























































130
78
i5-12600KF的AI新体验
2024-05-22 23:09:10
1点赞
4收藏
2评论
去年是大模型大火的一年,也发布了很多开源的大模型,其中有一些参数不大且通过量化技术,可以在8G或者12G现存的显卡上运行。但是,我们如果想跑没有量化过的大参数量的大模型呢? 而有一种技术就可以实现这个想法,那就是通过CPU来跑大模型。
这次我选择了国产开源的ChatGLM3这一大模型。它是清华开源的,他们去年就开源了chatGLM2,今年则升级到了ChatGLM3,扩充了多模输入和提升了token的字数。废话不多说,接下来看看12600KF与ChatGLM3的结合结果如何吧。
一 环境部署
1.下载ChatGLM3-6B的源代码
源代码既可以通过GitHub下载:https://github.com/THUDM/ChatGLM3
也可以通过国内的Gitcode加速下载:https://gitcode.com/THUDM/ChatGLM3
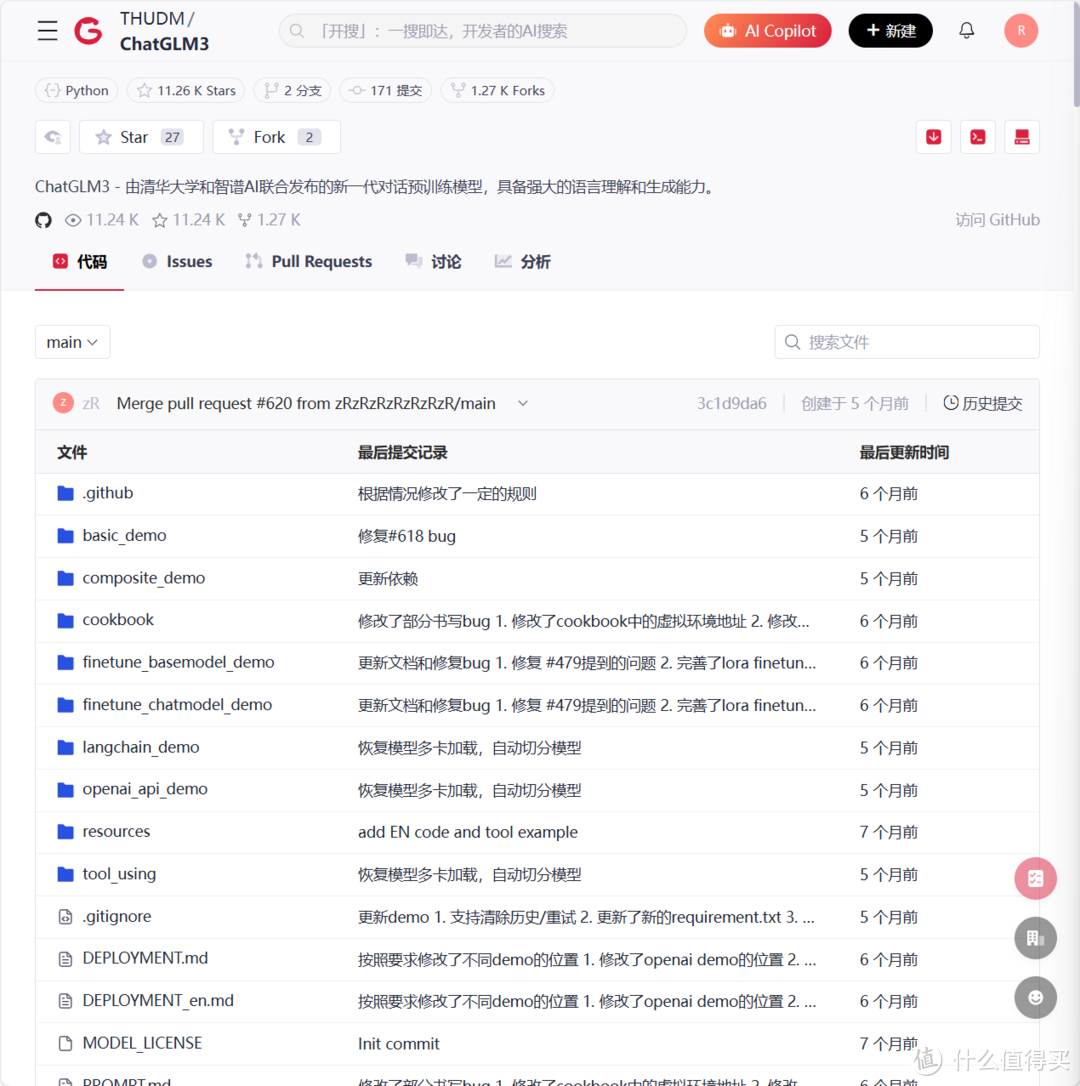
更推荐第二种方式,因为国内访问github总是存在各种问题。
这里下载的文件呢,主要是可以让你直接运行python文件,实现以API或者web网页的形式来访问大模型。其中web页面用的是Streamlit技术,可以轻松地将你数据挖掘的结果可视化,是个不可多得的好工具,感兴趣的小伙伴可以深入了解下。
2.下载ChatGLM3-6B的模型文件
模型文件下载也有两种途径,一种是传统的HuggingFace:https://huggingface.co/THUDM/chatglm3-6b
一种是通过ModelScope:https://modelscope.cn/models/ZhipuAI/chatglm3-6b
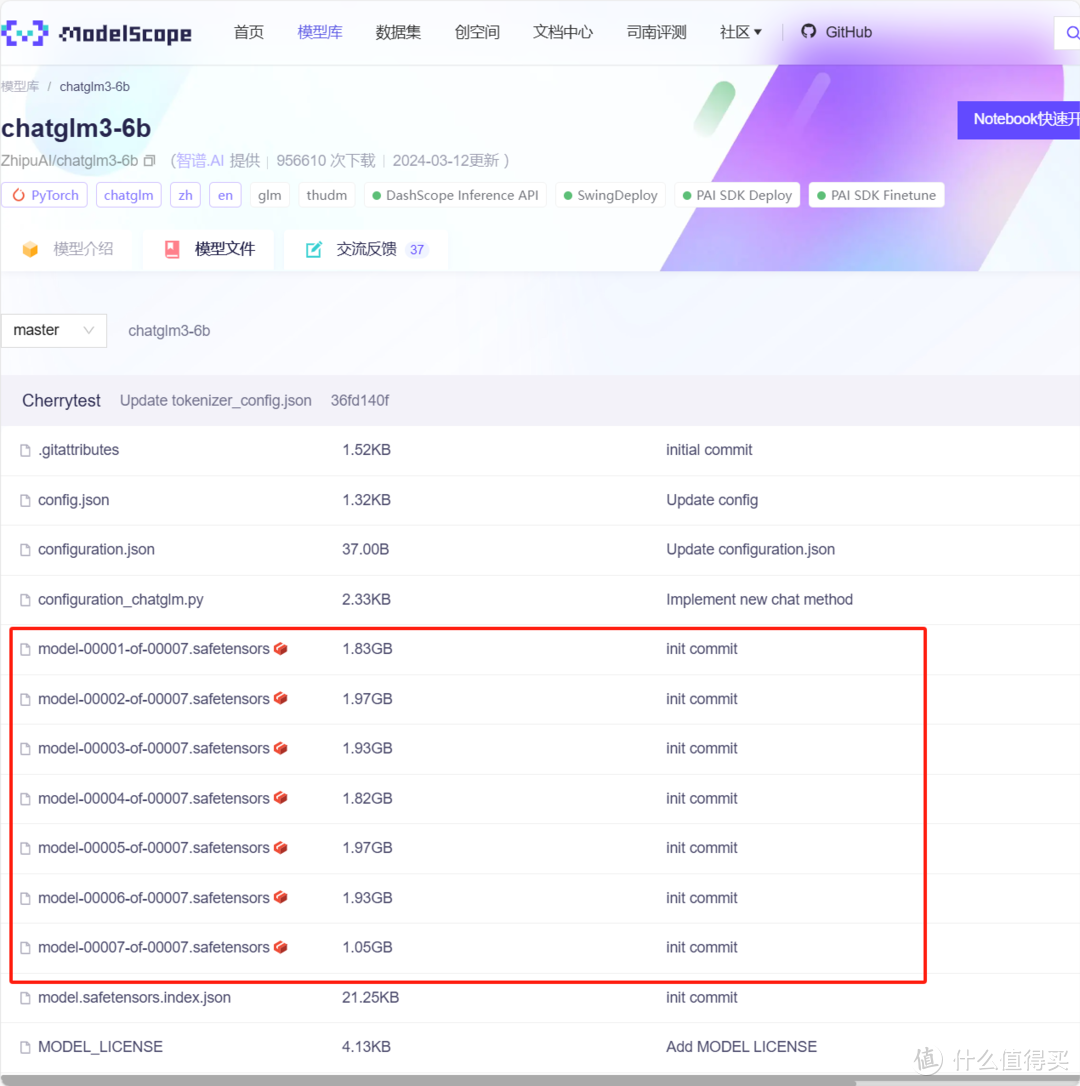
