





























































158
30
今天你分类了吗?看看人家机器怎么分类
2019-12-19 13:47:24
3点赞
3收藏
0评论
最近几个月来,魔都的垃圾分类搞得不少人有点焦虑。

不过你大概不知道,比起机器学习系统,你分类垃圾那点工作量简直弱爆了——因为这个世界上能够用机器学习来解决的问题,大部分都属于分类问题(另一类是回归分析,我们以后讲)。比如人脸识别、指纹识别、推荐系统、语音输入等等。这堂课我们就来讲讲机器学习是怎么干分类这件事儿的。
首先,什么叫做分类呢?
说得简单点就是向机器提出那么些问题:图片上的这个人是谁?(张三?李四?隔壁老王?苍老师?)这些笔画是个什么字?(大?太?天?夫?)这位用户可能对哪件商品感兴趣?(VR眼镜?保温杯?海贼王手办?蜜蜡手串?)

对于机器学习的系统来说,这样的问题,其实就是一个输入,这个输入可能是一张照片、一个手写的中文字的图像、一个网站用户的个人信息等等。而机器学习的程序所要做的,是根据这个输入,经过一定的计算和判断,给你一个输出。这个输出就是一个标签,告诉你这个输入应当归到到哪一类,比如这个人是“隔壁老王”、这个字是“天”,或者这位用户可能会买“保温杯”。
那么,机器怎么那么聪明,知道某个输入应该怎么分类呢?
别误会,机器其实一点不聪明,它甚至压根就不知道自己在干嘛。不论你给它的输入是一个字、一条狗,还是一张易烊千玺的照片,对它而言都没什么区别。程序只不过是根据自己先前对许多的学习样本所进行大量的训练,计算出你所给的输入和哪一类样本最相似而已。

由于分类的任务属于有监督学习的过程(参见本系列第二讲——连机器都在学习,你还不赶紧学一下?),程序能给出的答案必定是先前学习过的,所以任何能够分类的机器学习系统绝不可能回答出一个它以前从没见过的类型。
举个例子,你之前给程序学习过猫、狗和猪三种动物的照片,并告诉程序这些照片里的是猫,那些照片里的是狗,另外那些照片里的是猪。接下来你拿出一张牛的照片问它这是啥?它绝不可能告诉你这是牛,因为它压根不知道这个世界上还有牛这样一类东西的存在。所以程序的回答只可能是猫、狗或者猪,具体看它认为照片上的这头“牛”长得更像谁。你再换成一张橘子的照片或者你自己的美颜自拍照,结果还是一样的,只能是猫、狗或者猪。
它甚至不会告诉你“我不认识这个是啥”,因为在程序看来,一张照片不是更像猫,就是更像狗,要不就是更像猪,而没有“都不像”的事情。哪怕看到的是仙女,它也总能针对猫、狗和猪计算出一个相似度,然后把相似度最高的那个作为答案给你。

那么,如果要这个程序还能认识牛怎么办?也不难,只要再给它学习一些牛的照片,并且告诉它这是牛,就行了。总而言之,你想要机器认得多少种东西,就得让它学习多少种东西。指望机器举一反三,发挥主观能动性?不存在的。 那么接下来,问题又来了。为什么程序学习了一些样本之后,就知道该怎么分类了呢?它又不长眼睛,凭啥学习过许多阿猫阿狗阿猪的图片之后,给它一张狗的照片,它能知道这东西更像狗(理想情况下),而不是更像猪呢?换句话说,程序是怎么通过学习增加经验的?

同学,你这个问题问得很好,抓住了我们这堂课的重点,简直是灵魂拷问。这堂课中,我们接下来的任务就是搞清楚这个问题。
分类程序是怎么学习的?
事实上任何电脑程序,不管起了个多么高大上的名字,都只能处理数字。所以这些用来做分类工作的机器学习程序,也只认得0和1。它们所做的事情,只不过是在一堆0和1的输入和输出之间建立起某种对应关系罢了。
为了让人更容易理解,我们假设一个简单而又复杂的分类问题——判断一下宅男能不能成功约到女神吃晚饭。
为什么说这个问题简单,因为我们的目标答案,或者说类别只有两类1 = 女神接受邀请,约会成功;0 = 女神拒绝邀请,约会失败。

为什么又说复杂呢?因为现实生活中影响这个答案的因素实在太多了,不要说电脑,就算是最聪明的人脑,也很难判断。不过没关系,为了教学上的方便,我们来极大的简化一下问题,假设女神是否接受邀请只和以下五个因素有关(我们把这些因素用f1到f5来编号):
f1 = 女神的颜值,从1到10的正数;
f2 = 宅男的颜值,从1到10的正数;
f3 = 当天是星期几,从1到7的正整数;
f4 = 当天的天气,只能是1到5中间的一个整数,假设1 = 晴天,2 = 阴天,3 = 下雨,4 = 下雪, 5 = 其他。
f5 = 目标餐厅的人均消费,以人民币计算,可以是任意正数;
这样一来,f1到f5这五个数就是我们这个约会成败预测系统的输入,而0或1就是输出。如果用数学语言来描述,可以说系统的输入[f1, f2, f3, f4, f5]是5维向量空间中的一个向量。这句话仅供参考,看看就好,能背下来更好,可以留着和朋友聊天的时候用……

