




























































































348
364
天玑 9300 工程机实测:全大核压榨,性能极限在哪里?
2023-11-12 07:42:12
1点赞
2收藏
2评论
每到年底,地表最强的两家移动芯片商总会先后推出它们旗舰 SoC,来决定下一年旗舰手机市场的趋势;今年高通先行了一步,发布了骁龙 8 Gen 3,前段时间的量产机我们也测了,没看的可以待会去回顾一下。不过,昨天联发科的这场发布会,天玑 9300,我觉得它有可能会影响 Android 手机旗舰芯片后几年的发展路线。

我们又在第一时间拿到了天玑 9300 的演示工程机,不过,在给大家摸个底之前,我们先来看一下这次天玑 9300 的配置。

这次天玑 9300 用了台积电第三代的 4nm 制程工艺,一共 227 亿个晶体管,除了 CPU、GPU、APU 这些大部头的更新,还首发了对 9600Mbps LPDDR5T 运存芯片的支持。

还有新的图像 ISP,支持 16 层语义分割优化、集成了光学防抖专核;
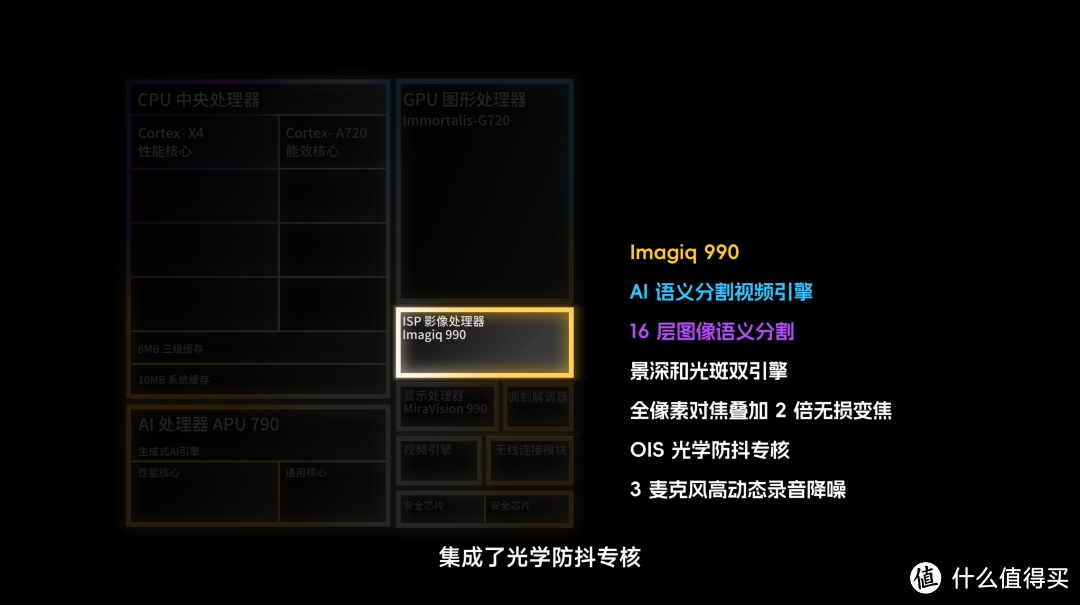
Modem 的部分,支持 6.5Gbps 的 Wi-Fi 7、提高了穿墙力,支持 5G 的 Sub-6GHz 的四载波聚合;