这里也是更推荐第二种,因为它在国内的访问不受限制,下载速度更快。这里面最重要的就是我框出来的接近2个G(大概率是2000M)的模型文件。葫芦娃七兄弟,一个也不能少。
3.安装Anaconda并配置虚拟环境,安装依赖包
Anaconda是一个很方便的工具,能够帮助我们快速构建和管理Python的虚拟环境。我们运行大模型,一般需要Python3.8甚至Python3.11的环境,而且需要安装大量的包,建议是为大模型单独配置其虚拟环境。
这里我选择Python3.9版本为基础创建虚拟环境。
conda create -n your_env_name python=x.x
#其中-n后面是虚拟环境的名字,python后面是你要的python版本
conda env list
#这是列出conda上面虚拟环境的命令
conda active your_env_name
#这是激活虚拟环境的命令,激活后的安装等操作都会在里面进行
4.安装C/C++编译环境
这一步主要也是为了后续安装和运行提供基础环境。我们选择到Download | tdm-gcc (jmeubank.github.io) 下载对应的安装文件。安装时记得勾选openmp即可。其他一路next即可。
安装完以后,可以到CMD中输入"gcc -v"验证是否安装成功。
ps.安装过程中如果还是要连接github,可以看这个网站,替换成最新的hosts试试:GitHub Hosts | hosts (ineo6.github.io)
5.安装Pytorch特定版本
进入Pytorch官网PyTorch,寻找对应自己CPU版本的安装文件,具体安装则需要进入到Anaconda虚拟环境里面,将Pytorch官网获取到的安装链接在虚拟环境下安装。
这里我们选择CPUonly的安装语句:
# CPU Only conda install pytorch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 cpuonly -c pytorch
6.安装其他依赖包
