































































6
11
intel NUC12 蝰蛇峡谷也能深度学习?OpenVINO平台搭建+测试
2022-11-23 13:25:43
19点赞
65收藏
13评论
intel NUC12 蝰蛇峡谷推出已有一段时间,这段时间里各种测试已经充分展现了这个新的Enthusiast定位的NUC的实力。不过这些测试还没有展现NUC12蝰蛇峡谷的另一面,那就是蝰蛇峡谷在深度学习平台和视频剪辑与渲染的潜力
我之前就已经做过CUDA和ROCM的深度学习介绍,Nv和AMD两家对自己的深度学习平台都非常上心,而intel也是有自己的深度学习加速软件包的。作为最早推出神经网络加速棒的公司,intel在很早之前就推出了自己的OpenVINO加速包,这个工具可以适配所有的intel CPU GPU(iGPU) 和专门的VPU。而且面向全平台,除了unix内核的系统之外,还专门对win系统提供了支持
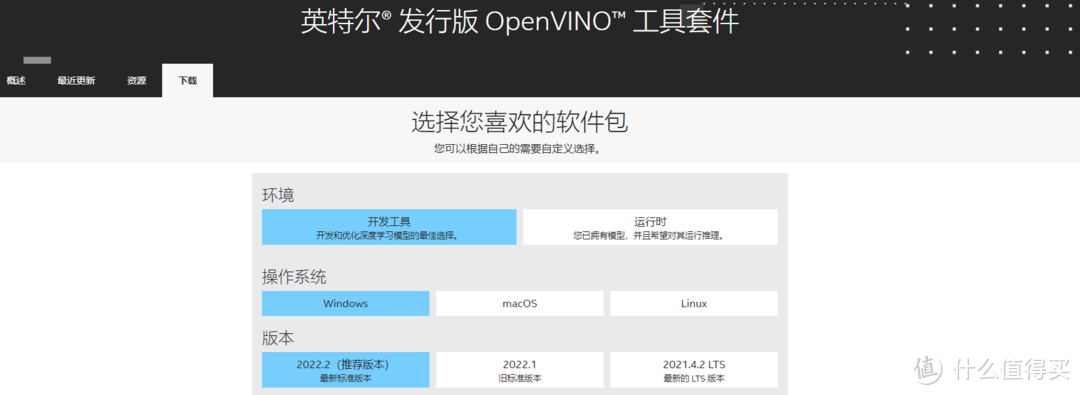
intel的OpenVINO对蝰蛇峡谷的12700H和Xe核显的支持是毋庸置疑的,而蝰蛇峡谷的A770M作为intel自家在今年才推出的一张独立显卡,能否即时适配OpenVINO呢?所以我最近就来尝试了一下intel的OpenVINO在自家独立显卡上的表现,顺便做个简单的教程,让有兴趣的朋友也来试试OpenVINO的神经网络加速


简介
NUC12蝰蛇峡谷是intel在12代中定位为enthusiast的主机,体积2.5L,小于绝大多数独显ITX,也是A770M第一次在NUC中出场