新的显示处理器做了 AI 的画质优化;还加入了两枚安全处理器。
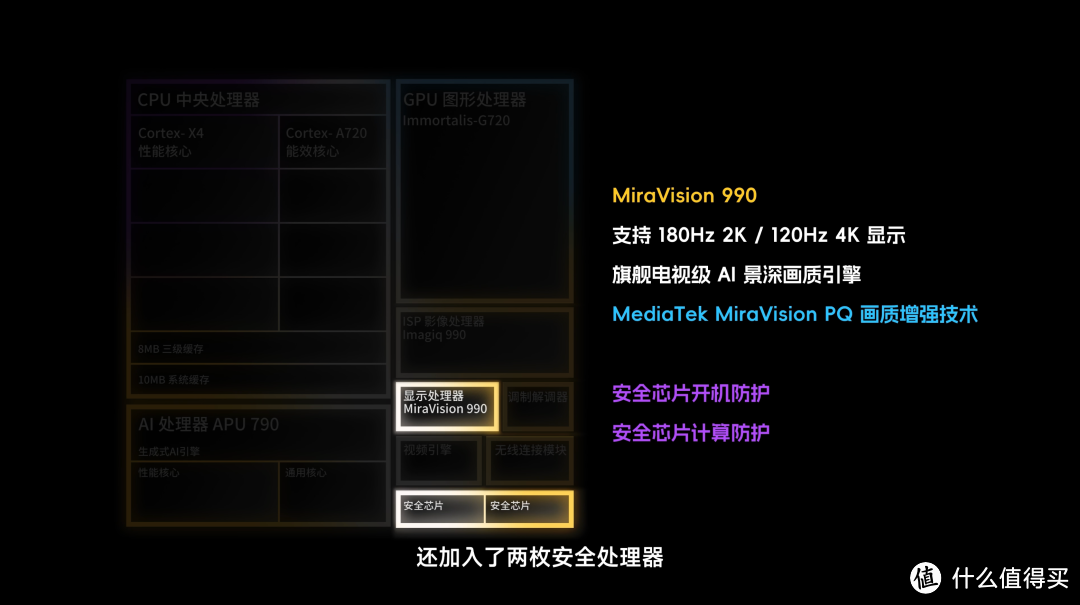
| 全大核架构
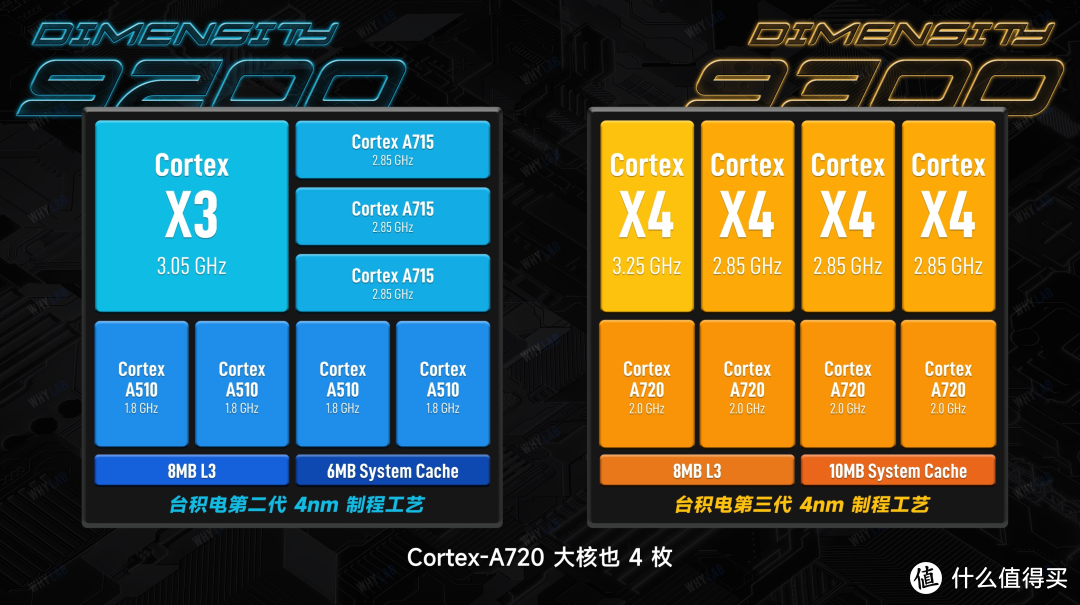
意料之中,天玑 9300 今年也不再支持 32 位应用了,甩掉了 32 位的包袱之后,也直接抛弃了小核的配置,全面转向了高性能核心,也就是联发科这次说的「全大核架构」。

据说这次的新架构其实从前年天玑 9000 的时候在内部就开始部署了,相比起友商今年的「减小加大」路线,天玑 9300 直接「去小加大加特大」,从上一代 1+3+4 的架构直接跃升到 4+4 的架构,Corte-X4 超大核 4 枚,最高 3.25GHz;Corte-A720 大核也 4 枚,频率 2.0GHz;缓存方面,三级缓存来到了 8MB、系统缓存 10MB。
这样做提升最直接的就是性能了 —— 对比上一代,天玑 9300 CPU 同能耗下有 15% 性能提升,我们用 GeekBench 对这台工程样机的 CPU 摸了个底。