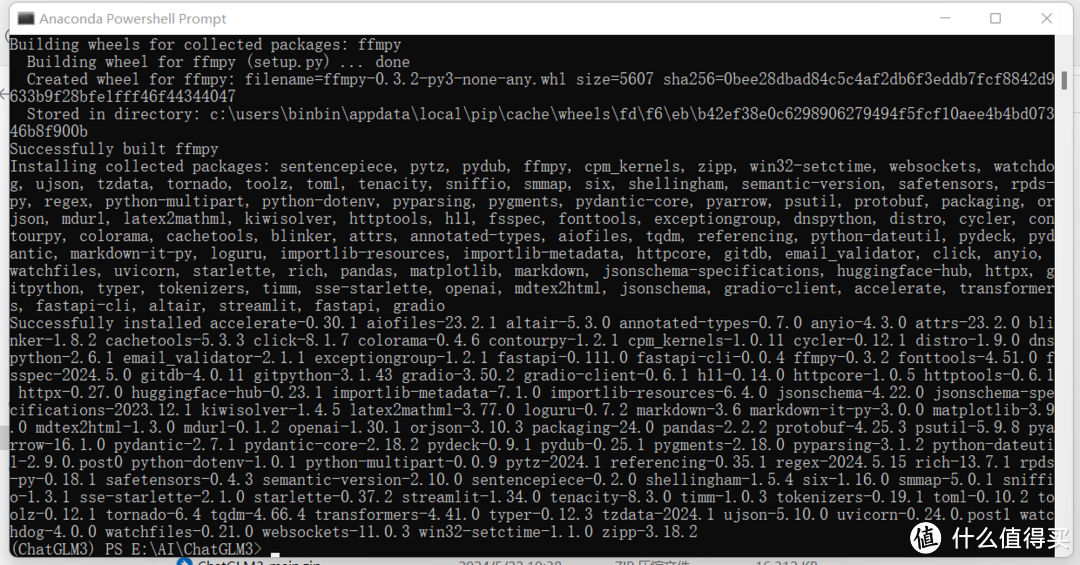
根据chatglm3-6b的工程文件夹里面的requirements.txt文件的要求,安装所需的各种依赖包。直接在Anaconda的控制台里面,进入工程文件夹路径,然后执行pip install -r requirements.txt命令就可以了。
ps.这里如果下载依赖包太慢,可以将anaconda的源换成国内的。anaconda | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 需要注意的是,改了源的镜像以后,记得重新启动Anaconda的控制台让配置生效,再进入自己的虚拟环境下安装依赖包。
二 模型运行
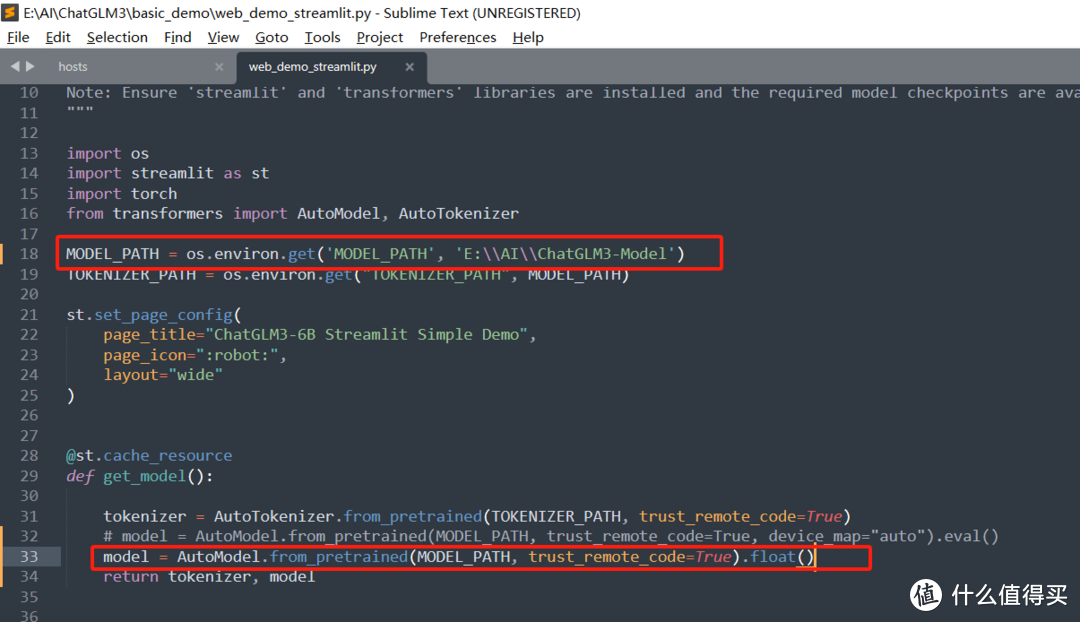