蝰蛇峡谷这IO也是完美继承了NUC的特性,非常充裕,正反两面各种接口,雷电、读卡器、2.5G网口,还有HDMI+2DP的视频接口


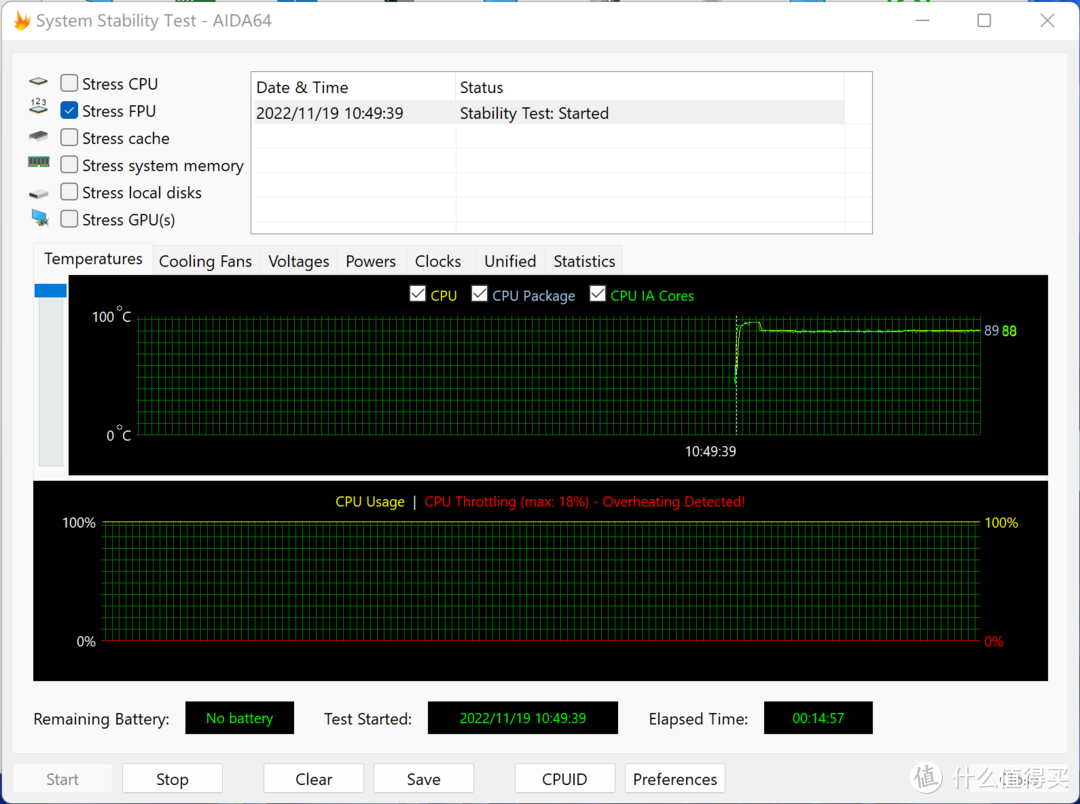
机器的散热也是非常不错的,单烤CPU的时候有80W的持续功耗,性能释放比笔记本要好不少



作为一个定位为enthusiast的PC,蝰蛇峡谷还专门给内置了一张ax1690i的无线网卡,属于第一梯队的WIFI6E网卡

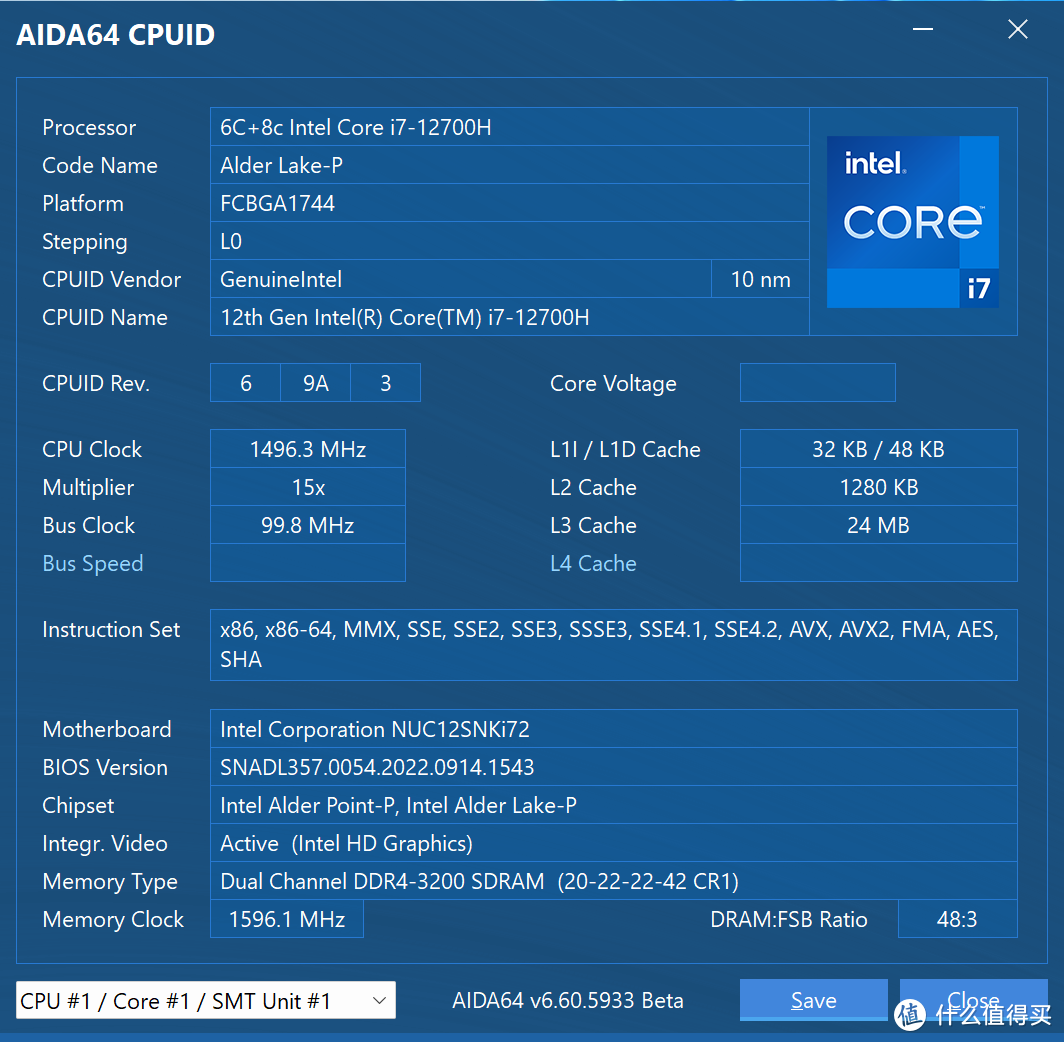
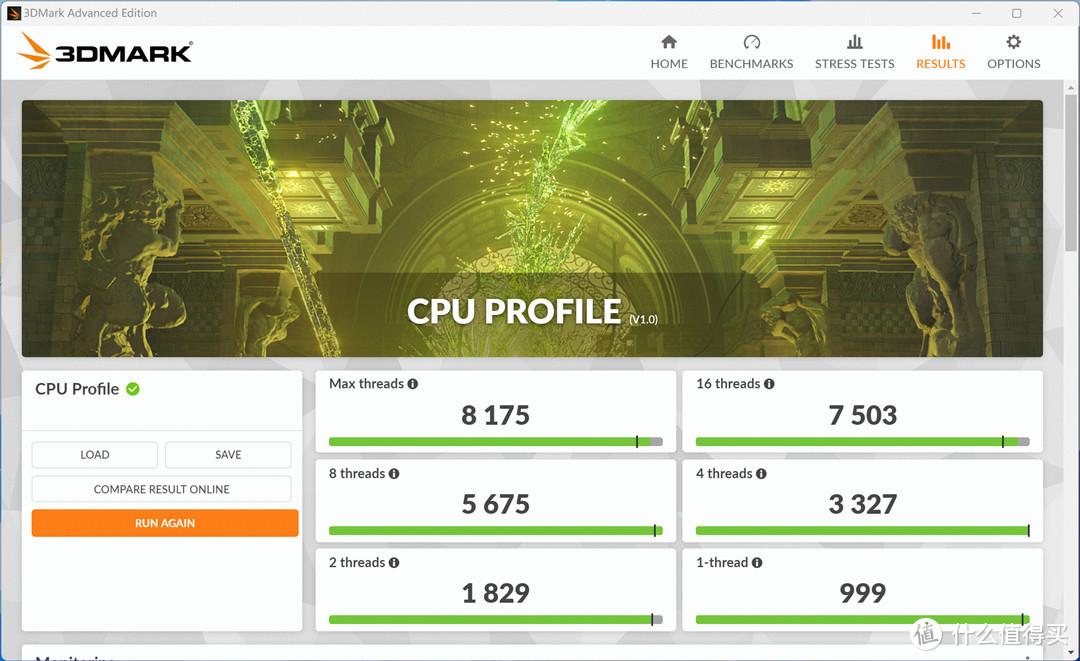
CPUID信息,蝰蛇峡谷推出只有i7 12700H的版本,有可能是NUC12第一次出这个机型的原因,内存仍然是使用的SODIMM的DDR4,在配置成本方面做出了一定的让步
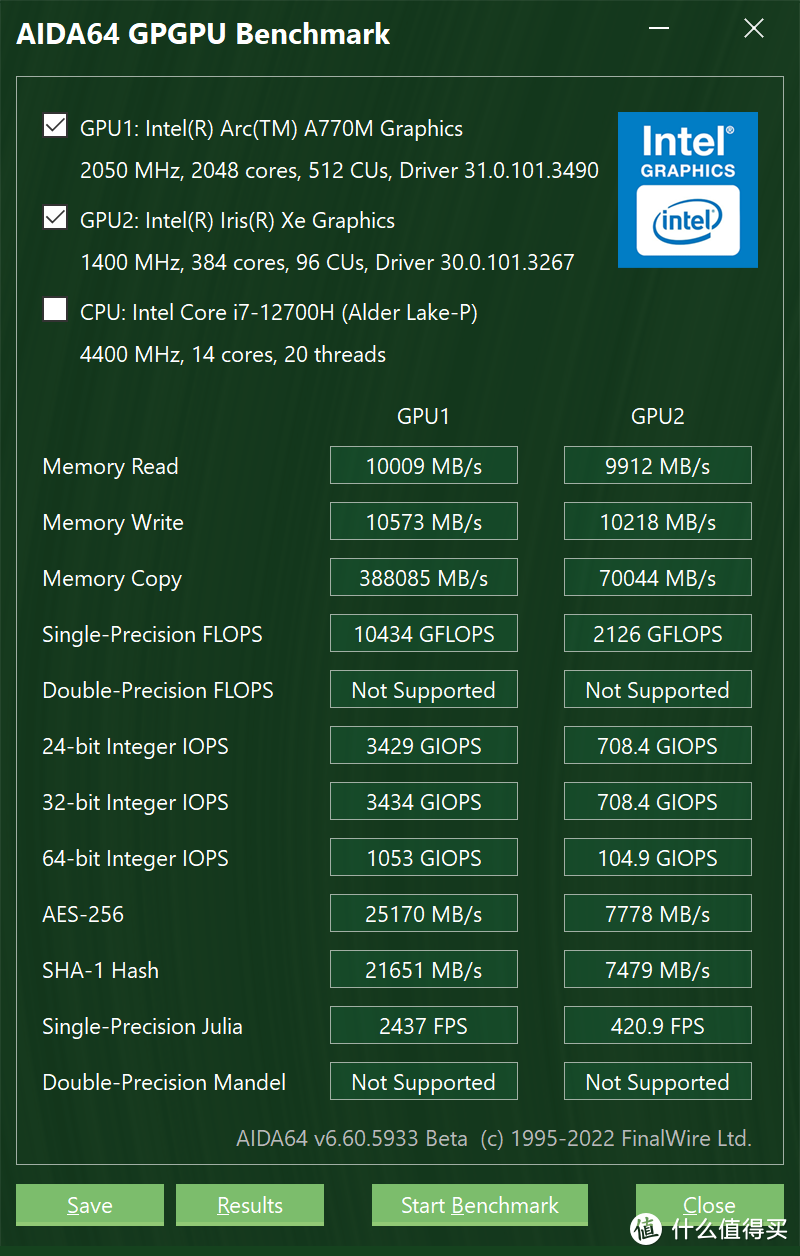
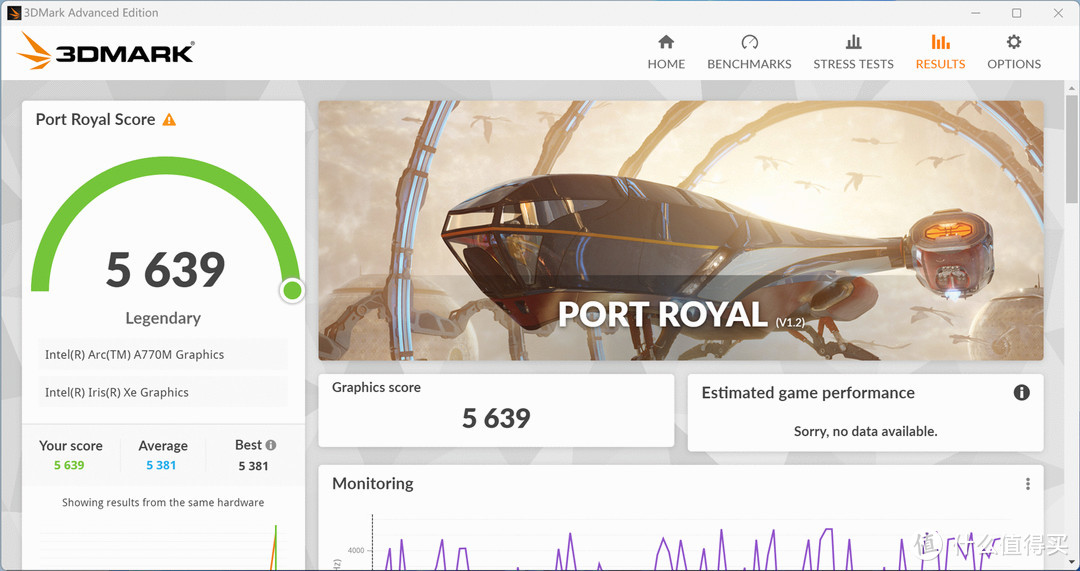
理论性能测试,A770M如果和Xe核显的构架能直接对比的话,那么按照流处理器的组数对比,单精度的比例应该是16/3,和实际测试的结果是相似的
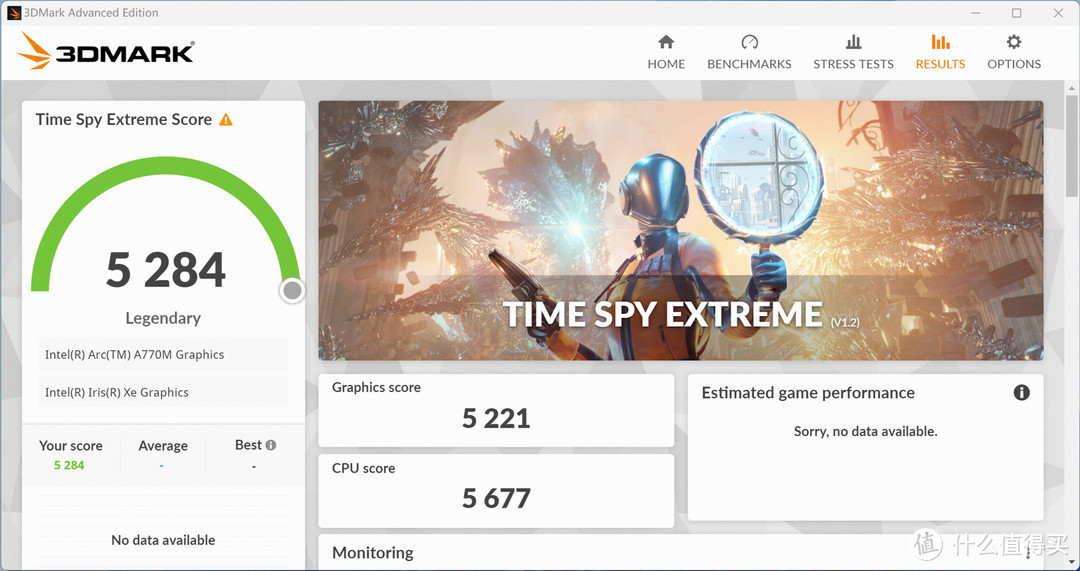
A770M还加入了专门的光追单元,具有不错的光追性能
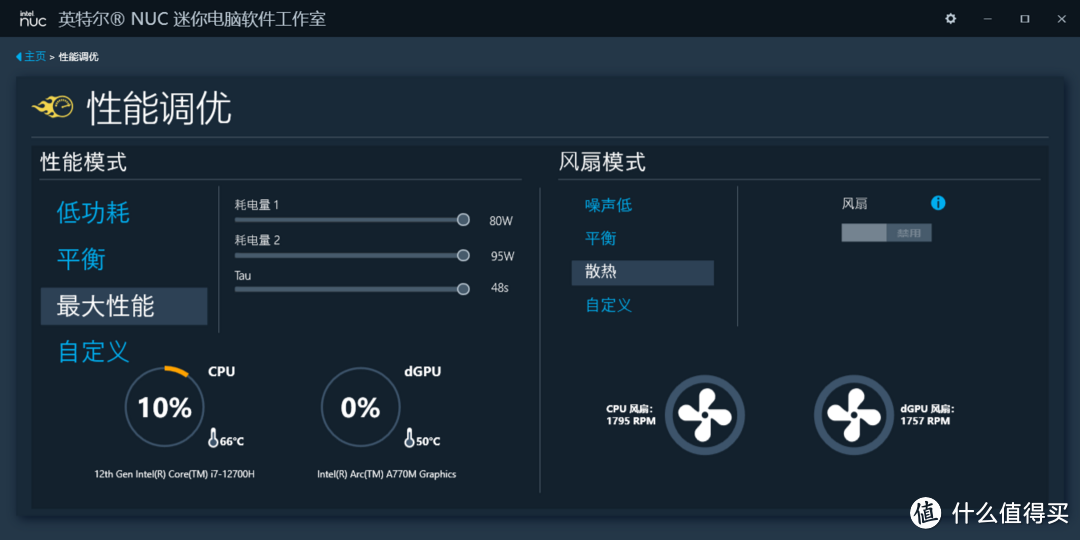
intel还提供了一个NUC software studio,可以用来管理NUC,空间占用小,功能相当完善,灯光和详细的性能调优全都可以通过它控制

OpenVINO搭建