对比去年我们测的天玑 9200 工程样机的话,峰值性能提升肯定不止是 15%,单核性能提升了 50%+,多核甚至提升了接近 70%,规模还是很可观的。

对比刚测不久的小米 14 系列,单核小胜,多核性能的规模更有优势;和 iPhone 15 Pro Max 比的话,多核性能更有优势。还有娱乐兔,V10 的版本,来到 213 万分了。

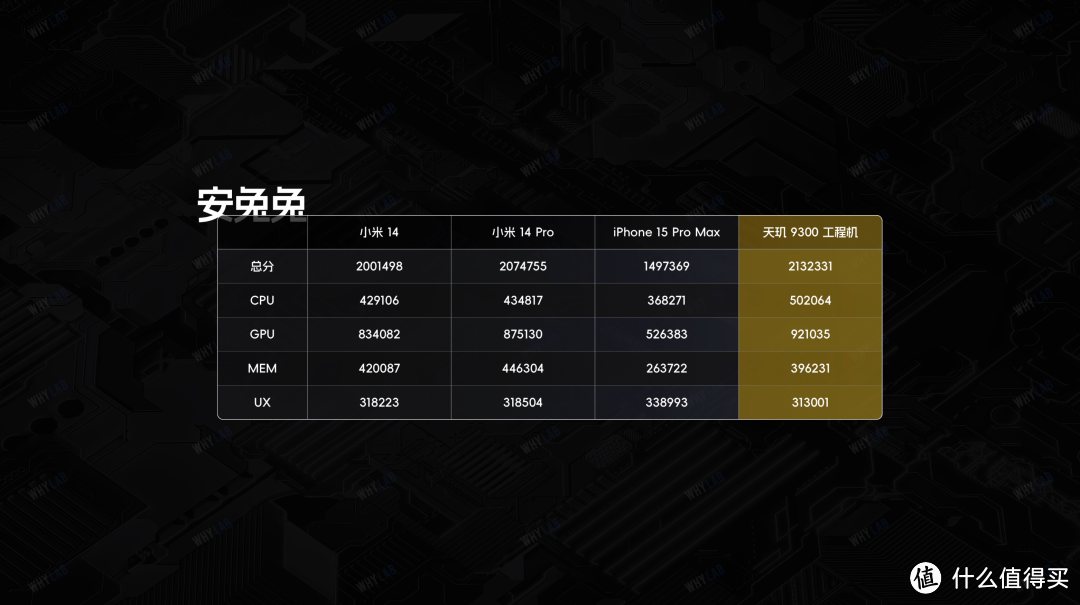
这样的成绩,你们满意吗?
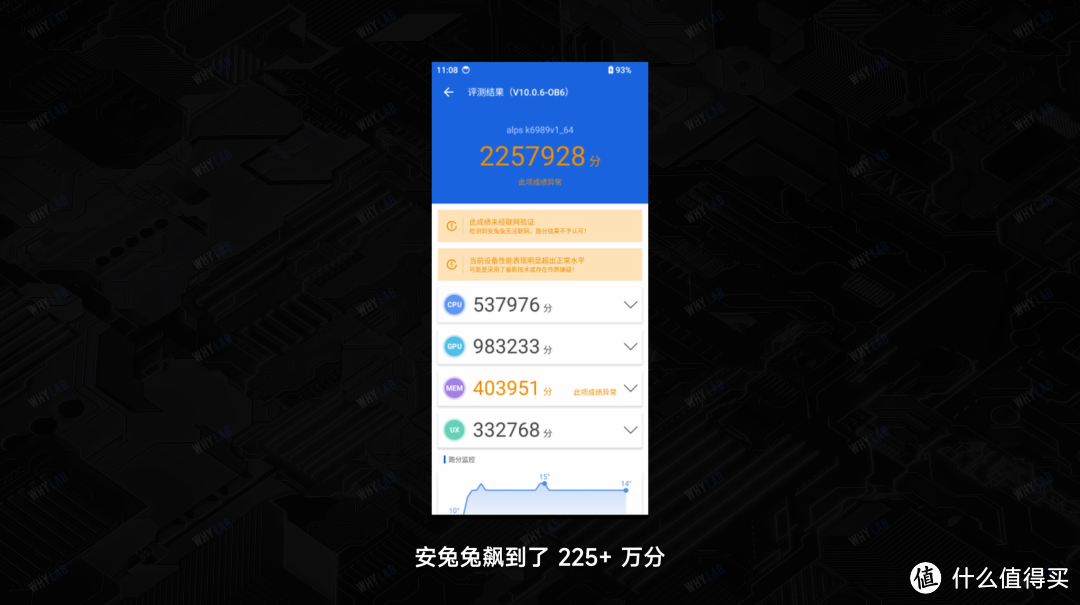
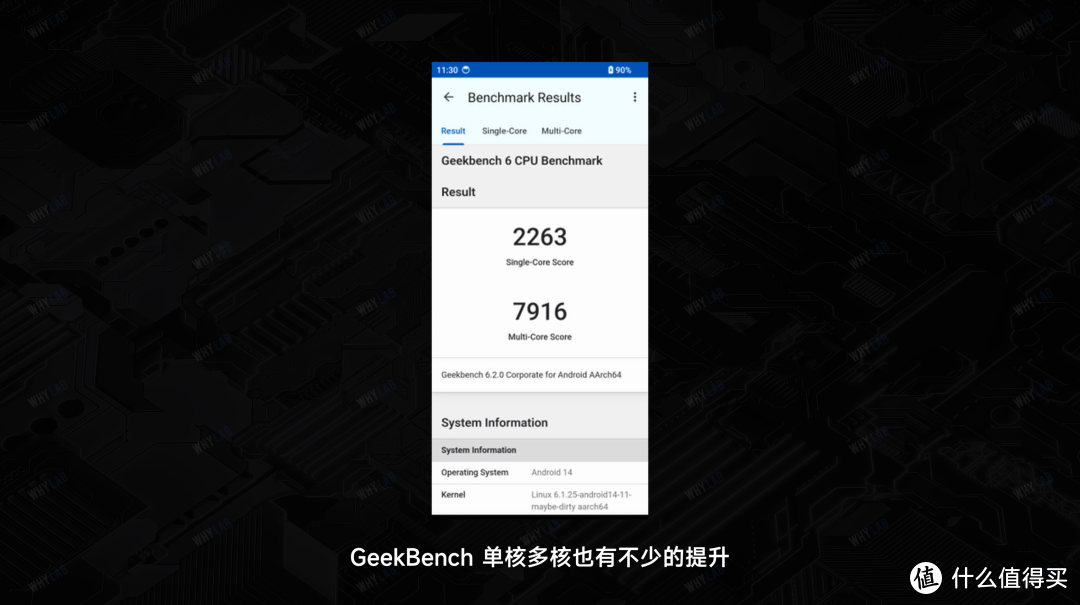
