
























































131
80
数值计算,深度学习基础知识最后章节
2020-02-20 12:59:59
6点赞
36收藏
1评论
宅在家没事儿,还是来教一教大家机器学习吧。
前面系列的一篇在这里:

注意!本系列文章只是写了玩玩,想要学东西的快去看书,想要看代码的去GitHub,而不是盯着我这些所谓的教程,本系列文章只是为了写一写碎片化的介绍!上来就说不如哪个大神的评论就不要写了,我都说了我只是萌新。你们也不想想,真正的大神都去花时间赚钱了,哪有时间过来写这样的文章。当然,如果你真的想系统化学习,可以直接找我一对一给你上课,收费的。不便宜,但是肯定比其余地方的所谓的网课要真实并且干货多。
本章节关键词为:上溢和下溢,病态条件,基于梯度的优化方法,约束优化,例子:线性最小二乘法。
本章我们讨论数值计算。但是我并不会讲细节,你真的想学的话可以过来花钱请我教你。这些是入门课程。
机器学习算法通常需要大量的数值计算。这通常是指通过迭代过程更新解的估计值来解决数学问题的算法,而不是通过解析过程推导出公式来提供正确解的方法。常见的操作包括优化(找到最小化或最大化函数值的参数)和线性方程组的求解。对数字计算机来说实数无法在有限内存下精确表示,因此仅仅是计算涉及实数的函数也是困难的。
连续数学在数字计算机上的根本困难是,我们需要通过有限数量的位模式来表示无限多的实数。这意味着我们在计算机中表示实数时,几乎总会引入一些近似误差。在许多情况下,这仅仅是舍入误差。舍入误差会导致一些问题,特别是当许多操作复合时,即使是理论上可行的算法,如果在设计时没有考虑最小化舍入误差的累积,在实践时也可能会导致算法失效。

一种极具毁灭性的舍入误差是下溢(underflow)。当接近零的数被四舍五入为零时发生下溢。许多函数在其参数为零而不是一个很小的正数时才会表现出质的不同。例如,我们通常要避免被零除(一些软件环境将在这种情况下抛出异常,有些会返回一个非数字 (not-a-number, NaN) 的占位符)或避免取零的对数(这通常被视为 −∞,进一步的算术运算会使其变成非数字)。
另一个极具破坏力的数值错误形式是上溢(overflow)。当大量级的数被近似为∞ 或 −∞ 时发生上溢。进一步的运算通常会导致这些无限值变为非数字。
必须对上溢和下溢进行数值稳定的一个例子是softmax 函数(softmax function)。softmax 函数经常用于预测与 Multinoulli 分布相关联的概率。

条件数表征函数相对于输入的微小变化而变化的快慢程度。输入被轻微扰动而迅速改变的函数对于科学计算来说可能是有问题的,因为输入中的舍入误差可能导致输出的巨大变化。
考虑函数 f(x) = A^−1*x。当 A ∈ R n×n 具有特征值分解时,其条件数为最大和最小特征值的模之比。当该数很大时,矩阵求逆对输入的误差特别敏感。
这种敏感性是矩阵本身的固有特性,而不是矩阵求逆期间舍入误差的结果。即使我们乘以完全正确的矩阵逆,病态条件的矩阵也会放大预先存在的误差。在实践中,该错误将与求逆过程本身的数值误差进一步复合。

大多数深度学习算法都涉及某种形式的优化。优化指的是改变 x 以最小化或最大化某个函数 f(x) 的任务。我们通常以最小化 f(x) 指代大多数最优化问题。最大化可经由最小化算法最小化 −f(x) 来实现。
我们把要最小化或最大化的函数称为目标函数(objective function)或准则(criterion)。当我们对其进行最小化时,我们也把它称为代价函数(cost function)、损失函数(loss function)或误差函数(error function)。虽然有些机器学习著作赋予这些名称特殊的意义,但在我这里我将交替使用这些术语。

最速下降在梯度的每一个元素为零时收敛(或在实践中,很接近零时)。在某些情况下,我们也许能够避免运行该迭代算法,并通过解方程 ∇x f(x) = 0 直接跳到临界点。
虽然梯度下降被限制在连续空间中的优化问题,但不断向更好的情况移动一小步(即近似最佳的小移动)的一般概念可以推广到离散空间。递增带有离散参数的目标函数被称为爬山(hill climbing)算法 (Russel and Norvig, 2003)。
有时我们需要计算输入和输出都为向量的函数的所有偏导数。包含所有这样的偏导数的矩阵被称为Jacobian(Jacobian)矩阵。

有时,我们也对导数的导数感兴趣,即二阶导数(second derivative)。二阶导数告诉我们,一阶导数将如何随着输入的变化而改变。它表示只基于梯度信息的梯度下降步骤是否会产生如我们预期的那样大的改善,因此它是重要的。我们可以认为,二阶导数是对曲率的衡量。假设我们有一个二次函数(虽然很多实践中的函数都不是二次的,但至少在局部可以很好地用二次近似)。如果这样的函数具有零二阶导数,那就没有曲率。也就是一条完全平坦的线,仅用梯度就可以预测它的值。我们使用沿负梯度方向大小为 ϵ 的下降步,当该梯度是 1 时,代价函数将下降 ϵ。如果二阶导数是负的,函数曲线向下凹陷 (向上凸出),因此代价函数将下降的比 ϵ 多。如果二阶导数是正的,函数曲线是向上凹陷 (向下凸出),因此代价函数将下降的比 ϵ 少。
当我们的函数具有多维输入时,二阶导数也有很多。我们可以将这些导数合并成一个矩阵,称为Hessian(Hessian)矩阵。