说道深度学习,很多人都觉得是玄之又玄的东西,然而对于很多人来说,无非是针对某种输入输出的线性代数的组合罢了。而就在这其中,会涉及到非常庞大的矩阵乘法运算量,而CPU对这样的简单数值乘法并没有很好的办法并行处理,所以此时显卡或者神经网络加速VPU就登上了舞台,虽然他们每一个流处理器能针对的问题都不能太复杂,但是对于矩阵乘法中的数值乘法来说正好合适,而且在有独立显存的显卡上还能明显降低CPU的IO压力,因此一般在推理神经网络的时候我们都会选择显卡或者VPU
而三家硬件厂商所制定的标准都不尽相同,除了最著名的CUDA之外,AMD的ROCM基本上是本着替代CUDA的目的而设计的,所以能在某些场景中直接替换CUDA。但是intel的OpenVINO则是基本独立的生态,这是因为intel的神经网络加速棒起步很早而且是独立的硬件,而且作为神经网络加速的软件包,它的主要作用集中在推理,而不是训练,这和Nv的某些部署推理卡很像
随着硬件和软件的不断进化,OpenVINO在2022.1的时候也迎来一次大更新,同时也简化了大部分安装流程,目前的OpenVINO已经可以脱离独立安装包,就像cudatoolkit一样直接装入虚拟环境
OpenVINO的安装比较简单,我推荐使用python作为开发语言,因为C++版本的仍然是独立安装包,不如python虚拟环境方便。框架方面随便选择,对应的框架会影响虚拟环境中的支持,选择自己平时用的最多的开发框架就好了
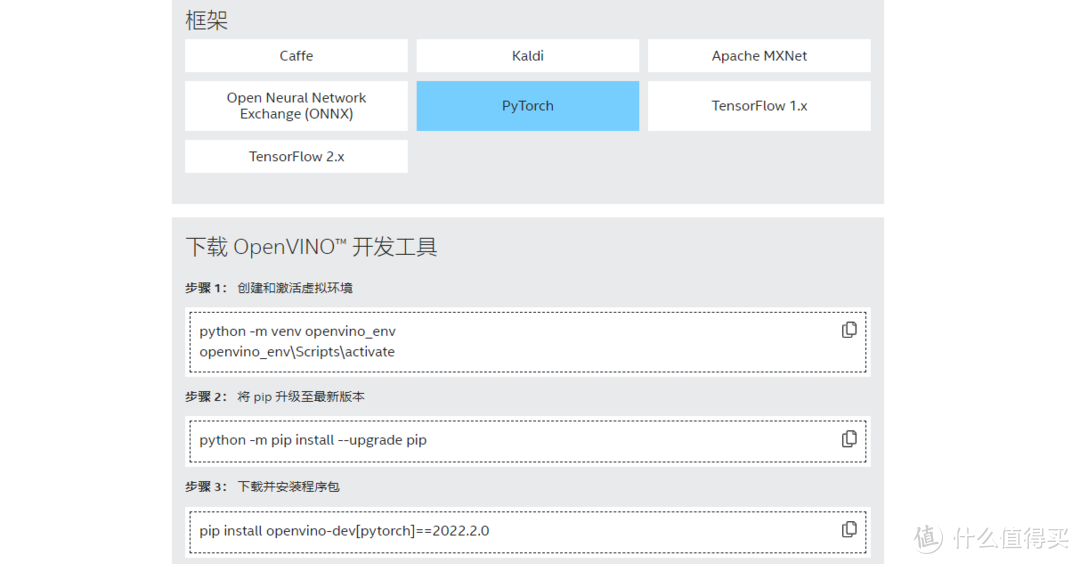
官方教程里面使用的是默认Python作为管理工具,我建议是使用conda作为包管理工具,然后在conda环境里面使用pip安装(确信),并且切换到清华源,这样网速情况会好很多
OpenVINO的Python环境安装确实是三家当中最简单的,如果已经装好了了pycharm和conda的话,就只需要创建一个新环境和一条命令就能安装完成