这些都是室内常温,不加外置散热跑出来的成绩哈。在我们的极限测试中,安兔兔飙到了 225+ 万分,GeekBench 单核多核也有不少的提升 —— 欸,不过 … 不过啊,这是比较极端的环境,完全不是日常使用环境,只是稍微探一下天玑 9300 的潜力有多少。
性能是上来了,但「全大核架构」需要面对一个问题,就是全面转向大核后,原本属于传统小核的轻度任务,就全权交由大核来处理了,考验大核低负载时的能效。
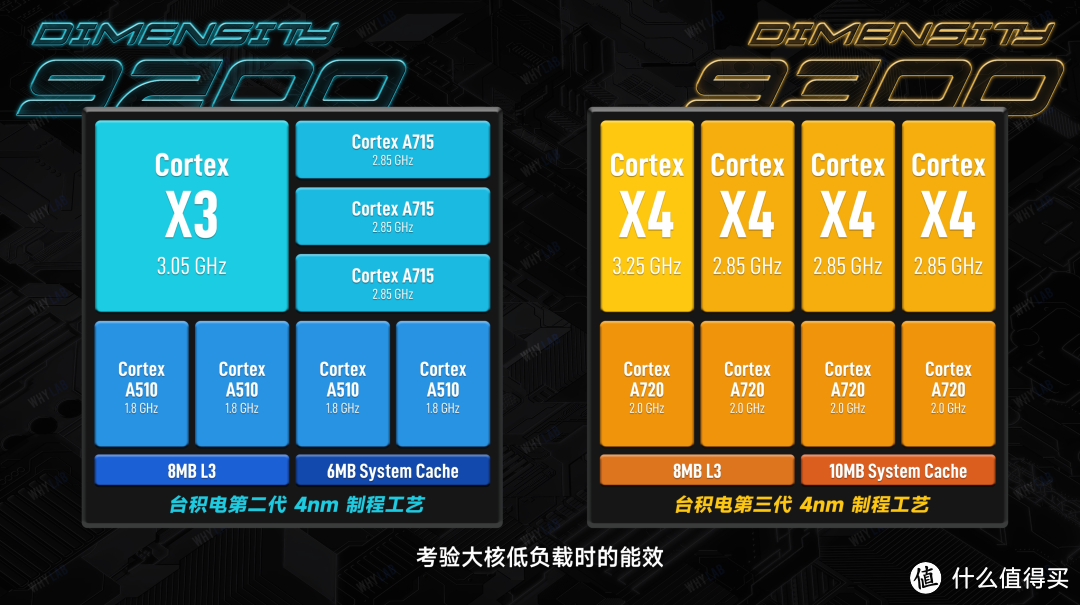
首先对比上一代,超大核心 Corte-X4 核心本身的性能是有大概 15% 提升的,在此之上功率还降低了 40%;大核 Corte-A720 这边也大概有 20% 的能效提升 —— 这是第一层。

