。其实有没有这么一种可能,就是A卡可能真的很强,不单单是挖矿性能能体现出来计算性能,游戏性能其实在有足够优化的情况下也能体现出来,包括英特尔和摩尔线程。
这里简单接上期说一下:挖矿的傻吗,买一大堆性能不咋地功耗还高的显卡回去挖矿不是等着亏钱吗,其实并不是。
RTX3080超频后ETH算力大概在60-65MH/s左右,还得是三星颗粒显存才行。按照过去的币价,每天赚37元。去掉电费、矿池抽水、挖矿软件抽水、超频不稳定的干扰,当天净收益勉强到35元。
华硕将 CMP 40HX 矿卡的挖矿效率将从英伟达官方宣布的 36 MH/s 提高到 43.77 MH/s。从内部测试的截图判断,CMP 40HX 卡的功率已经由厂家优化到到仅 135W,从而将挖矿效率提高至 400 KH/W。
AMD RX 580 can reach 32.74 MH/s hashrate and 84 W power consumption for mining ETH (Ethash). Nvidia P106-100 can reach 21.35 MH/s hashrate and 107 W power consumption for mining ETH (Ethash).
GTX 1060 正常算力是超频23MH/s,默频20MH/s
NVIDIA GeForce GTX 960 can reach 7.26 MH/s
Nvidia GTX 1080 can reach 35.16 MH/s hashrate and 160 W power consumption for mining ETH
长话短说就是AMD的GCN显卡以RX580举例它算力可以达到32.74而功耗仅84W,而1066或者P106只能达到20多还得用100W以上,960之类的都没法看,1080要达到同样的算力也得至少160W,所以挖矿的肯定不爱用,贵又费电,挖矿肯定卷不过能效比高的卡。
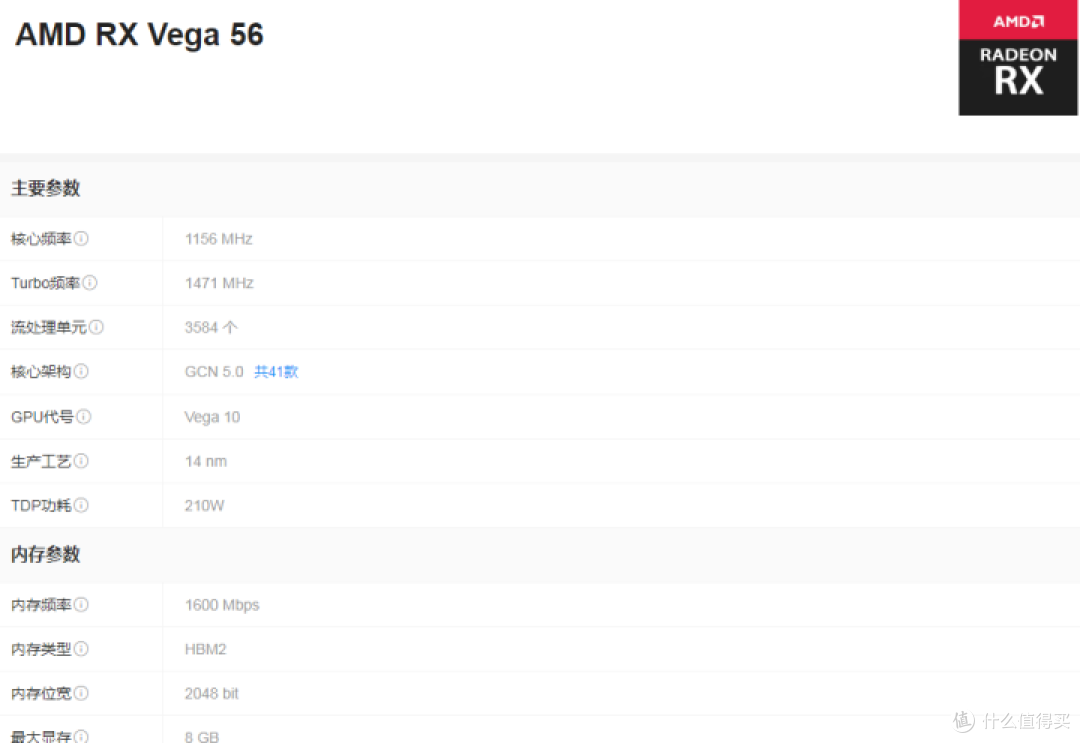
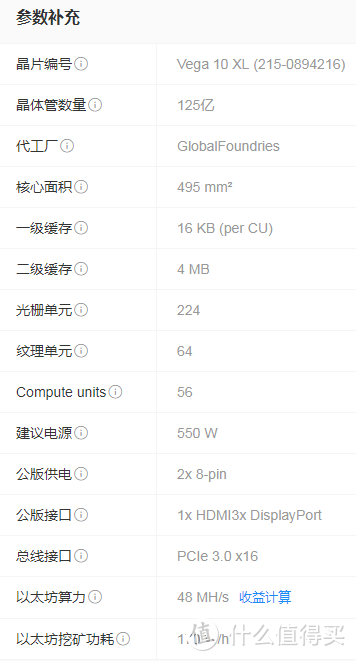
而后来的40HX之类的其实也是卷不过AMD的GCN5.0 VEGA显卡的,这玩意内置HBM2显存,对于吃显存的挖矿来说更是如虎添翼,所以这波矿潮中招的A卡数量肯定是远远大于N卡的,这个不用怀疑,但是还是那句话,如果因为挖矿就砍掉游戏卡的运算性能那是因噎废食,挖矿的打击或者说管制还是需要靠法制而不是自废武功的。当然如果国产能出手像硬盘矿一样靠提产能大量出货低价高质产品干崩挖矿也不是不可能,那具体就看他们本事了。
就这样,谢谢朋友们!
作者声明本文无利益相关,欢迎值友理性交流,和谐讨论~

















好好生活小沣沣
校验提示文案
让二追三
校验提示文案
高玩机霸
校验提示文案
WittmanARC
但根据我个人的经验,在RX480刷入RX580 VBIOS后,功耗监测将会出现严重异常——驱动回报功耗仅105W,但VRM端的实际功耗可能已突破200W。
考虑到大部分“刷580 VBIOS”是北极星显卡的“标准操作”,这样的风险不言而喻
校验提示文案
值友8218666265
校验提示文案
回忆里流浪
校验提示文案
忧情狂猫
校验提示文案
值友1232946393
校验提示文案
為誰風露立中宵
校验提示文案
為誰風露立中宵
校验提示文案
值友1232946393
校验提示文案
好好生活小沣沣
校验提示文案
值友8218666265
校验提示文案
WittmanARC
但根据我个人的经验,在RX480刷入RX580 VBIOS后,功耗监测将会出现严重异常——驱动回报功耗仅105W,但VRM端的实际功耗可能已突破200W。
考虑到大部分“刷580 VBIOS”是北极星显卡的“标准操作”,这样的风险不言而喻
校验提示文案
忧情狂猫
校验提示文案
回忆里流浪
校验提示文案
让二追三
校验提示文案
高玩机霸
校验提示文案