OpenVINO模型转换+测试
作为一个独立的加速框架,OpenVINO使用的模型是IR模型,而不能直接使用其他框架的模型,因此在推理加速的时候需要对模型提前转化。如果想看比较详细原理的朋友可以直接查阅文档https://docs.openvino.ai/latest/index.html
我这里提供一个比较简明的方法来转化pytorch的模型,基本是按照文档上的方法转化而来的。首先我们看到默认的OpenVINO并没有提供mo的转化pytorch模型的方法,所以我们需要先把pytorch模型转化为onnx模型,然后再转化为一个ir模型
所以我们写一段简单的代码,这段代码就是将一个pytorch模型加载出来,然后用一个dummy模拟它的推理过程,然后用onnx保存这个一个过程。这样保存的模型对任意的torch模型都是适用的,只要我们对他有明确的定义,而且参数是我们想要的,其中的方法onnx都能识别出来。如果需要转换其他框架的模型,也可以在文档中找到对应的方法,我就不过多演示了
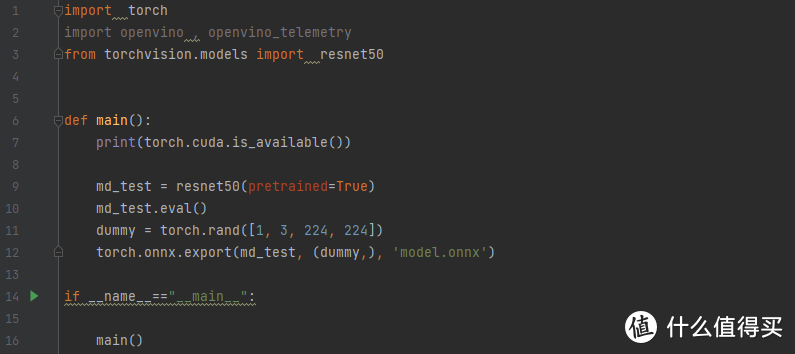
我这一次选用了一个非常常规的ResNet-50模型,采用最新的torchvision预训练参数,这样大家自己如果要对比的话也可以参考。现在这个模型的参数已经被保存到了onnx模型里面,我们可以利用OpenVINO预制的mo方法,把他轻松地转化为ir模型,格式为.xml
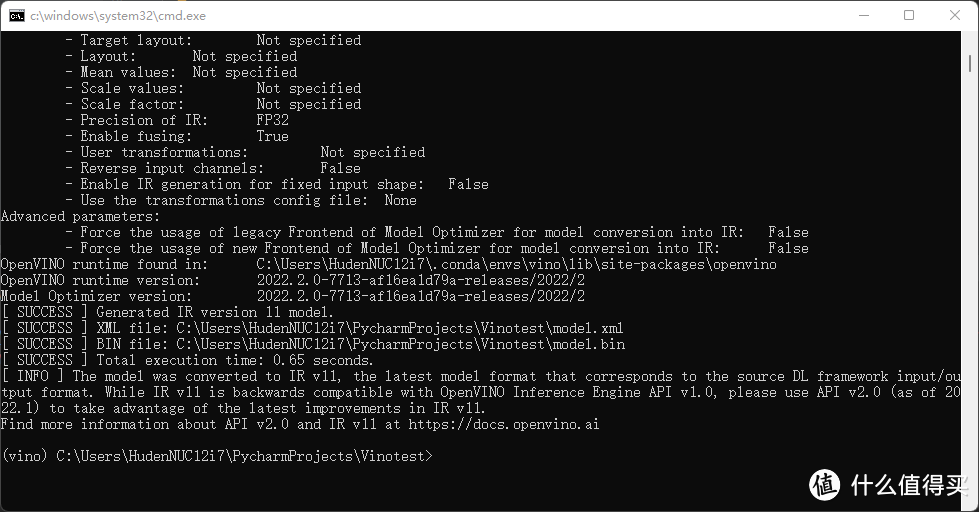
这样一个模型就能使用OpenVINO对他进行推理加速了。OpenVINO内置了一个benchmark方法,能使用一个转化好的IR模型对当前的硬件性能进行测试,这个测试其实就是模拟推理过程,测试在不同情况下的IO和Throughput情况