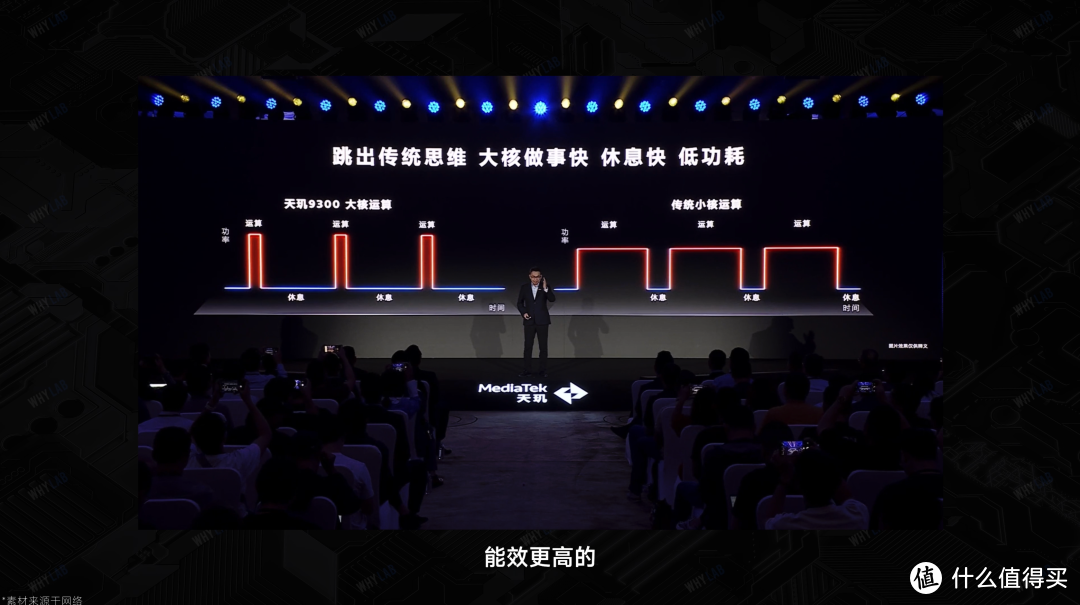
另外,大核因为它的性能优势,处理同一个任务的时候,往往做得比传统小核要快,任务结束后休眠也更快更深入,把时间拉长到整个任务的话,大核的总能耗其实是更低、能效更高的 —— 好比是一个薪资高,效率也高的打工人,站在公司的角度看,性价比可能要比两个低薪低效的员工要高。
还有,天玑 9300 这次用了乱序执行内核,对比起传统的顺序执行,分配到 CPU 的各项任务可以不用排队,有组织地「见缝插针」来执行,也提升了多线程的效率,进而再次提升核心的效率,效率高了,就有更多时间来「休息」,少耗电。
所以,联发科今天这套「全大核架构」,反而是可以提升能效比的,面对中、重载任务的时候,优势会比较明显,像日常浏览、看视频等等这些轻载任务,也有一个不错能耗控制 —— 总的来说,对比上一代,天玑 9300 在同等性能下会有 33% 能耗下降。
联发科先迈了一步,虽然说 CPU 的通用性很强,但整个 Android 的生态过于庞大,面对新架构可能还会有调度的问题,所以联发科也已经跟 Google 等厂商合作了,未来遇到的问题都是可以被优化、解决的;实际落地之后,我们还会再看实际具体使用场景的优化效果。
天玑 9300 CPU 的部分,总的来说,「全大核架构」其实是更有利于多任务处理的,这也是联发科认为未来手机终端最重要的一个特性,特别是未来折叠屏手机普及开以后,对多任务的处理需求会明显大增,像我们也体验了原神 60fps 和微信视频通话的双开,全程基本能满帧运行。