模型正式运行之前,我们需要去修改代码里面的MODEL_PATH,确保它指向咱们本地的模型文件夹。我们因为是用Streamlit运行,所以修改basic_demo文件夹下面的web_demo_streamlit.py文件即可。
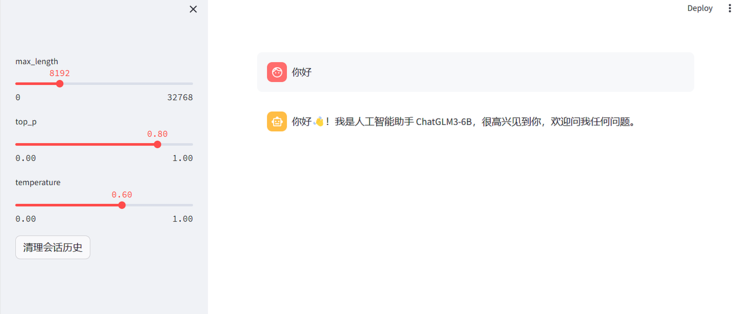
因为是streamlit运行,所以需要到anaconda虚拟环境里面执行streamlit run web_demo_streamlit.py命令即可。
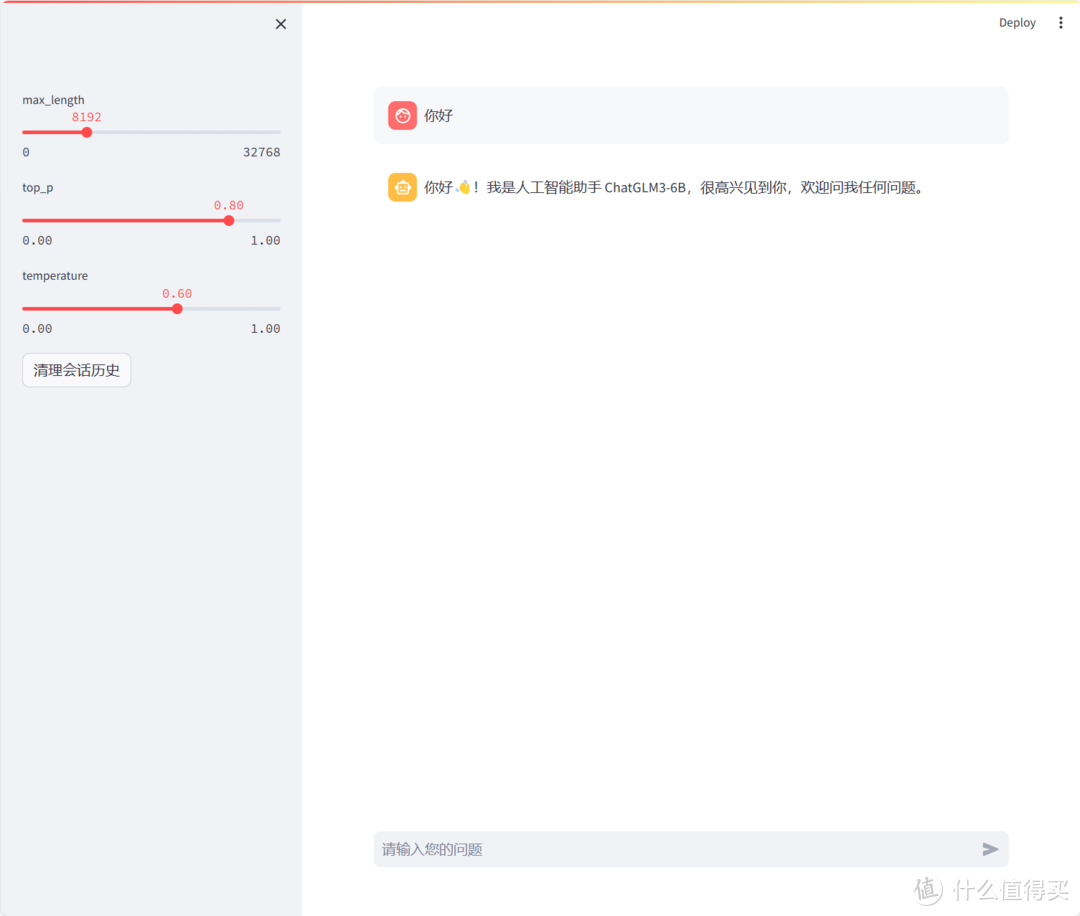
运行成功后会跳转到网页,等待模型加载完成后,就可以输入自己的问题啦。
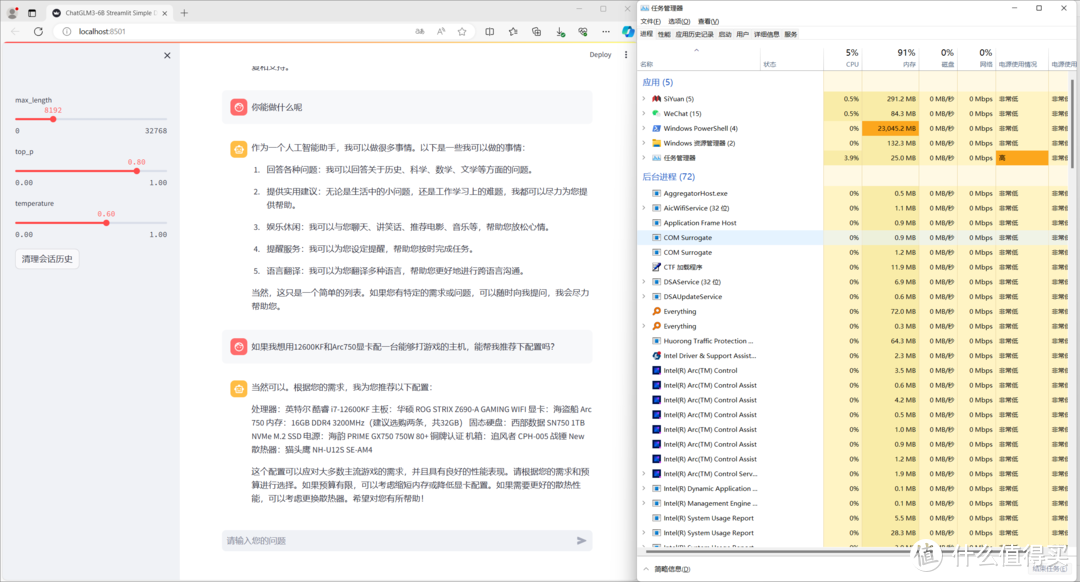
1.初始占用情况
不得不说,大模型文件是真的大,初始占用已经是30.8/31.8G了。当然这里面要剔除掉系统占用和其他开着的软件的占用。
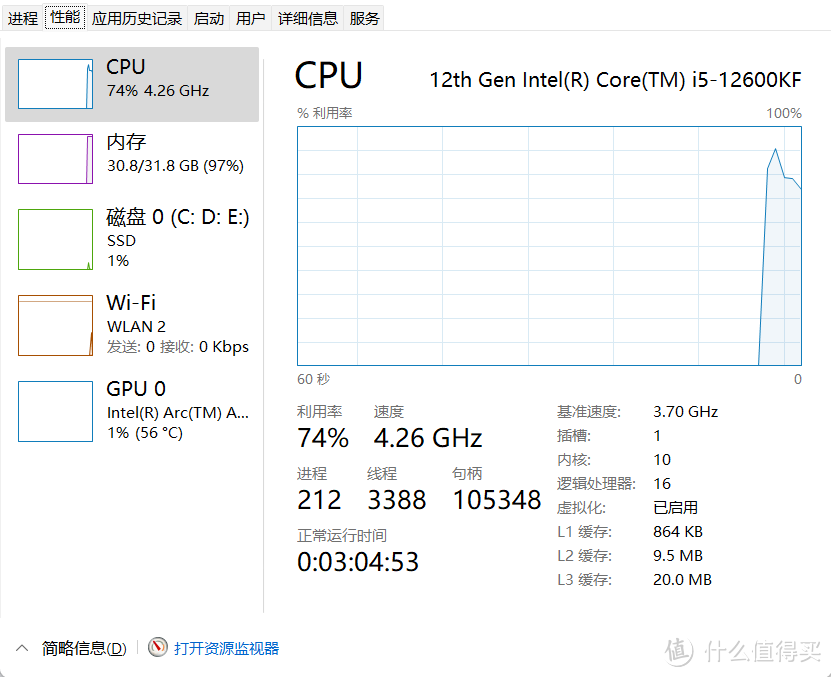
通过任务管理器可以看到,占用了约24G的内存。