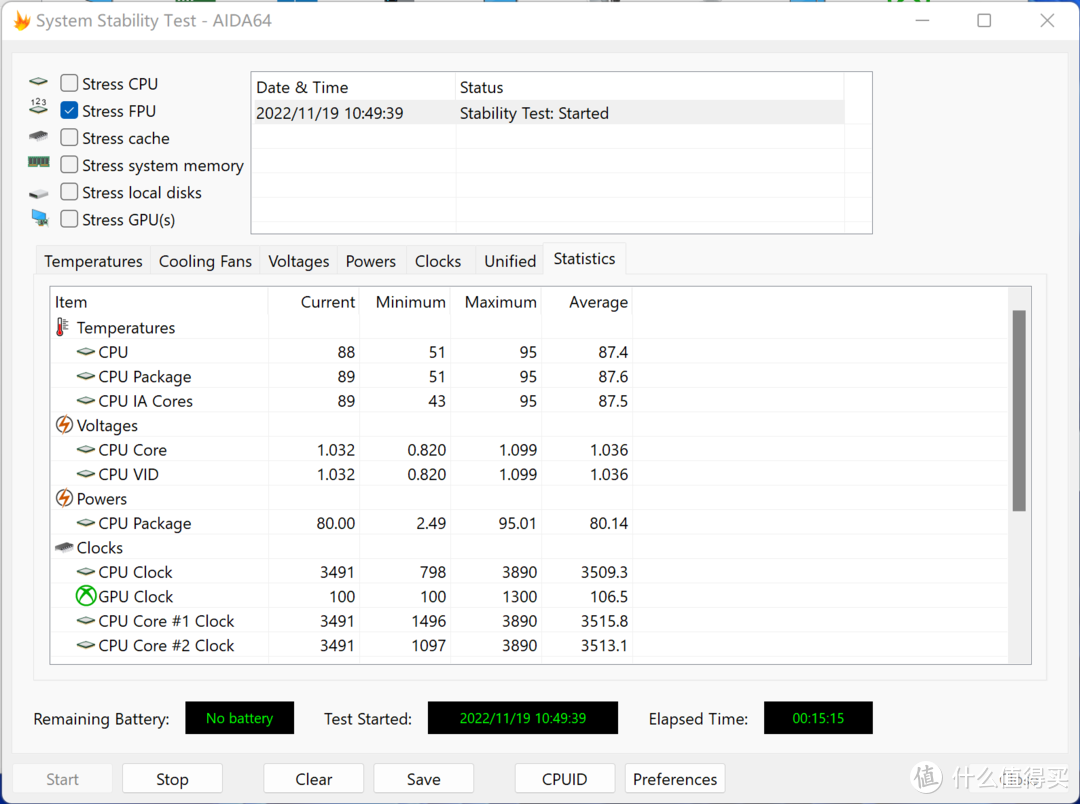
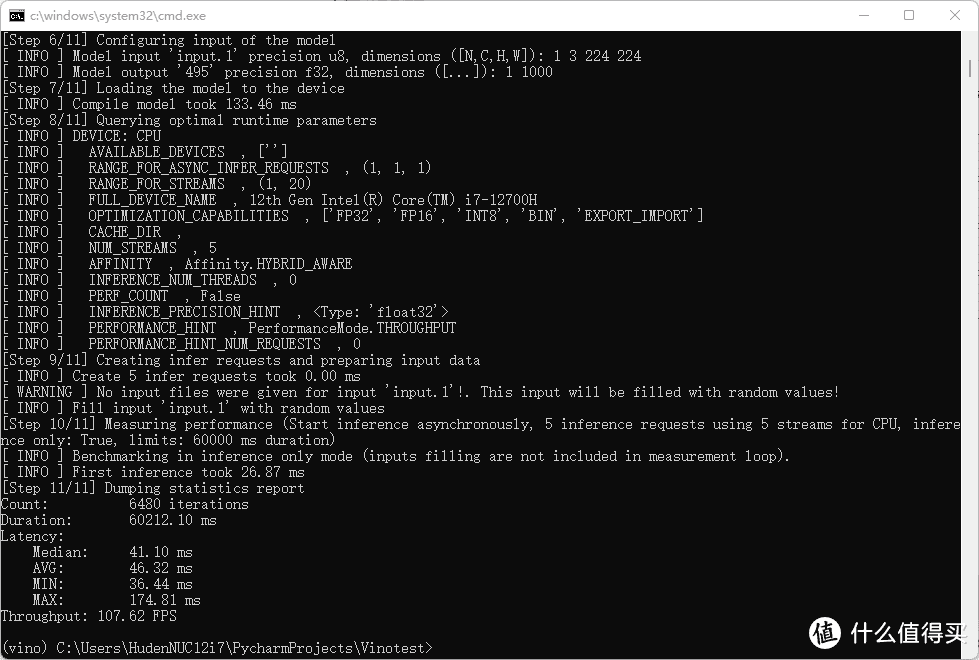
首先来测试一下CPU的性能,可以看到Throughput的大小为107.6FPS,按照定义,OpenVINO加速之后,CPU每秒平均处理了107.6张标准的[1,3,224,224]的resnet50输入。但是我们也需要注意的是,此时的CPU被完全占满,这也是我们在模型部署时最不想看到的情况。因为除了推理,CPU还需要被用于一些其他功能,比如基础的IO和扩展的视觉传感器等等跟数据传入相关的设备
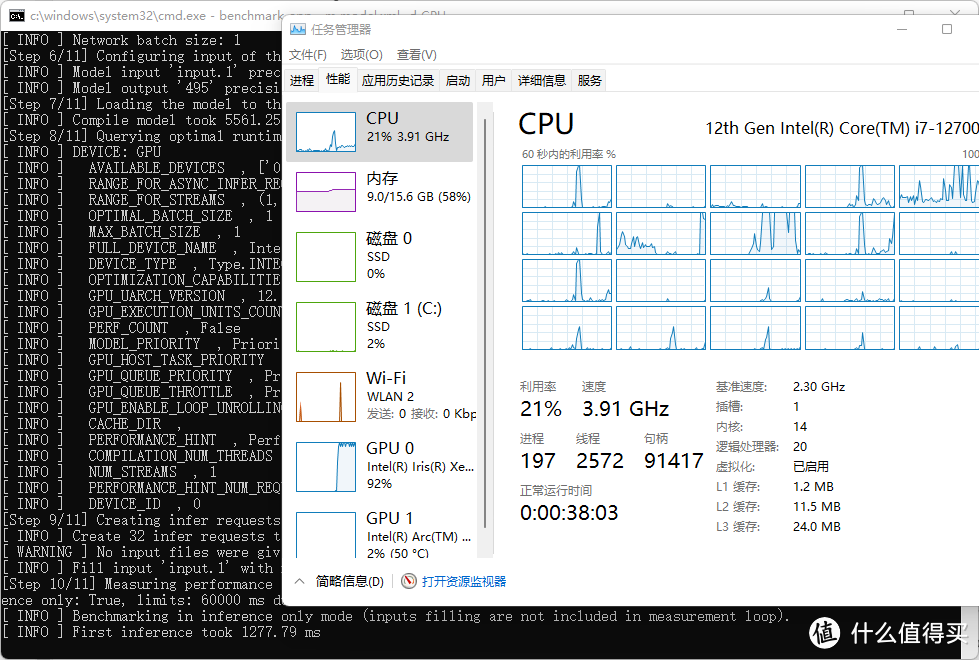
在小打小闹的开发部署当中,最常见的就是一个神经网络加速工具和一个视觉传感器比如intel realsense,然后联合到一起做一个人脸识别或者姿势识别,此时如果直接使用CPU进行推理,那视觉传感器在GUI上的反馈就会产生明显的延迟,使用体验急速下降
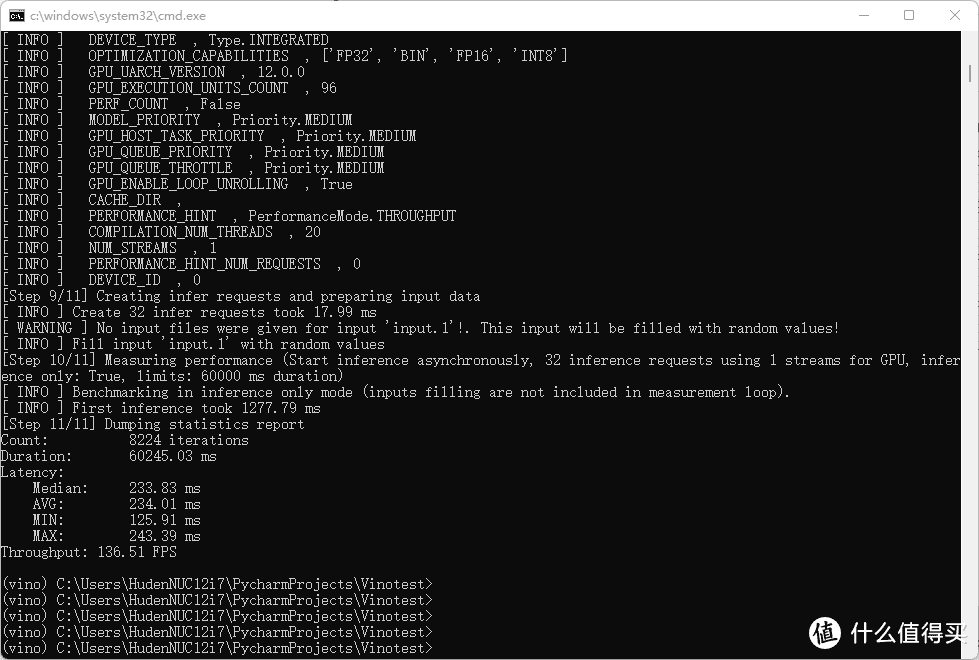
不过如果我们小小的修改一下使用的对象,把加速工具变成Xe核显,那么情况就会大为改观,此时Xe核显被占用满,但是CPU仅仅使用了20%,这些多出的部分就能被分给视觉传感器或者其他功能,不会导致流畅度下降。并且我们可以看到,Xe核显的神经网络推理速度是明显快于CPU的,达到了136FPS,而功耗远远低于纯CPU推理,也可以证明GPU加速的重要性