你看,本来约会女神是一件很复杂的事情,看似包含了千头万绪,但我们把它简单的归结到了这五个影响因素。为什么需要这样做呢,因为计算机没有人类那么聪明,不能从这些千头万绪中排除那些对结果没有影响的东西,所以需要我们来帮它把这件事情做了。这件保留对分类结果有影响的因素,而去除没有影响的因素的工作叫做特征提取(feature extraction)。
特征提取是分类之前的一个重要步骤,特征提取得合不合适,完不完整直接影响到分类能不能有准确的结果。比如,如果你把今天的股票价格也放到我们这个约会成败预测系统的输入里面,这个毫不相干的特征就会对判断结果造成干扰。反过来,如果你漏掉了今天天气这个重要的特征,那么判断结果也不会太准确,因为女神答不答应晚上出来赴约显然和天气情况有很大关系。

再举个人脸识别的例子,你肯定不会因为你爸爸戴了一副眼镜、把头发剪短了,或者吐了一下舌头就把他错认成隔壁老王,因为这些变化对你判断一个人是谁不会有什么影响。但从一张照片的像素级别来看,这种变化会改变画面上的很多像素,让照片和原来产生很大的区别。如果你直接把照片交给分类系统去学习,那么这种变化就很容易对程序产生误导,影响学习效果。
反过来,像两个眼珠之间的距离、鼻子的长度占整个头长的比例、嘴巴的宽度这样的因素,才是真正影响判断结果的特征。所以特征提取的工作就需要对照片先进行一些处理,从里面把这些有用的特征计算出来,并把它们(而不是原始的图片)作为输入的样本去训练分类系统。

特征提取完成之后,我们就定义好了这个分类系统的输入和输出,接下来就能够让它开始训练了。训练的方法也很简单,(假设)我们可以找出过去几年中许多宅男约女神出去吃晚饭的记录,每条记录都包含了约会双方的颜值打分、当天是星期几、天气情况和餐厅的平均消费(就是输入f1..f5),以及该约会是否成功(期望输出,0或1)。学习样本数据大概是长这个样子(为了便于管理,一般会给每条样本一个编号):
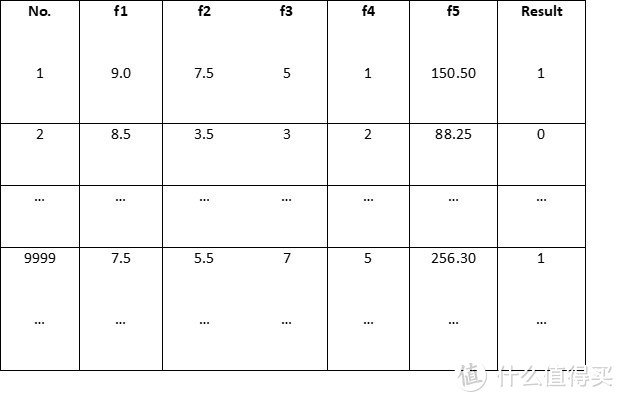
就是把这些样本(包括输入和期望输出)都扔到分类系统中去。分类系统会想法“记住”每条样本里面所包含的信息。具体怎么记,不同的模型有不同的过程。某些模型,比如最近邻(NN)或者k-近邻(k-NN)法,会直接把每条样本保存在一个的数据库里,而另外一些模型,比如人工神经网络(ANN),会通过不断调整内部的一些参数来隐含地保存样本的信息。具体某种模型怎么做,我们以后会专门讲。
嗯,你说很好,把这些学习样本都过一遍,学习就结束了吗?
那可不一定。对于有些模型(比如最近邻、k-近邻)来说,确实这样就完成了。但对于复杂一些的模型,比如神经网络,学习一遍是不够的。就好像你家娃背课文或者做数学题,除非天生骨骼清奇,否则也不是看一遍书就能搞定的对吧?

对于复杂的模型的训练,一般会有一个交叉验证(Cross Validation)的步骤。什么是交叉验证呢?就是把所有的学习样本分成两部分,大部分(比如80%或90%)用来训练,剩下的(10%到20%)用来测试训练成果。测试的方法是只给系统输入值(f1…f5),让它给出分类结果,再和已知的正确结果作比较,看看它是不是答对了。这就好像教娃做数学题,十道题里面给他讲解八道,剩下两道做测验,看看他是不是真懂了。这个交叉验证的过程会进行好几轮,每次选取不同的学习样本来做训练和测试,直到平均的准确率达到某个期望的水平为止。
到这一步,学习的过程就完成了,可以进入实际应用阶段。毕竟机器学习的目的是对未知的结果进行预测,我们不能总是停留在历史里。

假如某位宅男今天想要向心目中的女神发出共进晚餐的邀约,就可以把双方的颜值、星期几和当日的天气,以及目标餐厅的人均消费这五个数值输入系统,而系统可以根据已经学习过的历史数据,经过计算给出一个预测(0或者1),告诉宅男今天的邀约能不能成功。
有些系统还有收集反馈的功能,让宅男在事后告诉程序今天到底有没有成功约上女神,并把这个结果连同之前宅男给的输入参数一起作为一个新的学习样本,再训练一次。这种训练称为在线训练(online training)。

拥有在线训练功能的学习系统,可以在使用过程中不断通过新的训练样本来提升自己的能力,变得越来越聪明。
这堂课上的差不多了,你现在应该可以回答下面的问题:
什么是分类问题
机器学习系统怎么处理分类问题
什么是特征提取
什么是交叉验证,以及
怎么才能成功约会女神。
小编注:本文作者@ imeasy 是什么值得买生活家,他的个人自媒体信息为:
微信公众号:逸飞影话 ,微信搜索“YifeiPic”
扶持推广个人品牌是生活家新增福利,更多详细内容请了解生活家页面(https://zhiyou.smzdm.com/author/)。欢迎大家踊跃申请生活家,生活家中表现优异的用户还将有机会成为『首席生活家』,欢迎有着特别生活经验的值友们踊跃加入生活家大家庭!
