所以「全大核」,它也是一个「战未来」的架构,苹果的 A 系芯片其实已经是这条路了,未来,或者说是明年的移动旗舰 SoC,很大概率都走这条路了。
| AI
AI 也是这次天玑 9300 的升级重点,新的 APU 790 做了架构的更新,整数和浮点运算都分别比上一代提升了 2 倍,功耗还降低了 45%;还有 8 倍的 Transformer 算子加速、INT4 量化技术等等,就是为生成式 AI 来做提升的。

其实在手机做端侧生成式 AI 有不少需要解决的技术问题,首先第一个难点,参数量就是生产力,但背后的运存占用对手机来说是个大问题,举个例子,某个 130 亿参数量的模型,需要占有 13GB 的内存(INT8),即使是放到一台 16GB 的 Android 手机上跑,还有系统和其它 app 的运存占用,这 16GB 完全不够。

所以天玑 9300 这边的首款内存硬件压缩技术 NeuroPilot Compression,可以将这里的 13GB 运存压缩到大概 5GB 左右,大大解放了运存的占用。

另外端侧算力和运存有限的前提下,联发科用了一种「基础模型 + 技能扩展」的「1 + N」第一款支持 LoRA(Low-Rank Adaptation)融合的端侧技能扩充技术 NeuroPilot Fusion 来解决参数量的问题,就像先搭好基本框架,再安装可替换的个性化套件来做 AI,来满足手机这类较轻的端侧生成式 AI 的需求。
我也上手了几个端侧的生成式 AI Demo,这里主要看生成的速度。

也跑了针对 AI 的 BaseMark In-Vitro,3144 分,成绩也还算不错的,苏黎世的 AI Benchmark 跑分目前也是榜一的成绩。

关于生态,联发科还为这套 AI 平台提供了相应的开发套件 NeuroPilot,据说已经跟 vivo 完成了 70 亿参数的 AI 大语言模型落地,也第一次实现了 130 亿参数的 AI 大语音模型端侧运行。天玑 9300 也是第一个成功运行 330 亿参数 AI 大语音模型的移动芯片。

| 游戏
联发科是第一个把光线追踪技术搬到移动端 SoC 的芯片商,这次的天玑 9300,GPU 用了 Immortalis-G720 MC12,除了算力的提升、内核带宽效率的提升,还升级了全局光照光追性能,不久后会有不少主流的手游参与适配。