如果手中有一个intel 12代core的笔记本,那么刚才提到的CPU+Xe核显加速推理也是可以轻松实现的。而我们现在手中可是有intel最新科技Arc A770M显卡!如果使用独立显卡进行加速,那么速度会再上一个台阶
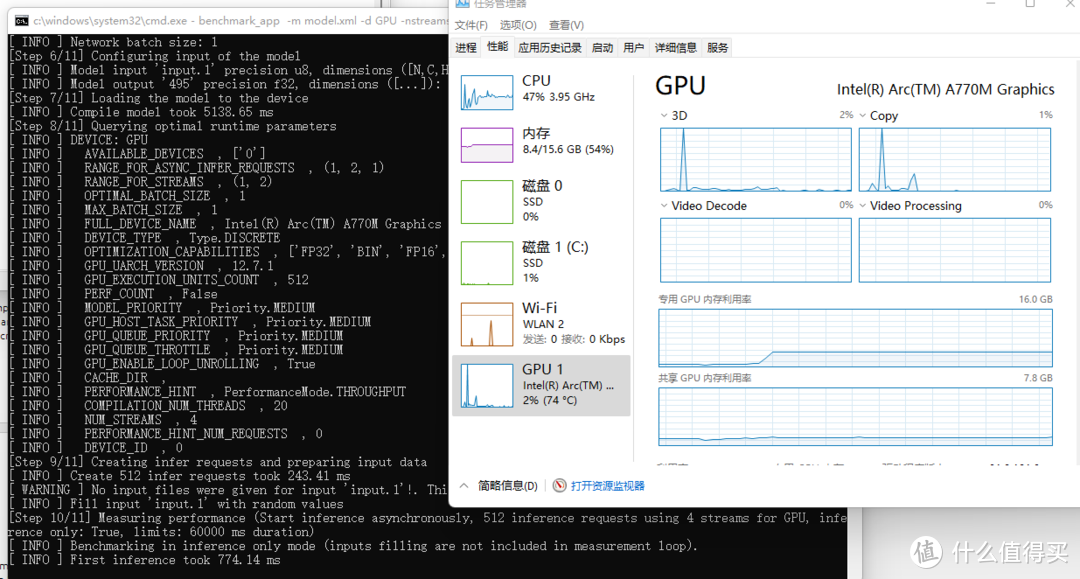
屏蔽Xe核显,然后直接使用A770M作为单独的神经网络加速工具,我们可以看到此时A770M的性能监测基本没有什么起伏,而显存占用能说明模型确实是导入了显卡当中,这和一般的显卡推理过程的性能需求时比较相似的。A770M的测试结果达到了828.7FPS,这个Throughput的性能明显远超CPU+Xe核显的总和,而且按照单精度浮点的量来计算,A770M仍然高于Xe核显的16/3倍,也说明A770M在神经网络加速方面应该是经过了单独优化的
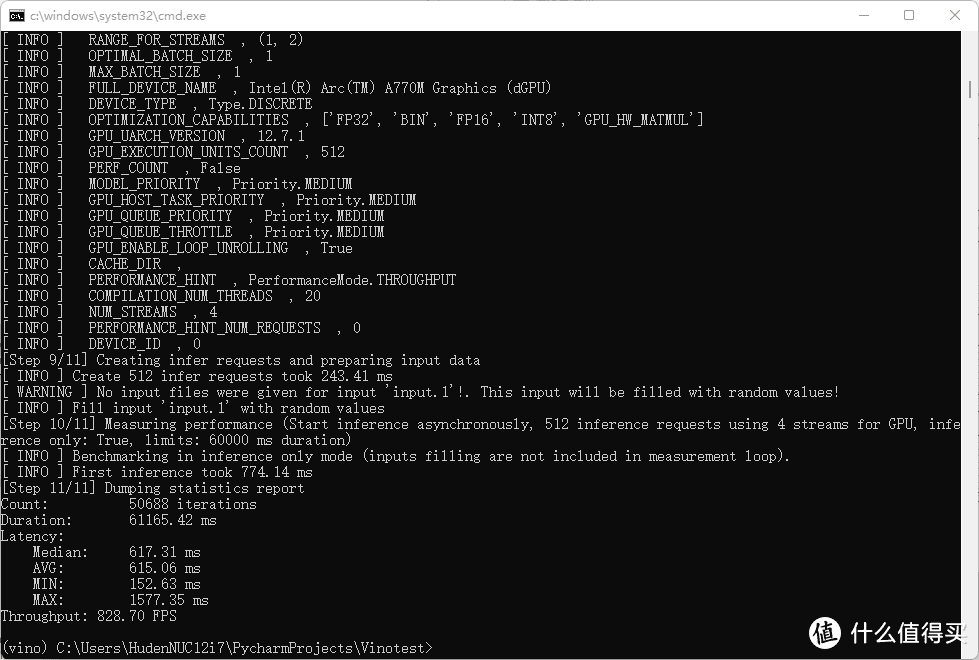
之后又测试了一下小batchsize快速响应的throughput,成绩仍然超过了754FPS,有这个推理速度一般来说判别模型是完全没有问题的,即使模型的flops需求量增大,或者参数量膨胀,A770M的性能和显存应该都能轻松撑住这一类需求
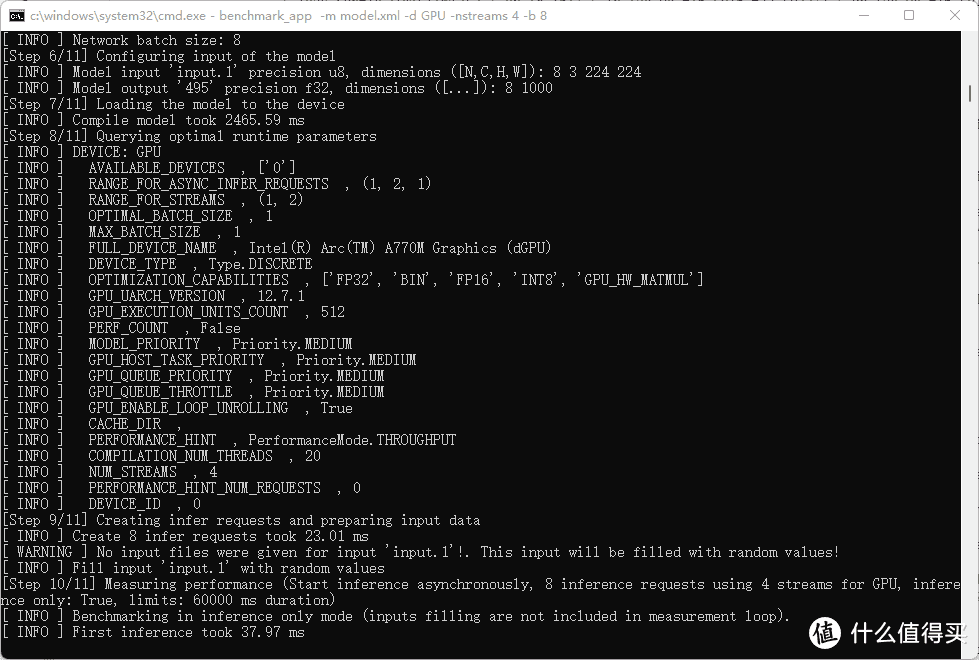
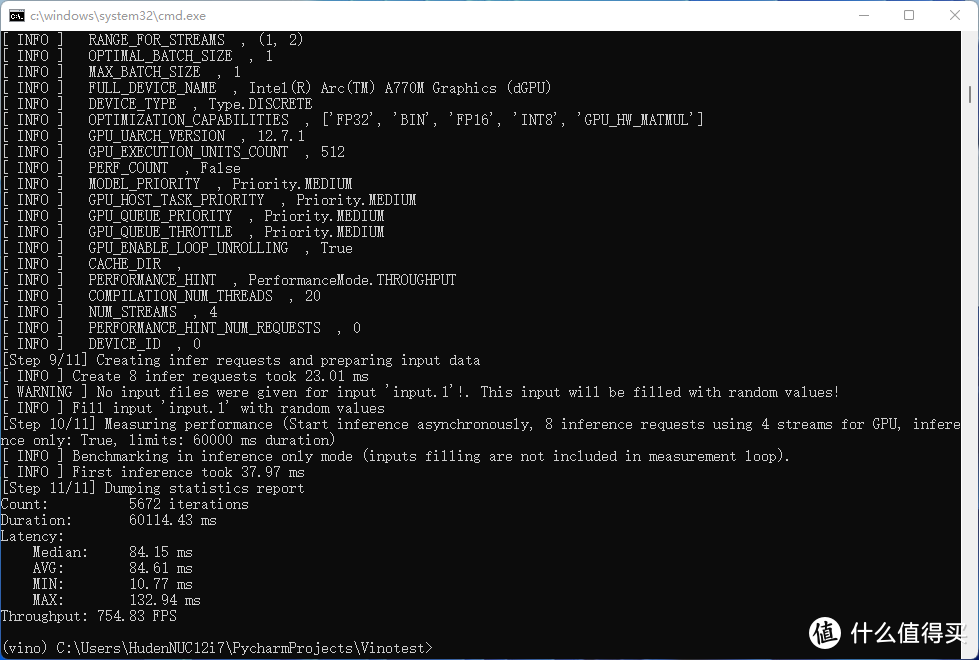
关于视频编辑与渲染
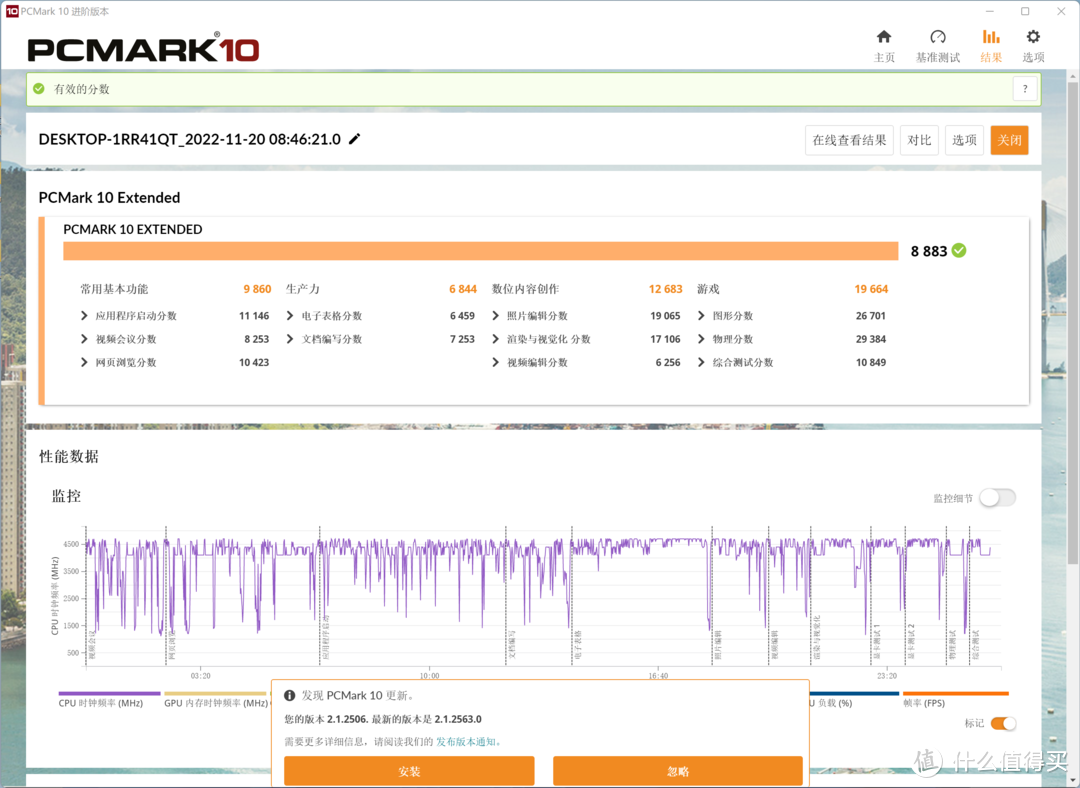
除了深度学习推理之外,蝰蛇峡谷还有非常生产力的功能就是A770M的编码解码功能。在PCMark10的测试小分中就能看出来,虽然办公软件和上网的得分和一般的12代笔记本没差啥,但是在视频+渲染和照片编辑这块得分直接飞天,差点有办公软件得分两倍高
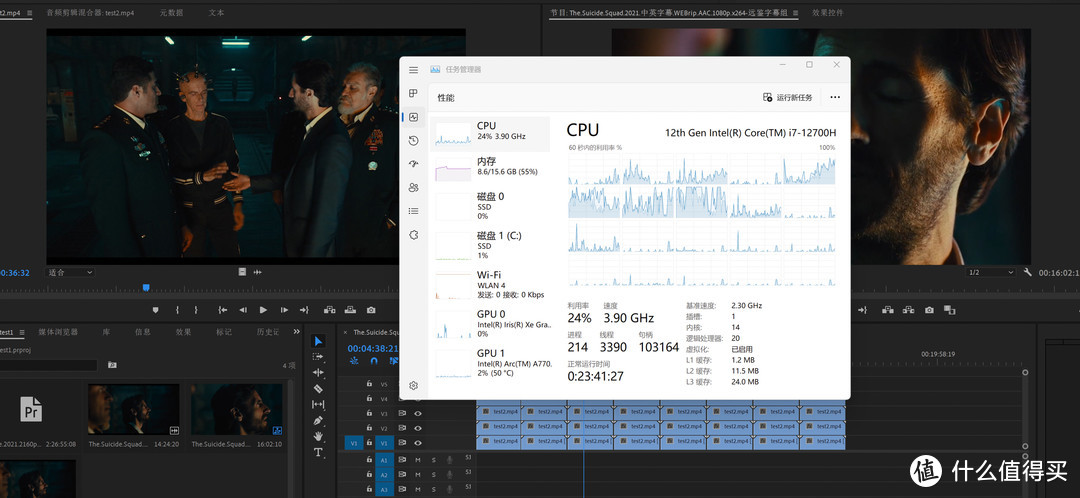
