









































































262
100
与 VMFS 斗争(上)群晖 ext4 文件系统的扫描修复
2021-08-23 14:39:12
9点赞
38收藏
7评论
最近一个月一直在和VMFS存储斗争,除了vSan,家里的两台服务器也轮流故障。其实这玩意很稳定,这几次故障也都是外部因素导致的。整个修复过程中查了很多资料,对文件系统也有了新的理解。那么还是要赶快整理记录下来,以备以后参考。
背景
一直在用的 Brix 主机在正常使用中经历了两次硬盘掉电(明显听到硬盘吱的一声)后,群晖虚拟机报文件存储故障。首先考虑更换了不到两年的硬盘故障(参考 GIGABITE Brix B10M 硬盘更换记)。但经过一晚上的扫描测试,没有发现任何问题。看SMART数据也都是正常的。
但重新开机进系统后发现仍有异常,文件读写明显卡顿。于是再次拆开检查。这次扫描了作为缓存的固态硬盘,发现存在严重故障。
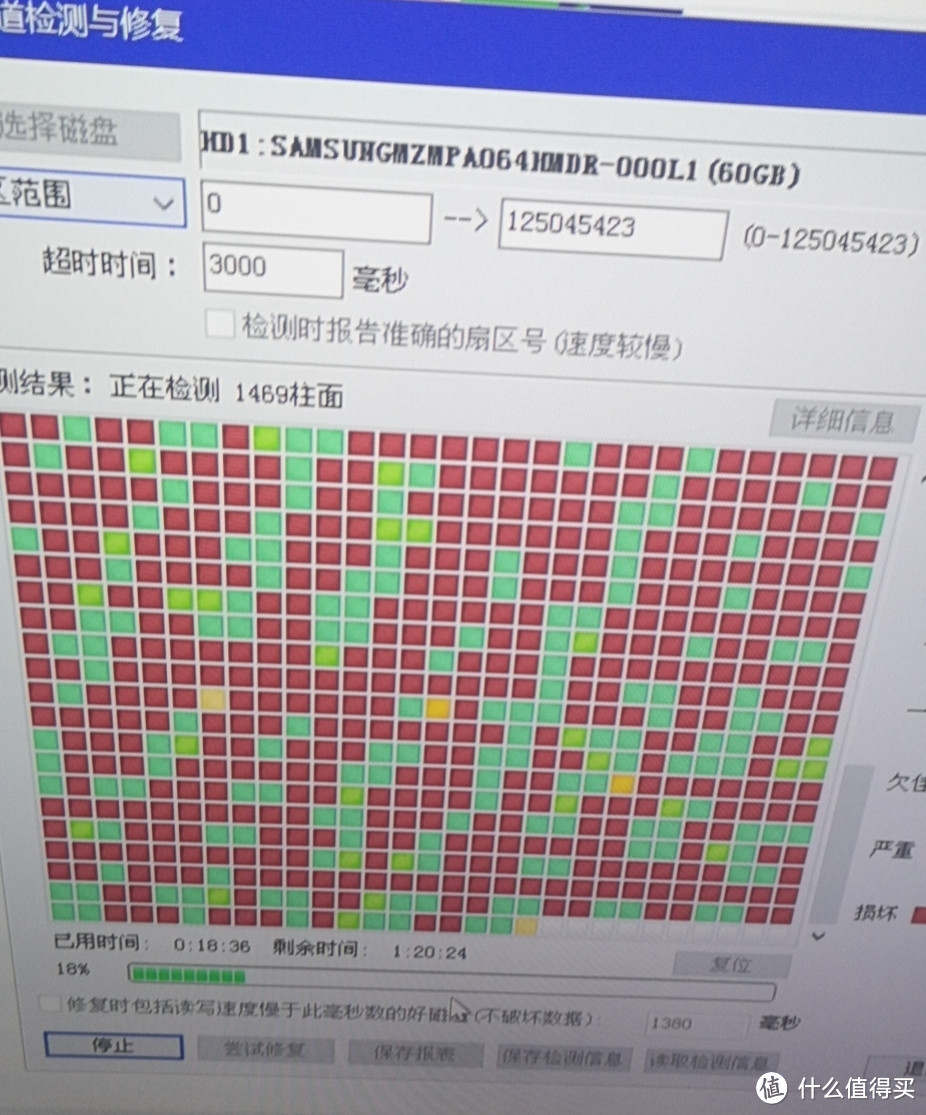
定制了一块固态硬盘换上后,正常开机,下面开始修理虚拟机存储问题。
 上:订制的240G 下:三星64G msata接口
上:订制的240G 下:三星64G msata接口
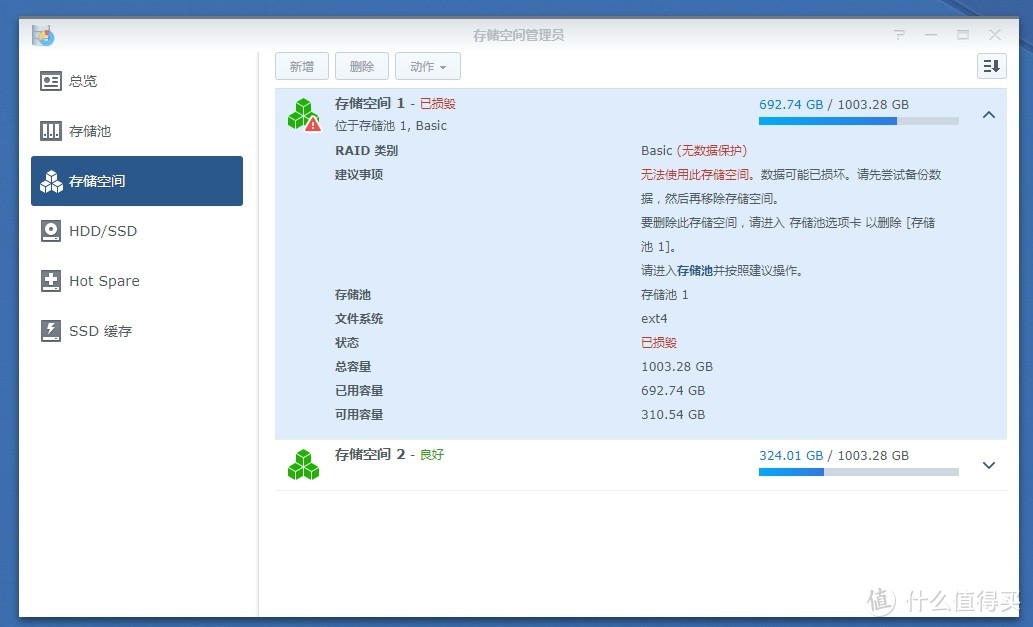
群晖存储池“已损毁”的修复
群晖挂载了两块虚拟磁盘作为存储。其结构如下:

其中md0存储了群晖操作系统文件,md1存储了群晖的配置文件。应用程序和应用配置都在存储空间中。观察发现/volume1中所有的文件都能正常读取,但无法写入。/volume2可以正常读写。所以将问题锁定在sdb3和md2。
开启群晖的SSH访问,然后停止DSM系统但不关机:
sudo syno_poweroff_task -d
由于我建立时选择分区类型为ext4,所以使用fsck对分区进行扫描
sudo fsck.ext4 -pvf /dev/md2
修复分区问题后继续修复虚拟阵列。由于阵列信息均存在且正确,只需强行以正常模式挂载即可
sudo mdadm --stop /dev/md2
sudo mdadm --assemble --force /dev/md2 /dev/sdb3
使用 mdadm -D 命令查看阵列状态,发现已经是clean,active sync状态了
最后重启系统,重启后发现文件可以正常读写了,可是仍然提示系统分区处于损坏状态。
群晖“系统分区处于损坏状态”的修复
由于群晖会在每一个配置的硬盘中都写入一份系统文件(raid0),所以sdb1的损坏并没有影响到系统正常工作。但/无法解挂载,下面考虑两种方法:一是重新挂载系统分区为只读模式(试了没成功),二是将磁盘挂载到其他系统处理。
新建虚拟机,挂载Ubuntu Live CD,然后将群晖的两块磁盘同时挂载在Ubuntu下,重建阵列:
mdadm -Cf -e0.9 /dev/md0 -n2 -l1 /dev/sdb1 /dev/sdc1 --uuid=6f00e709:……
其中 -e0.9表示版本0.9;-n2表示阵列中有2块盘;-l1表示raid1。e、l、uuid均由原阵列信息中取出。执行后会覆盖分区内原有raid信息。
原阵列中设计为12块盘(3617默认最多12盘),将阵列增长为12盘
mdadm --grow --force /dev/md0 -n12
重新挂载到群晖后开机,会自动进行一致性检查(同步)。同步完成后会收到通知。
后记
好在群晖挂载了两块虚拟硬盘,一块故障了另一块可以正常工作。如果只有一块而且系统分区损坏,就只能重装系统了,会麻烦很多。另一方面ext4扫描修复还是比较方便的。如果是btrfs,会更麻烦一些。
但是吧,这块不到两年的硬盘仍不时的丢失连接,考虑到硬盘已经扫描过没有问题,很可能是传输线故障了。但这线在网上又买不到……
















龙彪
校验提示文案
白白的小手
校验提示文案
Taoss
校验提示文案
巴伐利亚南大王
校验提示文案
白白的小手
校验提示文案
巴伐利亚南大王
校验提示文案
龙彪
校验提示文案
Taoss
校验提示文案