这次 GPU 的 GFX 跑分放这了,一句话总结,就是成绩挺出乎我意料的;
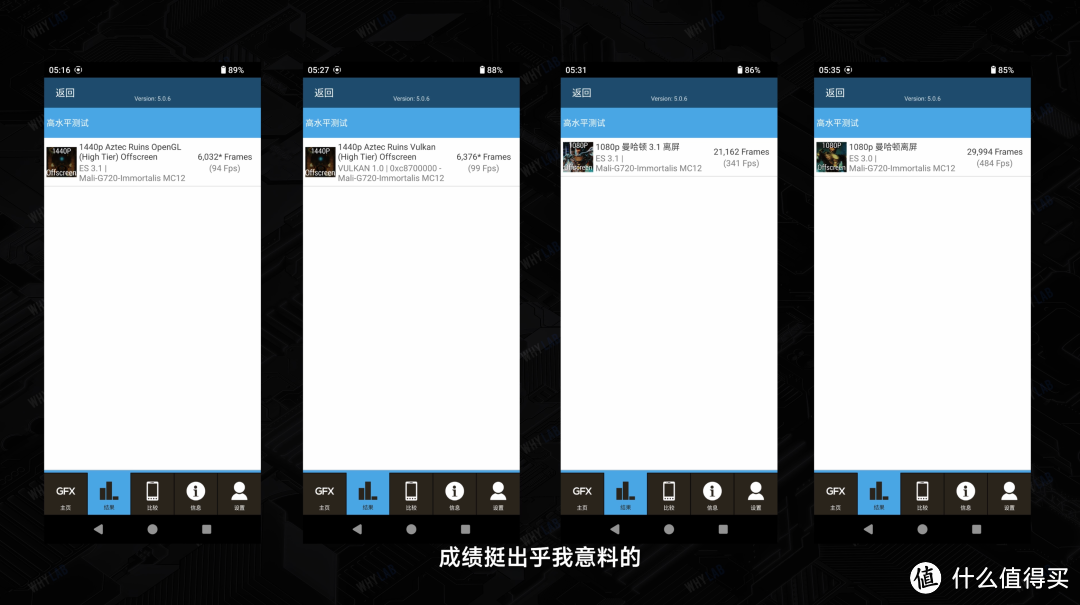
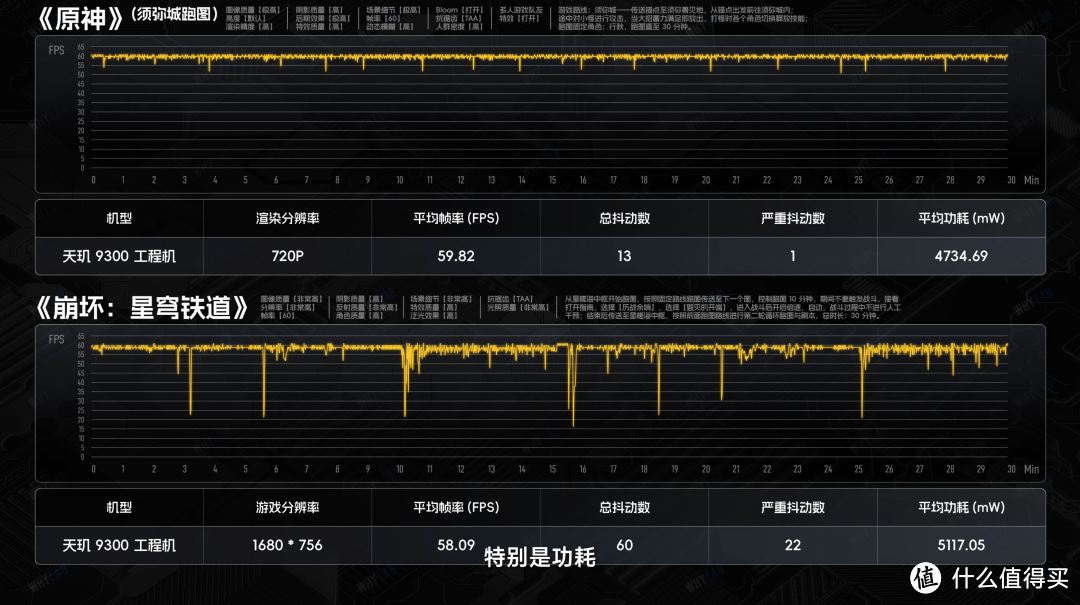
但实际游戏表现,我们还得看《原神》和《崩坏:星穹铁道》。