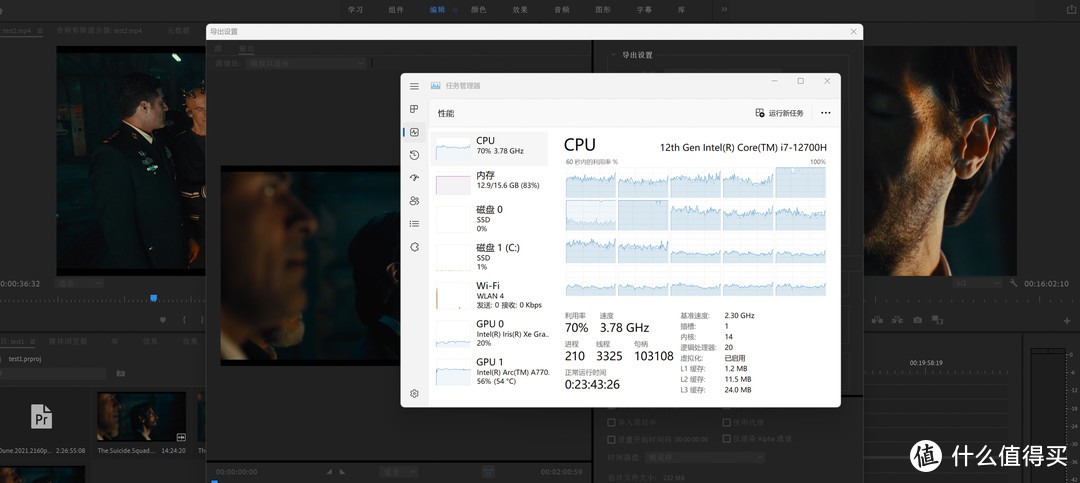
最常见的视频编辑应用就是Pr,用A770M加速之后能明显加快导出时间,10min的视频总共花了55min,而且即时回放完全不会有卡顿。还有一个挺有吸引力的feature是A770M的AV1解码支持,这是目前最新的视频编解码格式
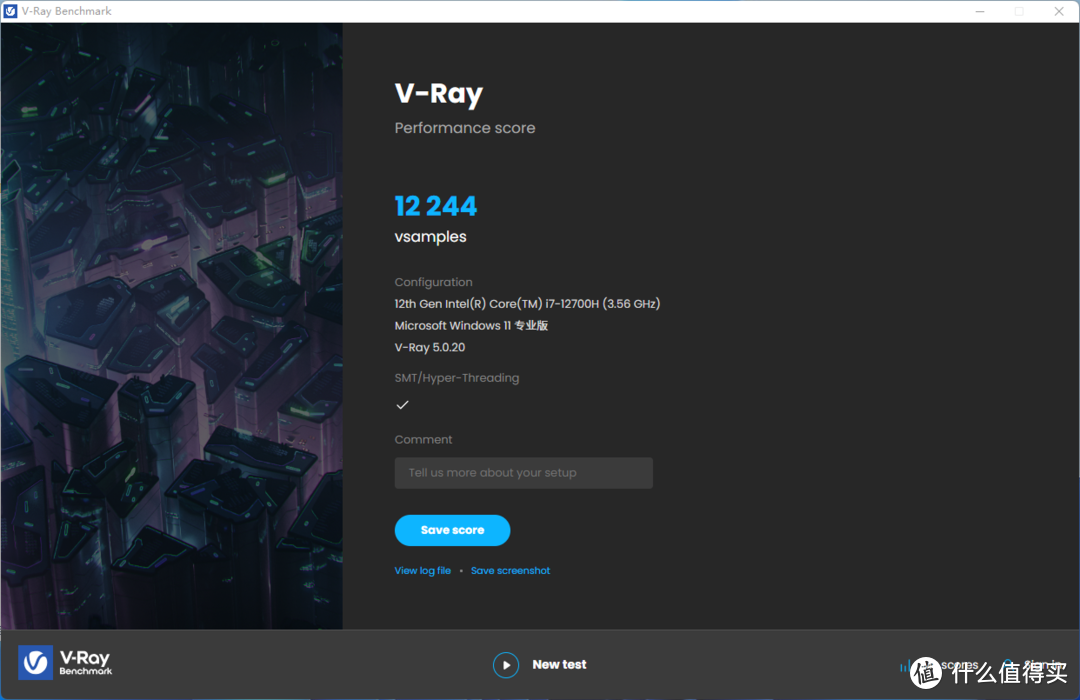
Vray渲染测试,相对而言更封闭一些,所以蝰蛇峡谷只有纯CPU的测试结果
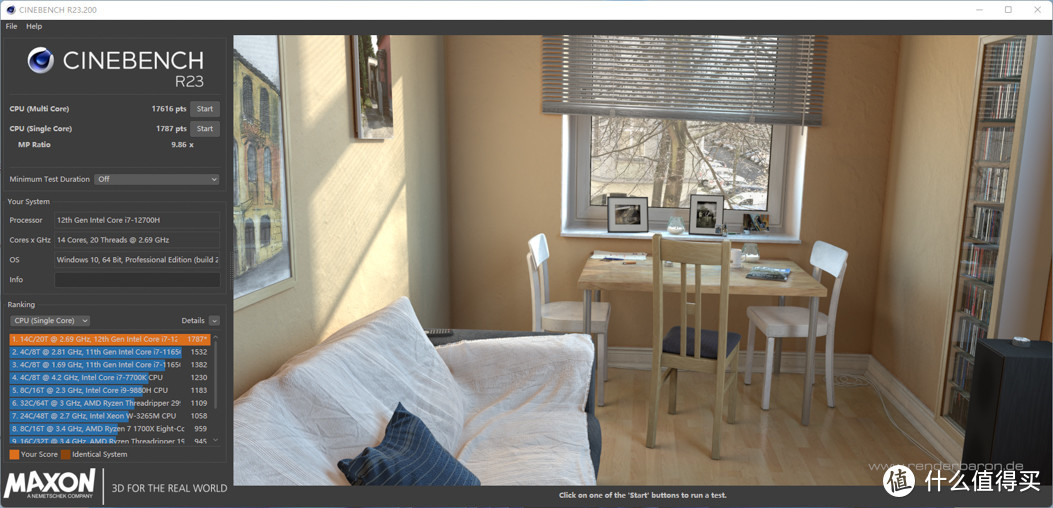
cinebenchR20和R23其实就是cinema4D渲染器的测试工具之中的两个,不管是单核还是多核,蝰蛇峡谷的的得分都还不错

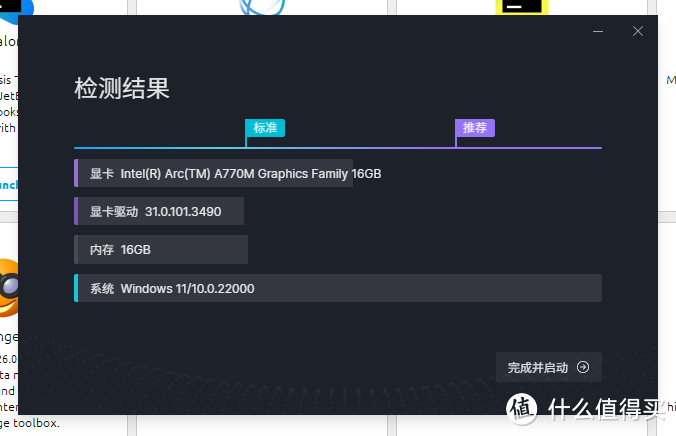
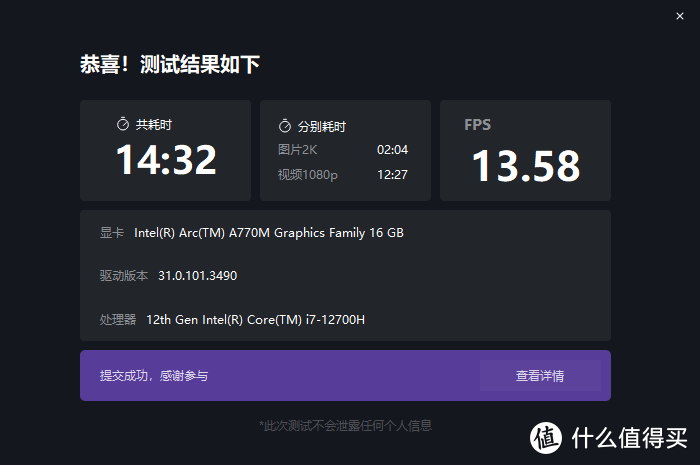
还有一个测试是D5渲染器,也是非常常见的渲染工具,自带的检测工具对A770M的评价是推荐等级以上,在测试中表现称得上还行,耗时14.5min,帧数13.58FPS,跟桌面的A770差别不是很大,不过感觉还是有不小的优化空间
总结
关于OpenVINO,如果目的只是玩一玩深度学习模型,个人感觉OpenVINO确实非常便捷,只需要一个单独的虚拟环境和一行代码就能轻松安装,并且在WIN上也能轻松适配。OpenVINO的优势其实也包含他本身作为一个部署非常简单的推理加速框架,又能完美适配蝰蛇峡谷这个纯intel CPU +iGPU+GPU平台。