但是响应很快,基本上4S就能获得想要的结果,当然,字还是一个一个往外蹦出来的,比不是在GPU上面部署的大模型的速度。但是这个表现,已经值得说一声12600KF YYDS了。
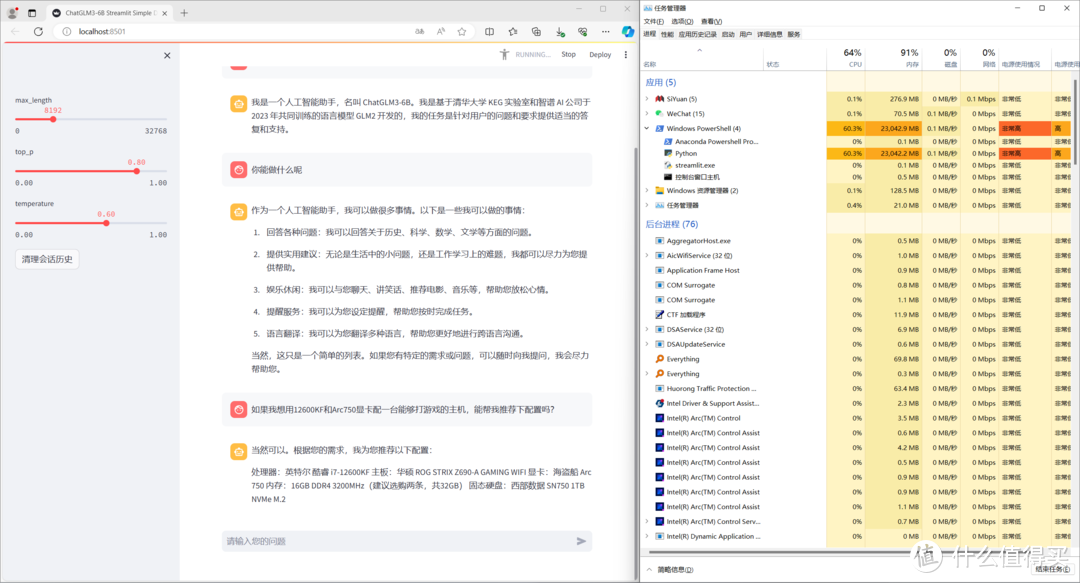
2.多轮回答以后占用情况
在回答问题时,大模型的CPU占用率一直在60%左右徘徊,占用的内容也是在24G左右徘徊,可以说是非常的稳定。同时,CPU的温度也稳定在80℃左右。不回答问题时,CPU占用率基本为0. 当然,因为模型一直加载在内存里面,所以内存占用没变化。
三 总结
用12600KF玩大模型,是完全可以部署并使用的。只是模型响应时间较长,而这也是CPU部署大模型的通病了。相较而言,12600KF的CPU占用不高,耗费内存较少,提出问题后能够快速响应,对于想要体验大模型私有化部署的朋友来说,也是一个很不错的体验哦。

















cwz1985
校验提示文案
cwz1985
校验提示文案