因为是工程机,表面温度跟我们量产机会很不同,所以这里就不看温度哈,星铁我们也没有抹除一些场景切换必要的瞬时掉帧,主要看帧率和功耗,特别是功耗,我对今年发哥的量产机游戏表现又有新期待了。
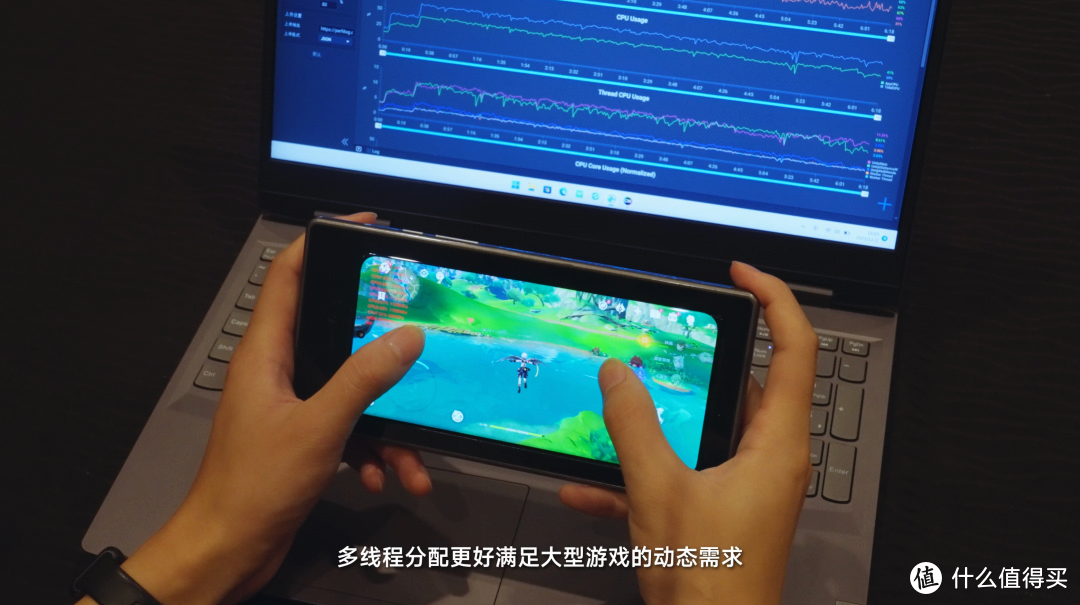
其实除了 GPU,背后也有全大核的 CPU 架构的一份功劳,多线程分配更好满足大型游戏的动态需求,这次也是天玑 9300 游戏功耗较低的原因之一。
| 总结
其实 SoC 是一个整体,不能拆开只看 CPU、只看 GPU 或者只看 APU,像游戏背后需要 GPU、CPU 的共同协作,AI 除了 APU,上层就是 CPU 的统筹和运存等等的配合。
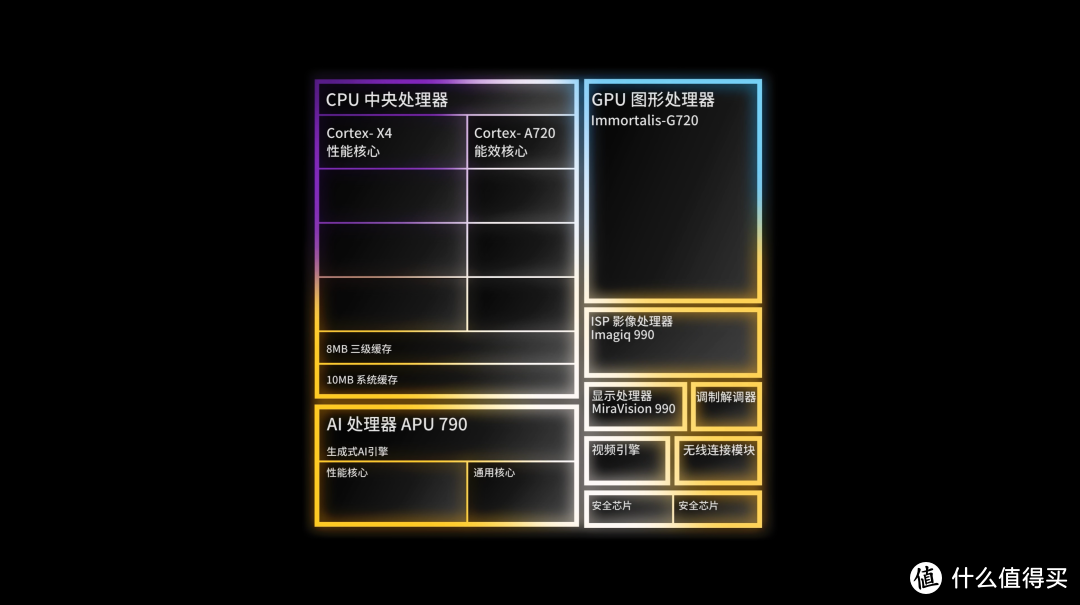
天玑 9300 这次 CPU 架构的改进,就是围绕这整块 SoC 的定位展开的,高性能、AI,还有低能耗。

对于消费电子而言,性能从来就没有「过剩」这么一说,产品都是跟市场互相成就的,消费者被软硬件的体验影响塑造了认知和需求,而厂商被用户的认知和需求推动着迭代和进化;联发科只是顺着他所看到的趋势先走出了一步,而我们目前通过工程样机看到的这一步,天玑 9300 走得还挺不错的。

对了,还有这次首发阵营 … … 你们最期待的是谁?

好了,这期天玑 9300 的性能测试与解析就是这些了,如果觉得对你有些帮助,欢迎关注点赞收藏转发,也别忘了到我们同名 WHYLAB 微信小程序去看看,这里是 WHYLAB ,咱们下期再见。
作者声明本文无利益相关,欢迎值友理性交流,和谐讨论~
















值友8770202581
校验提示文案
天天开心快乐365
校验提示文案
天天开心快乐365
校验提示文案
值友8770202581
校验提示文案