13
39
【科普】字节与编码
2020-03-16 14:12:56
0点赞
0收藏
0评论
本篇简单介绍下计算机相关的编码。
知乎上编程大神刘志军有句话这么说:「一旦走上了编程之路,如果你不把编码问题搞清楚,那么它将像幽灵一般纠缠你整个职业生涯,各种灵异事件会接踵而来,挥之不去。」由此可见,编码是基础但是也容易被人忽略的点。
让我们一起来看一下。
01 二进制与字节
众所周知,计算机内部采用的是二进制,即所有的数据都用0和1来表示,逢二进一。

这里每个数位(只能是0或1)叫做比特(bit)。用8个比特作为一个字节(byte),一个字节最多能有2^8=256种不同的表示。
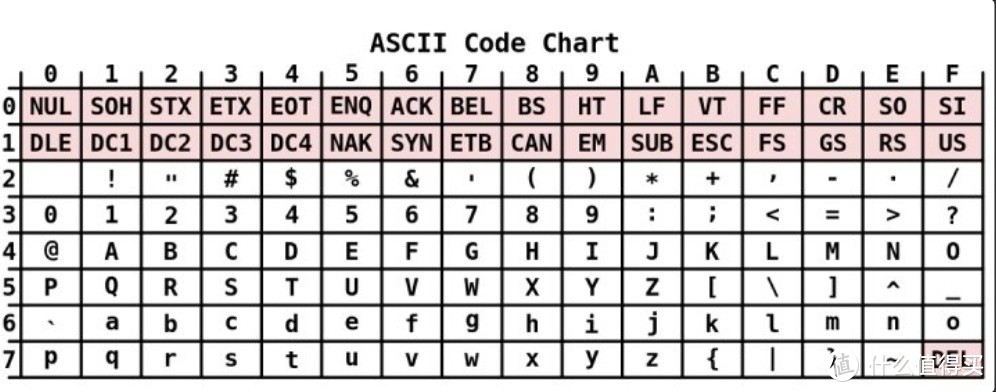
02 ASCII
计算机从最开始在美国发明出来时,到目前为止共定义了128个字符,包含英文字母、数字和常见的符号。这就是ASCII编码,用一个字节就足够表示。
03 Unicode
对于英文体系,一个字节足够表示,但是对于中文,成千上万个汉字用一个字节可不够用,如果中文用ASCII编码就会产生乱码。为了应对世界上纷繁复杂的语言,Unicode产生了,将所有语言统一成一套编码。常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。
如果ASCII编码转换为Unicode编码,将一个字节扩充为两个字节,在扩充的字节全部用0填充即可。
04 UTF-8
Unicode编码可以避免产生乱码的问题,但是会需要更大的存储空间。对于用ASCII编码就能表示的文本,如果用Unicode编码,则需要的空间会翻倍。这对于信息的存储与网络传输都是很不划算的。
为了降低成本,“可变长编码”的UTF-8编码应运而生。常用的英文字符被编码成1个字节,汉字被编码为3个字节。当文本中的英文很多时,使用UTF-8可以节省空间。
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
05 文本文档中的编码
下面我们来看看windows自带文本文档里的编码选项。

ANSI编码是一种对ASCII码的拓展:ANSI码仅在前128(0-127)个与ASCII码相同,之后的字符全是某个国家语言的所有字符。由于支持的字符没有Unicode多,所以可能会遇到下图这样的问题:

这时候转成Unicode可以正常显示。
UTF-8和Unicode的区别和上面讲的一样,文本中英文字符较多时,保存为UTF-8在网络上传输可以占用更少的网络资源。
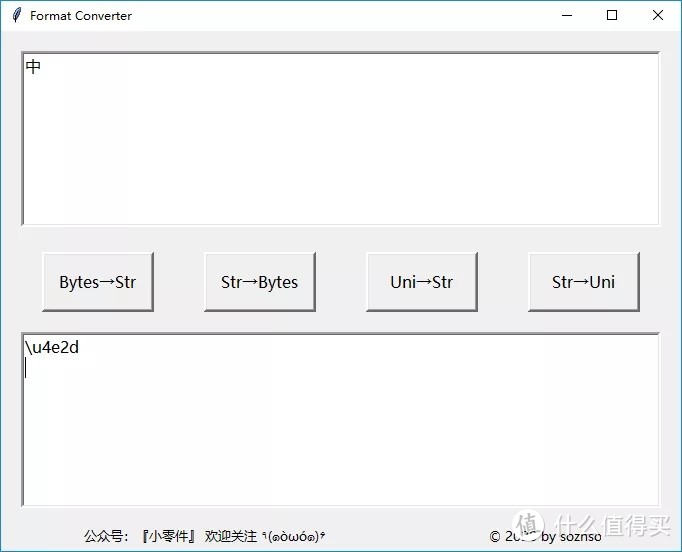
而对于剩下的Unicode big endian编码,以汉字“中”为例,二进制表示为01001110 00101101,Unicode码是4e2d,需要用两个字节存储,一个字节是4e,另一个字节是2d。存储的时候,4e在前,2d在后,就是Big endian方式;2d在前,4e在后,就是Little endian方式。
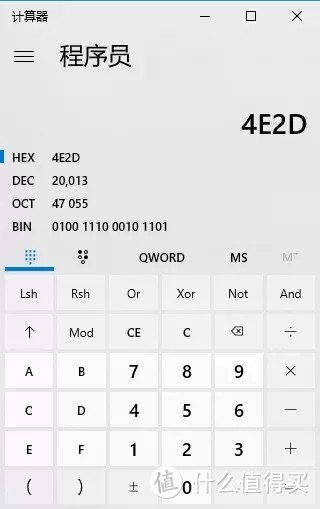
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
因此,第一个字节在前,就是”大头方式”(Big endian),第二个字节在前就是”小头方式”(Little endian)。
平时使用不用细究,当你在Unicode和Unicode big endian中纠结的时候,选用Unicode就行。
讲的比较入门,希望对大家能有所帮助,有不对的地方欢迎指出,谢谢~

延伸阅读
https://www.liaoxuefeng.com/wiki/1016959663602400/1017075323632896
廖雪峰的官方网站——字符串和编码
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
阮一峰的网络日志——字符编码笔记:ASCII,Unicode 和 UTF-8