仅使用梯度信息的优化算法被称为一阶优化算法 (first-order optimization algorithms),如梯度下降。使用 Hessian 矩阵的优化算法被称为二阶最优化算法(second-order optimization algorithms)(Nocedal and Wright, 2006),如牛顿法。
在深度学习中使用的函数族是相当复杂的,所以深度学习算法往往缺乏保证。在许多其他领域,优化的主要方法是为有限的函数族设计优化算法。
在深度学习的背景下,限制函数满足Lipschitz 连续(Lipschitz continuous)或其导数Lipschitz连续可以获得一些保证。Lipschitz 连续函数的变化速度以Lipschitz常数(Lipschitz constant)L 为界。
最成功的特定优化领域或许是凸优化(Convex optimization)。凸优化通过更强的限制提供更多的保证。凸优化算法只对凸函数适用,即 Hessian 处处半正定的函数。因为这些函数没有鞍点而且其所有局部极小点必然是全局最小点,所以表现很好。然而,深度学习中的大多数问题都难以表示成凸优化的形式。凸优化仅用作一些深度学习算法的子程序。凸优化中的分析思路对证明深度学习算法的收敛性非常有用,然而一般来说,深度学习背景下凸优化的重要性大大减少。有关凸优化的详细信息,详见 Boyd and andenberghe (2004) 或 Rockafellar (1997)。
有时候,在 x 的所有可能值下最大化或最小化一个函数 f(x) 不是我们所希望的。相反,我们可能希望在 x 的某些集合 S 中找 f(x) 的最大值或最小值。这被称为约束优化(constrained optimization)。在约束优化术语中,集合 S 内的点 x 被称为可行(feasible)点。
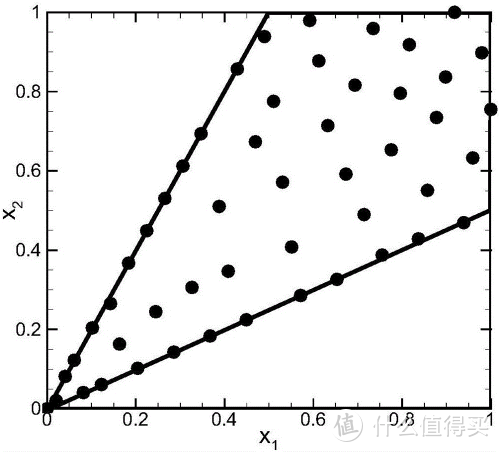
约束优化的一个简单方法是将约束考虑在内后简单地对梯度下降进行修改。如果我们使用一个小的恒定步长 ϵ,我们可以先取梯度下降的单步结果,然后将结果投影回 S。如果我们使用线搜索,我们只能在步长为 ϵ 范围内搜索可行的新 x 点,或者我们可以将线上的每个点投影到约束区域。如果可能的话,在梯度下降或线搜索前将梯度投影到可行域的切空间会更高效 (Rosen, 1960)。
一个更复杂的方法是设计一个不同的、无约束的优化问题,其解可以转化成原始约束优化问题的解。例如,我们要在 x ∈ R 2 中最小化 f(x),其中 x 约束为具有单位 L 2 范数。我们可以关于 θ 最小化 g(θ) = f([cosθ,sinθ] ⊤ ),最后返回 [cosθ,sinθ]作为原问题的解。这种方法需要创造性;优化问题之间的转换必须专门根据我们遇到的每一种情况进行设计。
不等式约束特别有趣。如果 h (i) (x ∗ ) = 0,我们就说说这个约束 h (i) (x) 是活跃(active) 的。如果约束不是活跃的,则有该约束的问题的解与去掉该约束的问题的解至少存在一个相同的局部解。一个不活跃约束有可能排除其他解。例如,整个区域(代价相等的宽平区域)都是全局最优点的的凸问题可能因约束消去其中的某个子区域,或在非凸问题的情况下,收敛时不活跃的约束可能排除了较好的局部驻点。然而,无论不活跃的约束是否被包括在内,收敛时找到的点仍然是一个驻点。为了获得关于这个想法的一些直观解释,我们可以说这个解是由不等式强加的边界,我们必须通过对应的 KKT 乘子影响 x的解,或者不等式对解没有影响,我们则归零 KKT 乘子。
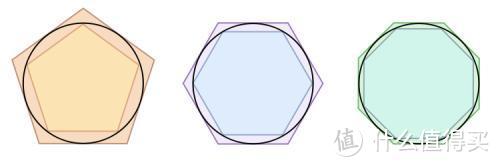
最小二乘法,牛顿法,二分法等等数值计算常用的思路方法,你们应该知道如何去解。其实基本思路非常简单,就是我们学积分和微分时候的近似与极限,只是在微积分中,我们的近似与极限都推导到无穷,最后形成了连续的,在计算机中,我们限于有限精度,只能推到我们能理解的有限大小。举个例子,用多边形代替圆形来近似计算圆形的面积,四边形,五边形,六边形,八边形,十六边形。。。。。。一直到几十万几百万边形,我们思维中可以无线接近圆,但是计算机不能,但是可以在我们要求的精度内模拟近似这个圆的面积。
以上,本章节大概概念介绍了一下,看不懂就别看了,哪里不懂就去看书做习题,想快速一点的可以问问我,我教你,当然,收费的。
建议看不懂但是还想学的,收藏一下,仔细看仔细思考。

















Carson卡森
校验提示文案
Carson卡森
校验提示文案