很多场景下我们说到深度学习都会理解为模型训练,但实际上在部署中推理的性能需求远低于训练过程,OpenVINO配合A770M正好能把这张独显的推理性能发挥完善,成为具有推理优势的平台,这种情况下蝰蛇峡谷就不仅能作为一个生产力工具,而且能作为一个具有相当扩展性的深度学习部署终端,蝰蛇峡谷本身的IO优势在此时也能比较好的显现出来。要是能把NovelAI的生成模型转换成IR结构的,说不定还能见到蝰蛇上部署的AI绘画生成器!在OpenVINO 2022.2开始,这个框架的backward能力也得到了相当大的优化,所以也算是一个比较强的IR模型训练框架了
不过OpenVINO毕竟不能直接使用其他深度学习框架的模型,到IR模型的转换始终会给使用上带来一些麻烦,如果intel在独显完全铺开之后做一个类似于CUDA或者ROCM这类能直接和tf或者torch结合使用的计算构架,那就能让Arc独显的深度学习通用性再上一个台阶。届时蝰蛇峡谷这个规模的NUC,就正好能作为深度学习/视频创作生产力平台,更具吸引力
最后送上一张图,谢谢大家

作者声明本文无利益相关,欢迎值友理性交流,和谐讨论~

















杀价党
校验提示文案
值友3099443479
校验提示文案
糙汉子
校验提示文案
jinsongtry
校验提示文案
值友9264073490
校验提示文案
值友3099443479
校验提示文案
CN171
校验提示文案
值友6518606525
校验提示文案
KEVINVINES
校验提示文案
KEVINVINES
校验提示文案
值友6518606525
校验提示文案
CN171
校验提示文案
值友3099443479
校验提示文案
值友3099443479
校验提示文案
值友9264073490
校验提示文案
糙汉子
校验提示文案
jinsongtry
校验提示文案
杀价党
校验提示文案